


Спасибо всем участникам нашего соревнования за множество успешных посылок по задачам!
Этот комплект для вас подготовили: snarknews, Chmel_Tolstiy, Gassa, Zlobober. Разбор для вас подготовили snarknews и Gassa.
Задача А. Буквы адреса
Поскольку множества гласных и согласных не пересекаются, при лексикографическом сравнении раньше будет та последовательность, которая начинается с буквы, которая раньше идёт в алфавите. Так что просто идём по строке, запоминаем первую гласную и первую согласную, которая нам встретилась. Как только встретились обе, сравниваем и немедленно выдаём ответ. Необходимо не забыть про случай, когда одна из строк пустая.
Задача B. Байтландский талер
Считываем первый обменный курс, инициализируем считанным значением переменные 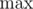 и
и 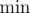 . Затем в цикле считываем N - 1 оставшихся курсов. Если курс больше , присваиваем считанное значение переменной , если курс меньше — переменной .
. Затем в цикле считываем N - 1 оставшихся курсов. Если курс больше , присваиваем считанное значение переменной , если курс меньше — переменной .
Ответ равен  .
.
Задача C. Шашматы
Так как чёрная шашка каждый ход уменьшает номер горизонтали, то всего шашка может сделать не более 7 ходов, на каждом ходу у неё не более двух вариантов выбора. Соответственно, конь тоже может сделать не более 7 ходов (даже если конь ходит первым, то, если шашка сделала 7 ходов, она дошла до первой горизонтали и игра заканчивается победой чёрных, то есть восьмого хода коня не происходит). Итого получаем не более 27·87 = 228 вариантов.
Все эти варианты можно за отведённое время перебрать рекурсивно. Для этого реализуем две функции:
функция хода шашки, которая проверяет условия выигрыша/проигрыша на данном ходу (то есть что шашка достигает после этого хода первой горизонтали, берёт коня или же оказывается "запертой"), если ни одно из этих условий не выполнено, то вызывается функция хода коня для всех возможных вариантов хода шашки;
функция хода коня, которая проверяет условия выигрыша на данном ходу (то есть что конь может взять шашку), если соответствующее условие не выполнено, вызывается функция хода шашки для всех возможных ходов коня (которых не более восьми).
В основной функции считываются данные и в зависимости от того, кто ходит первым, вызывается функция хода коня или функция хода шашки.
Задача D. Город в пустыне
Рассмотрим диагональ выпуклого пятиугольника. Одна из вершин лежит по одну сторону этой диагонали, две по другую и две лежат на этой диагонали. Первая вершина, соединённая диагоналями с двумя вторыми, даёт две точки пересечения, лежащие на выбранной диагонали. Остальные четыре вершины образуют выпуклый четырёхугольник, одной из сторон которого является исходная диагональ. Соответственно, точки пересечения остальных диагоналей пятиугольника (это точка пересечения диагоналей четырёхугольника и точки пересечения отрезков, соединяющих точки на одной из сторон с вершинами, с диагоналями четырёхугольника) лежат внутри четырёхугольника. Получаем, что точки пересечения диагоналей, не лежащие на данной диагонали, находятся от неё с одной стороны. Тем самым точки пересечения диагоналей выпуклого пятиугольника должны быть вершинами некоторого выпуклого пятиугольника D (сторонами которого являются отрезки диагоналей).
В этом случае исходные вершины восстанавливаются как точки пересечения прямых, содержащих несмежные стороны пятиугольника D. При этом точка пересечения каждой пары сторон должна существовать (то есть стороны не должны быть параллельны) и лежать по разные стороны с вершинами пятиугольника D относительно прямой, которая соединяет вершины сторон соответствующей пары (это следует из выпуклости исходного пятиугольника). Легко увидеть, что, если все эти требования выполняются, то восстановленный пятиугольник является выпуклым.
Тем самым решение состоит в построении выпуклой оболочки заданных точек, проверке, принадлежат ли все 5 точек выпуклой оболочке, и проверке для каждого i, существует ли точка пересечения прямых AiAi + 1 и Ai + 2Ai + 3 и лежит ли она по разные стороны с точкой Ai (или любой другой из трёх оставшихся точек) от прямой Ai + 1Ai + 2 (сложение в индексах производится по модулю 5). Если какая-то из проверок не прошла — ответ No, иначе ответ Yes.
Задача E. Кодирование
Если найти соответствующие p и q невозможно, то f(x) — перестановочный многочлен по модулю 2m (то есть он переводит последовательность из целых чисел от 0 до 2m - 1 в какую-то их перестановку).
Рассмотрим некоторые свойства перестановочных многочленов.
Если m = 1, то сумма всех коэффициентов, кроме свободного члена, обязана быть нечётной. Иначе f(0) = a0 и f(1) = a0 + (a1 + a2 + ... + an) имеют одинаковый остаток от деления на 2, и многочлен перестановочным не является.
Если многочлен является перестановочным по модулю 2m, то он является перестановочным и по модулю 2m - 1. Пусть это не так, тогда существуют два таких числа p и q (0 ≤ p, q < 2m - 1), которые дают одинаковые остатки f(p) и f(q) от деления на 2m - 1. Рассмотрим числа p, q, p + 2m - 1 и q + 2m - 1. Значения f(p + 2m - 1) и f(p) имеют одинаковые остатки от деления на 2m - 1: вычтем полиномы друг из друга и заметим, что разность делится на 2m - 1. Аналогично сделаем для f(q + 2m - 1) и f(q), то есть получаем четыре числа f(p), f(q), f(p + 2m - 1), f(q + 2m - 1), которые дают различные остатки от деления на 2m и одинаковые — на 2m - 1. Но таких чисел может быть не более двух. Противоречие.
Если многочлен является перестановочным по модулю 2m и m > 1, то a1 нечётно. В самом деле, пусть a1 чётно. Тогда берём p = 0 и q = 2m - 1. Легко видеть, что f(q) = a0 + a1·2m - 1 + a2·22m - 2 + ... + an·2nm - n = f(0) + (a1 / 2)·2m + 2m·r, где r — целое число (так как при m > 1 k(m - 1) - m ≥ 0), тем самым f(p) и f(q) дают одинаковые остатки от деления на 2m, что противоречит свойствам перестановочных многочленов.
Рассмотрев примеры для m = 2 и m = 3, можно заметить, что у перестановочных многочленов сумма коэффициентов при чётных степенях оказывается чётной. Это утверждение верно и для более высоких m; более того, перечисленные свойства являются необходимыми и достаточными. Полное доказательство можно найти в англоязычной статье Ronald R. Rivest.
Таким образом, всё, что вам нужно — это проверить, что сумма a1 + a2 + a3 + ... + an нечётна, и что при m > 1 к тому же a1 нечётно, а сумма коэффициентов при чётных степенях чётна. Если эти требования выполняются, то ответом будет No (то есть многочлен перестановочный, и требуемых p и q найти нельзя). Иначе ответ — Yes.
Задача F. Плейлист в будущем
Вначале найдём множество K вершин, принадлежащих к одной компоненте сильной связности, для которых верно следующее свойство: не существует ни одного ребра, которое начинается в вершине, принадлежащей этому множеству, и заканчивается в вершине, ему не принадлежащей.
Из ограничений задачи видно, что такое множество можно выбрать единственным способом, и оно будет содержать вершину 1. Найти это множество можно, например, поиском в глубину, начиная с вершины 1.
Очевидно, что после 102016 проигранных композиций вероятность исполнения композиции извне этого множества можно при требуемой в задаче точности считать нулевой (а 102016 — бесконечным количеством итераций).
Вектор вероятностей p после бесконечного количества композиций должен удовлетворять системе линейных уравнений pW = p, где W — матрица смежности подграфа, построенного на вершинах из множества K.
Таким образом, мы имеем однородную систему уравнений (WT - I)pT = 0 и нормирующее уравнение 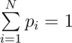 . Довольно просто можно показать, что система всегда будет совместной; система может быть решена, например, методом Гаусса.
. Довольно просто можно показать, что система всегда будет совместной; система может быть решена, например, методом Гаусса.
В качестве ответа в таком случае надо взять p1.
P.S. Если вы заметили опечатку сообщите мне об этом личным сообщением.







Я впервые участвовал в Яндекс Алгоритме, потому у меня вопросы: 1) Чем отличается зеленый плюсик от галочки в результатах 2) Где-то написано что я прошел/не прошел Спасибо
Привет,я вчера тоже опробывал впервые платформу Яндекс.Контест и за
время участия стал немного догадываться насчёт того,за что "+",а за
что "галочка" сделал следующие выводы:
"галочка"ставится за определённую задачу,если решение к этой задачи
была сдана в форме "в тёмную" и само решение прошло все тесты с
вердиктом:OK.
"+"ставиться за определённую задачу,если при сдаче решения вы указали
форму "в открытую" само решение прошли все тесты с вердиктом:OK.
Андрей совершенно прав, подробно разница между плюсиком и галочкой описана в правилах
На главной странице, если вы авторизованы, должно быть сообщение о том, что если вы решили хотя бы одну задачу, то мы ждем вас в отборочном этапе!
"При сдаче «в открытую», время решения задачи считается в секундах от начала соревнования до момента отправки правильного решения, плюс 20 штрафных минут за каждое непринятое решение."
В секундах или всё-таки в минутах?
В минутах
Извините, наверное я совсем глупый, но подскажите пожалуйста, как узнать я заполнил форму или нет и где ее увидеть? У меня есть кнопочка регистрация, но насколько я понимаю так как я участвовал и мне даже написало что я прошел в отборочный раунд я таки регистрировался, но где анкета которую можно менять? (например в 6 графе правил про стажерское соревнование написано что я могу менять галочку, где? Спасибо
Auto comment: topic has been translated by Chmel_Tolstiy (original revision, translated revision, compare)
В задача F не нужно искать компоненту сильной связности, можно вместо неё использовать множество всех вершин.
Насчёт задачи:B.Байтландский талер,то хочеться спросить:
А разве нельзя было решить следующим образом:
1.Прочитаем последовательность чисел во входных данных,во второй строке.
2.Отсортируем массив в порядке возрастания.
3.И уже ответом на эту задачу будет разность последнего элемента в массиве и первого элемента в массиве,т.е:mass[mass.length-1] — mass[0].
Можно, разница только в сложности алгоритма. На самом деле, достаточно знать минимальный и максимальный элементы, поэтому сортировать все данные нет необходимости.
Auto comment: topic has been updated by Chmel_Tolstiy (previous revision, new revision, compare).
А как понять, что в задаче F Гауссу хватает точности?
Никак :(
Я достаточно долго изучал этот вопрос, поспрашивал разных людей (в том числе, знакомого, занимающегося случайными процессами). Утверждается, что Гауссом действительно никто стационарные распределения не ищет, но привести пример, когда он бы работал достаточно плохо, никто не смог.
Я отношения к подготовке этой задачи не имел, если что, и как именно там устроены тесты я не знаю. На случайных тестах и всех тестах, которые пробовал я, ответ находится и даже устойчив к малым возмущениям в инпуте.
Когда-то давно я решал похожую задачу, и там Гауссу не хватало точности http://acm.timus.ru/problem.aspx?space=1&num=1766
Хотя может я не умел тогда писать Гаусса...
Вопрос по поводу решения задачи C.Шахматы Мы перебираем все варианты. Но могут будут варианты, где победили чёрные и где победили белые. В задаче говорится — что игра обоих игроков оптимальная(наилучшая) Не очень понятно — как выбрать: кто победил, если в переборе были оба варианта?
Например: чёрные D4, белые C4 Ходят первые чёрные — нетрудно видеть, что в переборе будут варианты, где победили белые и где победили чёрные.
Это классический вопрос — кто выигрывает при правильной игре. Вкратце — если игрок выигрывает при правильной игре, значит, у него есть стратегия, которая на любые ходы другого игрока умеет отвечать так, чтобы в итоге выиграть.
Понятно, спасибо!
Ребят, добрый день! Может быть я чего-то не понимаю со второй задачей?
Я писал на Java. Написал текст, который вряд ли может быть проще:
Пока есть число на входе, считать его, сравнить с максимумом и минимумом, и присвоить по необходимости новый максимум или минимум. При этом новое считанное число кладётся в ту же переменную current, без запоминания всех увиденных элементов.
У меня это решение постоянно зависает на 7-м тесте с сообщением "Превышен лимит времени выполнения" TL (time-limit-exceeded), поскольку на этом тесте программа работает дольше 1 секунды. Скажите, как можно этот код сделать ещё проще, чтобы пройти этот 7-й тест? Спасибо!
Проблема в способе чтения из файла. Scanner читает слишком медленно, нужно использовать буферизированный ввод.
Напишу мой код на всякий случай:
Первые 6 тестов выполнены за 80-90 мс, занимая рекордно низкие 7.63-8.12 Мб памяти. Последний 7-й тест очень длинный — у меня при обрыве исполнения оказывается занято 124.75 Мб, и это ещё очевидно не весь вход. Хотелось бы как-то ещё улучшить. Возможно, люди писали на С++ эту задачу и потому без особых проблем её прошли, но я уверен, что и Java может нормальную производительность показывать. Подскажите, пожалуйста, если кто в курсе.
br.readLine().split(" ")думаю это тормозит. Дефолтное олимпиадное считывание — засунуть эту строку (т.е.br.readLine()) вStringTokenizer, а потом оттуда по одному токену доставать.точно! спасибо большое :)