


На олимпиаде Казахстана прошлого года была задача "Количество совместимых чисел", которая сводится к такой: даны 22-битные маски a1, a2, ..., an (n < 106), нужно посчитать d[m] — количество таких i, что a[i] является подмаской m (т.е. a[i] & m == a[i]).
Официальное решение решает эту задачу так:
for (int i = 0; i < n; i++) {
d[a[i]]++;
}
for (int i = 0; i < 22; i++) {
for (int mask = 0; mask < (1 << 22); mask++) {
if ((mask & (1 << i)) == 0) {
d[mask | (1 << i)] += d[mask];
}
}
}
Пытаясь решить эту задачу самостоятельно, я дошёл до этой идеи, но сразу отбросил, потому что мне показалось очевидным, что она какие-нибудь подмаски будет считать несколько раз. Сейчас я вроде бы почти убедил себя, что этого не происходит, но у всё ещё меня нет интуитивного понимания того, почему это должно работать. Может, это какой-то известный трюк, которого я не знаю? Или может просто кто-нибудь может объяснить логику этого подхода?
Спасибо!







Можно сказать, что дело в порядке циклов.
Пусть мы хотим получить маску
s. Рассмотрим её биты по порядку (внешний цикл поi). Для каждого битаi, если он единица, сделаем переходd[mask | (1 << i)] += d[mask];. Если он ноль, переход не происходит. Например, маска13(двоичная запись1101) получается единственным способом:i = 0по переходуd[1] += d[0],i = 2по переходуd[5] += d[1],i = 3по переходуd[13] += d[5].Если бы порядок циклов был другим — внешний по
maskи внутренний поi— действительно, каждая маска с x единичными битами получилась бы x! способами: биты могли добавиться в любом порядке.Что именно значит «маска
13получается единственным способом»? Ведь, например, приi = 0, выполняется также иd[13] += d[12]Имелось в виду, что у каждой маски ровно один путь, по которому она может пройти к конкретной надмаске, насколько я понял. Кажется, именно это мы и хотим доказать.
Да, я непонятно написал. Имелся в виду путь из
0в13. То есть в терминах задачи — пусть массивaсостоит из одного нуля, и мы хотим ответ дляm = 13.Так вот, когда происходит
d[13] += d[12];, вd[12]ещё ничего нет. Единица изd[0]вd[13]попадает единственным способом — как указано выше в комментарии.В более общем случае — если
x & y = x, то изyполучается изxровно одним способом. Рассмотрим те биты, в которых уxноль, а уyединица. Переходы — прибавления этих битов в порядке возрастания их номеров.Для визуализации можно нарисовать куб (вершины — числа от 0 до 7, соответствующие маскам от
000до111). Пусть рёбра по осиOxкрасные и соответствуют прибавлению 1, по осиOyсиние и соответствуют прибавлению 2, по осиOzзелёные и соответствуют прибавлению 4. На такой картинке можно посмотреть, сколько способов попасть из одной вершины в другую, если сначала можно идти только по красным рёбрам (i = 0во внешнем цикле), потом только по синим (i = 1) и в конце только по зелёным (i = 2).Можно посмотреть на это с другой стороны. Пусть di, mask — сумма по всем mask', таким что по первым i битам mask' — подмаска mask, а по остальным — в точности mask. Тогда d0, mask — input задачи. Как перейти от i к i + 1? Если mask[i] = 0, то di + 1, mask = di, mask. Иначе, mask'[i] либо 1 (di, mask), либо 0 (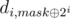 ).
).
В таком виде динамика более или менее очевидна, а то, что указано в посте, — просто оптимизированная версия, хранящая только один слой.
О, спасибо! Теперь мне более-менее понятно, как до этого можно было додуматься.
I tried to explain this here: http://codeforces.net/blog/entry/10476 (problem Div1. E, section "Solution fount by other contestants").
In short, let's create a function f(left, right): calculate d[j] for every j with property that left <= j <= right considering only a[i] such as left <= a[i] <= right. Answer should be fount after doing f(0, 2^22 — 1).
When you calculate f(left, right), let med = (left + right) / 2. We do divide and conquer. Let's call f(left, med) and f(med + 1, right). Now we have to "merge" the results. In [left, med], all numbers are equal to those from [med + 1, right] after switching the MSB of [med + 1, right] from 1 to 0. Hence, for i in [med + 1, right], i — (med + 1) is a submask of i (and all submasks of i — (med + 1) are submasks of i). So, we need to add d[i] += d[i — (med + 1)], for i in [med + 1, right]. After this merge step, nothing is counted twice, because when we do d[i] += d[i — (med + 1)], we add only numbers from [left, med] range. As the current range is [med + 1, right], those numbers were not added before.
Now the recursion code and yours are equivalent. That is just the iterative implementation of the divide and conquer solution explained :) BTW, this seemed magic for me, too, until I've stopped thinking it as an iterative code and I've started thinking it as divide&conquer.
let us see where a[i] will be counted in d[]. before first iteration it is counted in d[a[i] | 0]
let i1, i2, i3 ... in be the unset bits in a[i] such that i1 < i2 < i3... after first iteration a[i] increases count of d[a[i] | (1 << i1)]. so it affects d[a[i] | (1 << i1)] and d[a[i] | 0] after second iteration d[a[i] | (1 << i1) | (1 << i2)], d[a[i] | (1 << i2)], d[a[i] | 0], d[a[i] | (1 << i1)].
At each iteration of i1, i2.. affected indices are doubled. so total indices where a[i] is counted is 2^n, and all of the indices are supermasks of a[i]. Since a[i] has 2^n supermasks, a[i] is counted only once at each supermask.
I now the blog is old but I want to add a useful link here (for anyone who needs it). This is called sum over subset dynamic programming.
This is just prefix sum on a higher-dimension array. Probably an array like a[5][5][5][5][5] might be easier to imagine how this works.