


Suppose we have the standard knapsack problem and our DP state is (idx, remWeight). Due to memory constraints, we can memoize two rows only (say idx and idx + 1). How can we print the solution (the sequence of taken indices) for this problem?
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
27:25:55
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
27:25:55
Зарегистрироваться »
*есть доп. регистрация
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир





Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 22.11.2024 14:09:05 (i1).
Десктопная версия, переключиться на мобильную.
При поддержке

You could do that, but not by storing the last two rows of the DP, but by storing some "checkpoint" rows (one array for every k-th row, let's say). That way you could output the last k value in O(k * T(1)) where T(1) is the complexity of completing one row of DP, in the case O(S). You would also have to keep in mind the "parent" (sum, in your case) for every k-th row. Total memory would be O((n / k) * M(1) + k * M(1)) (the first part is for storing the checkpoints, the next one for reconstructing a segment of rows). Now, what would be a right value for k? :)
Note: Of course, M(1) is the memory needed to store one row, in this case it is O(S).
I didn't understand how you build it. I normally store the id of the next move in the case of knapsack 0 (use this) , 1 (ignore this) in a matrix[N][S] ... you are saying i will do this only each k-th. Imagina K = 4 how will i build from K=4 to K=8 ? i am a little bit confused there.
You can, check out Hirschberg's algorithm. It's a cool trick, allowing O(n) memory.
Use divide and conquer to reconstruct your solution. Remember the point where your optimal solution meets the middle row of your DP table. No matter the point, your smaller problems will be roughly equal in size.
I've solved a similar problem to yours some time ago. Here is the code which implements this idea, but you will probably have to change it up for your task, it's just for you to make an idea.
Interesting! Sadly, the running time of the solution seems be multiplied by a logarithmic factor, which might not be always a good thing (considering the fact that you are trying to optimize memory to a fraction of the time's performance, which should be high in this particular case). I wonder if it could be further improved to linear time and memory of one lesser order.
Can you please explain in more details how this trick works?
I couldn't find lot of resources on it. Any problems/editorials would be nice. Also, can you explain clearly how the re construction is going to work for a generalized DP with state, (n, S)?
Yeah, sorry, i should have done so in my first post.
Let's talk about a general DP(N, S), like you suggested. Let's define f(left, right, K) with 1 ≤ left ≤ right ≤ N and 0 ≤ k ≤ S our subroutine, which besides computing the optimal answer, also prints the solution. Imagine the solution is a path in the DP table. We want to cut the path so that we end up with 2 smaller subproblems of (almost) equal size. The way to go is definitely chosing the middle line, but where exactly? If we don't chose the right point to recurse, we will print a solution which has nothing to do with the final answer. Therefore, we need to find for DP(right, K) the point 0 ≤ P ≤ K where the optimal solution for DP(right, K) intersects the middle line. This should be do-able in O(N) additional memory. This may vary from task to task, but i will offer an example for the knapsack task, e.g. suppose going from DP(i - 1, j) to DP(i, j + weight[i]) improves the solution, then:
(where line and previous_line are 0/1 accordingly, the usual memory optimization)
Our calls to the smaller subroutines are obvious now:
(Credits for this diagram goes to bioinformaticsonline.org)
Let's analyse the time complexity now (for the knapsack problem for example):
T(N, K) = O(NK) + T(N / 2, P) + T(N / 2, K - P)
Look at the areas of the first smaller subroutines. They add up to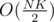 . The next ones will add up to
. The next ones will add up to  and so on, therefore the final complexity is O(NK * (1 + 1 / 2 + 1 / 4 + ..)) = O(2 * NK). A small cost for such a memory reduction.
and so on, therefore the final complexity is O(NK * (1 + 1 / 2 + 1 / 4 + ..)) = O(2 * NK). A small cost for such a memory reduction.
The only task i've ever solved using this trick is called ghiozdan, that's Romanian for knapsack. It's a good task, combining both the Bounded knapsack and the Hirschberg tricks. I'll make a quick tl;dr: you want to fill up a knapsack of size less or equal than 75000 using as few items as possible from a list of at most 20000. Time limit is 2 seconds and the memory limit is 16384 kbytes. Sadly, iirc it has weak tests, but if you want to learn something new you should try solving it in a legitimate manner.
Feel free to ask if anything is left unclear, wrong or just explained poorly. I'll do my best to fix it.
http://www.cs.nthu.edu.tw/~wkhon/algo09/tutorials/tutorial-hirschberg.pdf
^Found this, seemed very helpful to me atleast!!
Oh wow! That's super cool! Thanks for explaining!
Thank you guys for your replies :)