


Hi again.
Tomorrow (exact time) the Semifinals of IndiaHacks-Algorithms will start — link. You can participate only if you got any points in at least one of qualifiers. You will get 24 hours and 10 problems, including an approximation one to break ties. The submitting time doesn't matter unless you have a tie in an approximation problem (very unlikely).
In my opinion problems are unusually interesting. They were prepared by kostya_by, k790alex, and by me. Thanks for johnasselta and belowthebelt for helping me with testing and checking everything.
Top20 Indians advance to onsite finals. Top20 non-Indians advance to finals but will participate remotely, still fighting for prizes. Finals will happen somewhen in March.
I wish you great fun and no frustrating bugs. Looking forward to seeing you! Below, you can see prizes for top contestants in the final round.

WINNERS OF THE SEMIFINALS
And congratulations for all advancing to the final round. The unofficial list of advancers is in the comments below.







How can only 40 contestants will advance to final round and top 50 will get hackerearth Goodies?
I have no idea.
the same way as GCJ gives 1000 t-shirts having 26 finalists?
Exactly.
But here in the blog it's saying
so it's saying final round not semi final, so how can 50 contestants get prizes if there's only 40 total contestants ?
People, why you dislike this(↑) comment??
It's really correct and appropriate remark. There should be mistake and I also interested how organizers explain it.
EDT: Proof
May be prizes for final round, but goodies for top 50 in semifinal?
45 minutes to go. Good luck, everyone. :)
It started.
One hour left. Remember about subtasks and an approximation problem.
I started on the approximation problem with 40 minutes left. Almost 96 points.
My approach was the first thing that came to my mind when reading the problem: find the cycle greedily (random start), then choose the rest stops optimally using a DP. It got 94 points immediately.
I had about 3 hours left for approaching this problem (due to sleeping and taking a long time to solve "Bear and cookies" — which I couldn't let myself to abandon in favour of the approximation problem :), which in the end paid off). My approach was to start with a proper cycle (I used the MST approach for TSP for the starting cycle) and then try to improve this cycle as long as I had time (by choosing a new starting node along the cycle or by rewiring the cycle — i.e. cutting two segments of the cycle and reconnecting them differently). When computing the score for a cycle I, of course, considered the possibility of adding stops for resting. However, I only did this greedily during the contest :( (i.e. I only added a rest stop when the cost of traversing the segment without resting was larger than rest time + new cost of traversing the segment). The advantage was that this greedy approach was very fast (O(N)), so I could run lots of iterations to improve the initial solution. Somehow I didn't even think about the possibility of using DP instead of greedy for this part. As soon as I read your comment, though, it became obvious that I should have used DP here. So today I had some time to take my solution from the contest and replace the greedy part by a DP solution (with a worse time complexity, though — O(N^2)). This reduced the number of improvement iterations significantly, but the scores were much better. On my local tests I obtained a 22% improvement. Given that my score during the contest was about 73%, this change alone would have probably given me around 94%-95% of the best score. I couldn't test it by running on the official tests, because it seems that now scores are not reported anymore when submitting on Hackerearth.
So I have a question — can the DP be implemented faster? My DP essentially computed S(i,j) = the minimum score to reach the i^th node on the cycle with a fatigue equal to F0+j (if j=0 and i is not the first node on the cycle, then a resting stop took place there). I tried placing small upper bounds for j (e.g. force j <= 50 or j <= 250), but the score improvements were lower (despite running more iterations).
Before a contest I implemented a very simple version of the following idea. It gave good scores but worse than the greedy (go to the nearest) with DP. Though I believe that the more sophisticated version would be awesome here.
So, I thought about clustering the points into groups of size C — a constant depending on parameters r and f0 (something about 100 I guess). Of course, in smarter solution it wouldn't be the same for all groups. Dividing can be done e.g. in one of the following two ways:
Then, we can do some more adjusted search in each cluster — we don't want the shortest path, but the path with short edges at the end.
You ask if the DP can be calculated faster. Doesn't look easy. Though maybe some approximation approach makes sense. We know dp[1], d[2], ..., dp[a - 1] and we want to find dp[a]. Let's say that a moment ago it turned out that for a - 1 the best last interval was [a - k, a - 1], i.e.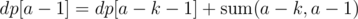 . Maybe it means that the size k is very reasonable size and for an interval ending in a. Then, to find dp[a] we should consider only dp[a - k - 2], dp[a - k - 1], dp[a - k], dp[a - k + 1], dp[a - k + 2] or something like that.
. Maybe it means that the size k is very reasonable size and for an interval ending in a. Then, to find dp[a] we should consider only dp[a - k - 2], dp[a - k - 1], dp[a - k], dp[a - k + 1], dp[a - k + 2] or something like that.
In your equation dp[a-1] = dp[a-k-1] + sum(a-k,a-1), does it mean that the most recent resting stop before a-1 took place at a-k-1? In other words, are you suggesting that maybe that distance (i.e. number of cities) between two consecutive resting stops is not too large? If yes, then this is exactly what I tried when I implemented the DP today. Optimal solutions can have large distances between two consecutive resting stops. I think I I got scores about 2%-3% worse if I limited this distance to something like 100-200, compared to not limiting it. But since the DP is faster, maybe the extra time could have been used to find better ways to improve the solution. Now that I'm writing this post, I realized that there is something I didn't try: to use an approximate DP (e.g. with limiting the distance between 2 consecutive resting stops) while doing iterative improvements and use a full DP once, at the end, on the best cycle found using the approximate DPs.
I hope I'm not saying bullshit, but it seems to me that this DP could be handled in O(N*log(N)) time. Once dp[a] is computed, it can be seen as a half-line with a slope F0 until a+1, then slope F0+1 until a+2, etc. This is essentially a convex function. And if at some point the convex function of some dp[b] (b>a) is better than the convex function of dp[a], then we can drop the convex function of dp[a] completely. To me this suggests that we can keep a deque of these functions and when we get a new function, we just remove some functions from the back of the deque. And when the function from the front of the deque "expires", we remove it from the front. If we can compute in O(1) time the intersection of 2 convex functions, then we should get an O(N) solution. I'm not sure how to do it in O(1) time, though, but it's easy to do it in O(log(N)) time (by using binary search), so at least an O(N*log(N)) solution seems doable. Am I missing something here?
"In other words, are you suggesting that maybe that distance (i.e. number of cities) between two consecutive resting stops is not too large?" — No. I suggest that if size k was optimal a moment ago (the most recent stop before a - 1 was at a - 1 - k), then when finding the most recent stop before a we should only consider sizes close to k, i.e. k - 2, k - 1, k, k + 1, k + 2 (or a bit more).
Your looks correct, nice. I didn't think about it before. I think I can do it in linear time. What we need is: for three functions A, B, C to check whether B is the best (lowest) for some x.
looks correct, nice. I didn't think about it before. I think I can do it in linear time. What we need is: for three functions A, B, C to check whether B is the best (lowest) for some x.
EDIT
You wrote that we need to find the intersection x of two functions in O(1) and I almost agree. For two intersections x1, x2 we must be able to compare them (which one is smaller) and nothing more. So, we don't have to find the exact values. For two fixed functions fi, fj I can find a real number s — the remaining suffix sum (on the right) if we considered a vertical line going through the intersection. We can calculate it quickly because as we move with a vertical line slowly to the right, and we decrease s by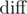 , then we change the difference between fi and fj by exactly
, then we change the difference between fi and fj by exactly 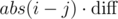 . Should I explain it with more details?
. Should I explain it with more details?
OK, yes, it makes sense. Basically, the x coordinate of the intersection between two such functions can be computed as if one of them is constant and the other one is a line with a fixed slope (because the slope difference between the two functions is always the same: abs(i-j)).
Editorials are published. What do you think about the problems?
In an approximation problem I expected more people to have the approach Xellos described. Does anybody see an easy proof for H? It took me long hours to prove it.
Later we will publish the list of people advancing to the final round.
Are you about problem Bear and cookies?
I think my solution is pretty straightforward (I mean it's easy to see why it's correct). What is your solution?
Yes, about Bear and cookies. I think that we have the same solution (by looking at your code). Let's make sure. We sort cookies by pair (bi, ai) decreasingly and then the dynamic programming. We should know which cookie we consider now and how many cookies on the right our opponent has taken before. Or how many on the left are non-taken, so he will take them.
If it's the same then could you tell me a few sentences about its correctness? Why it's not necessary to know which cookies on the right are taken?
Well, each time we decide whether to choose one(maximal) available in the current block or to give it up, so others seem to be irrelevant
Let's say the current block contains cookies with indices 12, 13, 14, 15, 16, 17, 18, all with the same bi. Right now we are considering a cookie 14 and it turns out to be non-taken. All cookies from [1, 13] are taken. We know that two more cookies from the current block are taken (two cookies from set {15, 16, 17, 18}). You are right that cookie 14 is the best choice among cookies from the current block. But do we really want it? Or maybe we should skip this whole block and go to the next one. Let's consider the following two situations.
Two taken cookies are 17 and 18. So, in the current block there are still a few valuable cookies (14, 15, 16). Maybe it's good to stay here a bit longer.
Two taken cookies are 15 and 16. Only cookie 14 is valuable. Maybe it's better go to the next block immediately.
Why is our decision the same, in these both situations?
Oh, I see what you mean, I didn't realise that.
It's not as trivial as I thought.
Good that I didn't think same way during the contest:D
Thank you for the editorials, the problems are very interesting even the easy problems have a bit tricky ideas and one may easily miss them and go for hard solutions
I really liked the problems from this contest. They had various degrees of difficulty and most of them required some non-trivial cleverness in order to solve them. And, more importantly, they weren't implementation-heavy (centroid decomposition was probably the most complicated technique from an implementation point of view, and that's still quite reasonable).
kingofnumbers, mugurelionut, thanks for the positive feedback. I also think that the quality was very good, so I want to once more thank the other authors — kostya_by and k790alex.
How to solve "**Shortest Path Recovering"** problem ??
My idea is to first select the random node from the given set S, let's say x, then calculate the shortest path of all nodes from x (using Dijkstra). Then, find the node having maximum distance from x which lies in S, let's say y. Then again we find the shortest path from this y node to all the nodes (also we keep track of the parent set needed to recover the shortest path from a given node).
Then using dfs we can find out the actual path starting from y'th node.
Above solution gives WA.
code: http://ideone.com/JWhnNH
I can't understand your code properly but are you sure the edges your dfs visits are included in a shortest path? I got AC with the same approach, just did the last part a bit differently (http://ideone.com/CtgFSg): I'm sorting the marked vertices by their distance from s (source vertex) and finding a path using bfs between each pair of consecutive vertices considering only those edges u - v such that d(v) = d(u) + len[u][v]. This ensures that the overall path will be a shortest path.
edit: Your code seems to fail on the following testcase:
line 130: I have ran Dijkstra from a particular node of given set S.
line 133: I find the node(var_name: other) which is at the maximum distance from start.
In Dijkstra:
line 66: If the relaxation are equal, I just added current node in nextNode's parent set.
line 69-70: If the relaxation is lesser, I just cleared the parent's set of nextNode and added current node.
ex: start -> a . . . -> other
Parent set of every node contains the possible parent node having same distance from source in Dijkstra.
line 149: I made a dfs call from the other down to start. As the resultant parent set forms a acyclic graph.
Inside dfs : I am filling mark_pa[] array which denotes the number of nodes lies inside given set S, down the tree traversal to start.
Inside _dfs:
Then using this mark_pa[] array, for every node I am selecting the child node having maximum mark_pa[] value.
Calling line 151: _dfs(other);
edit: The test case above is fixed (changed line 129 ['<' to '>']), but still getting WA on judge. Please help me out with more test-case @AnonymousBunny!
code: http://ideone.com/JWhnNH
Advancers' list?
The advancers will receive an official invitation from the HE team in a couple of days. The 'unofficial' list from the side of the organizers will be posted in a while. :)
The unofficial list of advancers. The 49-th place was enough for an Indian participant. The 23-th place was enough for a non-Indian participant. The 50-th place was enough for goodies.
non-Indian:
1. gennady
2. eatmore
3. Al.Cash
4. mugurelionut
5. mailromka
6. riadwaw
7. Stonefeang
8. Xellos
9. werevovk
10. vicissi
11. anta
12. ra16bit
13. alexostanin95
14. calvinleenyc
15. egor
16. ariacas
17. um.nik.22.96
18. HellKitsune
19. ganweiliang
20. mrho88
Indian:
1. tanuj3
2. djdolls
3. rajasvanjape
4. animesh25
5. adityashah1495
6. karanaggarwal
7. alecsyde
8. joyneelmisra
9. orange_99
10. sahil.grover.12532
11. sanchit_h
12. balajiganapathis
13. lalitkundu95
14. akash4983
15. nitin.rathor.520
16. venkat.chippada
17. debagnick
18. adityapaliwal95
19. trsriram
20. singhalpulkit
Goodies: 1. tanphatIs987, 2. rantd, 3. ramtararam13, 4. apiadu17a6, 5. Chmel_Tolstiy, 6. ctiseanu, 7. baian.saidolda, 8. w4yneb0t, 9. alexey4, 10. sunny2
Is the format of the final round already determined?
It's not determined but I can tell you what we think it will be.
The duration of 3 hours and standard acm-style rules — instant feedback on all tests, binary scoring (AC or not) and 20 minutes for incorrect submission.
And for sure onsite participants will be allowed to use the Internet and any prewritten code. Otherwise, remote participants would be in the better situation. Are there any more possible issues with participation both onsite and remotely?
The online participants can cheat more easily, so they're still at an advantage. Not that the expected levels of online and Indian participants aren't far enough for it to be necessary :D
Any chance for Java 8 in time for finals?
As for me, the problems were interesting, but I must say that I have definitely seen the problem about recovering the shortest paths somewhere before. Anyway, thanks for the authors, and especially for the problem about paths in a tree. One more moment: what is the reason to set such a low stack size in C++? I understand that we can use some function to increase it, but anyway what's the matter to require it from the participants?
It's a bug, not a feature. I found out about low stack limit only a few days before a contest. They compile programs without flag
--stack=BIG_NUMBER. It was to late to change it but I hope it will be done before the finals. It's still a new platform and it improves every week — e.g. half a month ago they introduced LaTeX.Oh, then I must propose them to change the format of submitting solutions from a file. As far as I understood, the current situation is that I have to refresh the page before submitting the solution from a file next time, otherwise the system takes code from the editor.
btw is it possible to change default language?
currently I have to change c to c++ each time
Has anyone received any email(s) regarding the finals or any prizes?
AFAIK the C++ stack size is already increased. Java 8 should be available in the finals (no guarantee here). Choosing the default language should be available in the finals (no guarantee here).
Now some sure info. In the finals you will get 5-8 problems to solve in 2-3 hours. Standard acm rules (binary scoring, 20 minutes penalty).
I don't think the HackerEarth will contact you about prizes right now because prizes are for the finals (ok, and 10 extra t-shirts). But are there any participants from India who advanced and who weren't contacted about the finals? This one may be urgent.
Hi, thanks for promising news
Is date already known (at least approximately). Please let us know when it is.
March, 19-th (Saturday). For Russia it should start before noon. We didn't fix the exact hour.
Thanks for information.
Unfortunately it coincides with Hashcode:(
I think we can do nothing about it, sorry.
**it happens
although we'll be grateful if you start contest as early as possible :)
In case of some contestant declines his invitation to the finals. May be substitutes from short list are possible.
IndiaHacks update: We found that 11:00 to 14:00 IST on 19th of March is the ideal time slot for both CROC and Google Hash Code participants.
Is the official list of finalists out?
What happened to top 50 getting HackerEarth "goodies"? Did anyone receive anything?
Nope.
How would they send the goodies? Did they even ask for the Shipping Address?
Nope.