


THi Codeforces!
I'm glad to announce that today at 17:35 MSK will take place first round in the new year — Codeforces Round #390 for the second division. Traditionally, first division participants will be able to take part out of competition.
Round was prepared by me, Alex netman Vistyazh.
Many thanks to Nikolay KAN Kalinin for his help in contest preparation and Mike MikeMirzayanov Mirzayanov for the Codeforces and Polygon platforms.
You will be offered five problems and two hours to solve them.
Scoring will be announced closer to beginning of the round.
UPD: Scoring is 500 — 1000 — 1500 — 2000 — 2500
UPD2:
There were some troubles during contest — in problem C first pretest wasn't equal to first sample, and unfortunately this problem was solved much worse than we expected. I made conclusions and next time I will estimate difficulties of problems more responsibly.
Congratulations to the winners!
Div 2:
- i_wanna_no_exams_fluever
- markysha
- Yamada
- LLI_E_P_JI_O_K
- I_love_livlivi
- wolf29
- sunjam
- AkaneSasu
- GemaSamuca
- EliteWantsYou
Div 1:
UPD3:
Editorial posted!







Auto comment: topic has been translated by netman (original revision, translated revision, compare)
I am new here. This will be my first contest here. So will I get my first rating by competing in this contest
henchmen, of course, yes ;)
Thanks Alex. Show time
I registered a long ago, but never take part in contests, because I am absolutely not good at algorithms or at solving complicated logical problems. This is going to be my first contest too, so good luck to both of us :)
Auto comment: topic has been updated by netman (previous revision, new revision, compare).
In the email I received about the contest, it's said there will be six problems. So, five or six? :)
There will be 5 problems.
First division participants taking part in divi2 contest?. Easy win for them
Div-1 participants can participate in Div-2 but those contests will be unrated for them. So they are out of competition.
maybe there is no "thanks to GlebsHP" in the blogs anymore
but always thanks to him, because we had lots of great Rounds last year and the efficiency of the problem has increased dramatically
also, thanks to KAN, and hope we're gonna enjoy the Rounds this year
D2C was one of the dirtiest problems in CF, wasn't it?! and D2D was too simpler than usual. but it was a satisfying contest at all. :)
Nevermind, my fail.
You are advised to read all the problems. because sometimes i used to find 'D' easier than 'C'.
it will be CF div2 round for Legendary grandmasters
and newbies are out of competition XD
I have short.
First Contest of 2017... Hoping for positive rating change
don't think about ratings, u are here for solving problems and learning something new and challenge yourself :)
Don't want to have a cosine curve :(.wanna have a sine curve :)
hope interesting problem :D
Toady will see many Legendary grandmaster/red coders.
First contest as Blue. Hope I won't need magic to retain the blue color :)
Waiting for the scoring to be announced
Most of the contest it comes after the contest.
Never!
How could it even come after the contest — I suppose that at the worst case scenario it is announced right at the start of the round?
And scoring?
Auto comment: topic has been updated by netman (previous revision, new revision, compare).
i registed and now it tells me , i'm not register and
i can't find the register button !!!!
I'm giving a contest after a very long time.Is it due to lack of practice or is the contest really very difficult??
A & B not that hard but their codes are really tricky. C & D are really hard.
What is the reason for WA on pretest 1 problem C? I have exactly the same output...
I don't think you are allowed to discuss the problems here. pretest 1 may not be the same test case as sample test 1.
Same situation with me!
Once happened with me. In my case, i have used "long long int" to access an vector of integer. In my pc not presented error, but CF presented WA on sample 1 :(. I solved this problem by changing the compiler version on CF.
may be you forgot to initialize something .
The level of Codeforces is going down day by day with all these nonsense questions
Worst difficulty control in the Division 2 ever :/
Probably you didn't see my round :D
2 hours of my life i will never get back :/
I don't have to tell anything bad about contest!
But when I saw input in the third task I wanted to cry :( I think even it is better to put 1250 score or 1000 and read simply numbers with some other explanation instead of this strings.
Thanks for contest.
I'm a bit sad about problem C. Anyone can solve the question, but the problem was properly formatting and displaying the results. I spent more than an hour and failed, I believe there might be some easy way to solve the question which I missed. Waiting for editorial!
Indeed, the idea behind problem C could have been wrapped into another more friendly problem.
I usually code in C++ but recently I have been trying out python on codeforces. I think python was suitable for problem C.
usernames = set(input().split())user, text = input().split(':').set(re.split(r'[^A-Za-z0-9]+', text))-operator is overloaded for sets.Implementing this in C++ is so much more effort.
Does C have a better solution than backtracking?
DP on states (index, last user choosen). Possibilities for current user that is unidentified are n. So total complexity O(n*m*m*) per test case
Thanks for the explanation!
Let's make for all users with unknown name (?) the possible names we could put there. So count[i] = number of possible names to put in row i. If count[i] = 0 and right now it has "?" as username, there is no solution, if there are some i with count[i] = 1, you should put its unique possible name.
Now putting that unique name at some position i with count[i] = 1 could change other count[j], so you do this like bubble-sort algorithm, where you stop when there are just count[i] >= 2 left
If you got to a point where there are just usernames with "?" and count[i] >= 2, there is always a solution, and you can do greedy on that.
I like your solution. It is very easy to code given so many string manipulation requirements in the problem.
Well... I did this in contest, ended up with 200 lines and ran out of time to debug.
backtracking?
do you mean backtrack to recover the solution after doing dp?
My solution will probably fail but anyway, this is what I did. First keep a map to maintain the amount of names which we cannot replace with a given '?'. If it for any of the '?', the value is n, answer is impossible. Now check how many of them have the value n-1, then we satisfy this and update the sizes of neighbouring question marks (if there are any). Keep repeating this until you run out of questions marks with value n-1. Now remaining have values <=n-2. Assign anything to them (obviously not the names in their messages) and keep updating the neighbouring ones. Print the answer according to this.
In problem C,
The length of the text is positive and doesn't exceed 100 characters.
Instead of,
The length of the message is positive and doesn't exceed 100 characters.
Thus, the maximum length of message will be 10(username)+1(':')+100(text)=111. Unfortunately, I set the maximum length of char array as 111. Thus, null byte('\x00') will overflow to next row and makes me keep getting WA :(
Does someone face same situation as me?
Reading C: OMFG the length of the statement is legendary. Wait the input too. Skipped to next problem
Did anyone manage to solve D with sorting and segment trees? :|
I tried to do it, but I got mle on test 9, then I coded ordered_set.
Hmm, getting MLE on test case 9 with statically declared arrays?
In fact, it can be solved just by sorting events({position, coupon-id, is_start_or_end}) but it requires careful processing :/
Sorted by l first, then r for each coupon. Used sliding window to get the best result. Didn't need segment trees, but it's standard code, so not too error prone. Got WA on test case 6 though :/ . My logic feels correct, although didn't have time to strongly prove it during contest.
May I ask why did you think your approach is correct?
First of all, I tried to find the best result if coupon[i] in sorted coupons(by l first, then r) was definitely included.
Now, as the next coupon either has a higher r, or higher l, I can use any technique to find the maximum L and minimum R in the coupon range [i,i+k-1] and their difference is the value I get from this k-sized window.
Hmm, I see a possible reason why it's wrong. Nevermind my comment, it's wrong.
I tried and got WA on 5
Yes. It was close in memory and time but I optimised ^_^
Sad story here. Just like 1 minute before the contest, i finished my solution for D.
However http://codeforces.net/contest/754/submission/23606581 I didn't printed k integers in case if answer is 0. By the time i realized the time was up..
I didn't participate the contest, is the TL for div2E really that tight? I am thinking about using KMP for the problem and that should cost O(nm log(row) *** row**) time, but that doesn't sound like a complexity for a 6s TL question.
I think the difficulty for this round is pretty decent, the only annoyance I found is parsing the input for C (but it is just because of me sucking in expression parsing).
How would you handle question marks with KMP in E? My solution uses bitsets and has an
O(N^4 / 64)time complexity, so the time limit seems reasonable (under assumption that the model solution is similar to mine).Maintain a set of integers at each board position. For each line of the pattern, use KMP to match the each line of the table, insert all valid matches to the corresponding positions.
Then iterate all the position of the board and assume them to be the upper-left corner of the pattern to answer all board position... And my bad I missed this part's time complexity. It should be O(nm log(row) *** row**).
Consider the original one as aba
and the pattern is a*
:(
How do you use bitsets? Letters are not single bits. I wrote standard 2-dimensional Furier solution with O(N*M*(N+M)) complexity.
We know the row of the original table where each row of the pattern should go if we fix the upper row of the occurrence. If we find the set of good columns for the first symbol of the pattern in each row, the set of good columns for the second symbol of the pattern for each row and so on and intersect them all, we'd get the answer.
Let's iterate over all elements of the pattern. If a current element is a question mark, we can just ignore it. Otherwise, we need to intersect the current answer with the mask of occurrences of the
pattern[r][c]character in the corresponding row of initial table for the(r, c)(taking into account the shift ifcis not the first column).To do that I precompute a
mask(row, shift, c)— a bitset of all occurrences ofcin therowif its shifted byshift(naively inO(N^3)).After that, I iterate over all top positions of the occurrence and compute the
andof corresponding masks. It would be easier to explain it with pseudo code:The correctness of this solution is more-or-less self-evident (the column is "good" if and only if its "good" for all positions of the pattern).
The time complexity is
O(N * M * R * C / 64)as there are three nested loops (up toN, up toRand up toC) and there's exactly one bitset operation inside the innermost loop.Got it. I thought about this idea during the contest but I didn't go any further and missed the connection with bitmasks speed up.
KMP does not work, see my first submission :( (maybe there's a bug in my kmp tho, lol, or hey your kmp is different from mine). I notice a 30ms solution tho, don't understand how it works but it does not seem to be kmp either. My solution works with same time with kraskevich, O(N^4/64)
EDIT the 30ms solution actually TLE in one of my testcase
In fact no O(n+m) algorithm for counting occurrence of wildcard matching is known as I saw here. http://web.cs.iastate.edu/~fernande/STRING-ALGMS/MoreKMP.pdf
Whoops, you are correct, I only considered the case where the wildcard character only appearing at the final character of the longest prefix. =P"
The difference in the difficulty level of A and B as compared to C and D was too high. Wasted so much time trying to hack.
I had thought that pretest 1 is the sample i/o, but i have passed all the samples only to find "wa on pretest 1" constantly in problem C
Me too QAQQQ.
it was a disaster...
It seemed like a hardcore implementation contest atleast till problem C.
Actually, problem D is also a hardcore implementation problem.
I solved D using Binary search and Priority Queue maybe the solution is correct but it wasn't hardcore, Actually I started on it because C was hardcore :D
I really liked the contest, except for problem C. Problem A was not trivial, and problem B was fun. Problem C horrible input. I suck at everything relating to strings. And problem D was beautiful. One of the best I've seen. And problem E, although I couldn't solve it, seemed interesting. Thanks for the round!
What is your logic for D? Since you say you think it was beautiful I'm guessing you had a beautiful solution.
Use a vector v where you have the starting point, the ending point and the id of each coupon. Sort it by starting position. Use a priority_queue pq with inverse order (i.e. the minimum element is at the top). Insert the first k ending points to them. Use 2 values m,M, which initially are m = v[k - 1]start, M = pq.top(). Iterate from index k through n - 1, and in each value, insert in pq v[i]end, remove the smallest element from pq, if M - m < pq.top() - v[i]start, actualize M and m to pq.top() and v[i]start, respectively. At the end, if m > M, print 0, and the first k elements. Otherwise, print M - m + 1, and k elements that their starting point is lesser or equal to m, and whose ending point is greater or equal to M.
Doesn't your solution fail on the following case?:
I'm not sure if it does or not, but I thought of this solution in contest and I thought it would fail on cases like these.
Outputs:
, which is right. Besides, it has already passed system tests :)
Oh yeah, I got what I missed. I was so close though :( Anyways gj for solving it and ty for your solution.
Can you please, give the proof for this solution . Ie why sorting it and the further steps provide the most optimal solution ? Thanks.
Suppose that we want to find the intersection of k coupons. You can see that if an element belongs to the intersection, then it is lesser-equal to the minimum of the ends of these k coupons. Also, if an element belongs to the intersection, it is greater-equal than the maximum of the beginning of these segments. Then, the intersection of k intervals is the minimum of the ends-the maximum of the beginnings(+1). By sorting the array, I guarantee that the last element I am checking has the maximum-beginning of the elements up to him. Now, at each step, I am checking if the maximum intersection of an array which contains k - 1 elements previous to this, and contains this element is bigger than the maximum intersection I already have. We have to choose k - 1 intervals previous to this such that the minimum ending point is as big as possible, as the starting point is fixed and thus not relevant. This is given by the priority queue, as its size is constant.
this round has to be Codeforces hacker cup
I THINK problem D is similar to interval covering greedy problem ..my approach was that i will sort the interval by start time then i will make two pointers to select the intervals of length k but the problem is i couldn't handle when i move the left pointer to right how can i update the answer ? any hint
*let's sort the intervals
L : to store every left side and it's index
R : to store every right side and it's index
add first k intervals to the sets
the ans exists if the max left side <= the min right side
-you can find their values easily from the sets L,R -first element in L is L.begin()->first -last element in R is (--R.end())->first
the optimal way is to remove the interval with the min right side
you can find it's value and index easily from R then remove it from both sets
during the process , you should save the best ans to get it back
take a look at my solution and ask me again if you need : http://codeforces.net/contest/754/submission/23603100
I tried to submit D. in last 20 seconds, but for some reason the site was down, and I couldn't send it. Feels bad, man :(
I had the same issue during the last 10 minutes, maybe it was also because of the internet connection, but you should know that it is a common on CF :(
is it only me or the colors we are in right now and are titles are not displaying correctly.A 1400 is being shown a legendary grandmaster
This is because of Christmas "magic". You can change your colour till the 10th of January too, under the magic tab on your profile.
Problem C was an absolute mess to implement. However, I very much liked the other 4 problems, overall good contest, but hope to see less of these messy implementation questions soon :)
Thanks for interesting contest Netman
Although I think my solution for D will fail but really I liked A and D a lot and wanted to finish the D early to try to solve C :(
Unsuccessful start for KAN
I'm ready to disagree.
What's test case 5 on D?
I think you forgot to get actual indices after sorting. When I fixed it I passed test 5.
Maybe something like:
2 2
1 2
2 3
This contest is good for me to overcome my laziness about studying algorithm.
What algorithm?
Difficulty level of the round was extremely unbalanced. Problems A and B were easy but implementation was tricky , therefore required a much longer time than should ideally be devoted to them. So those in the middle ratings of Div 2. spent their time implementing A and B longer than they should have , and could devote less time to problems C and D.
Problems C and D were in completely another league altogether — the difficulty level was much more than A and B (difficulty level did not increase gradually in steps). This along with the implementation time factor above prevented more people from taking a decent attempt at the C and D problems.
Ideally , when considering for each problem the number of users with all passed pretests , we expect an inverted pyramid (decreasing exponentially) wrt Problem number.
This is clearly NOT seen in this contest , which divides the users into haves and have nots instead of in a spectrum. The distribution of the users just before the contest was somewhat like this —
A — 3172 , B — 3239 , C — 190 , D — 384 , E — 14
Clearly those who solved only A and B are a whole bunch of people with very different abilities, and the (D,C) proportion is very less.
Yeah C, D were whole new Level, :p thats why i became an expert by solving A, B quickly enough, got lucky, Oh and hacks!!, too many people ignored this in the first question
3
0 0 1
Actually, the best round of 2017.
You , I like you. :)
worst round of 2017 too.
So far
Hopefully
How to solve D without ordered_set? Or is it required?
Heap and two pointer is all you need for D. (I suppose, I didn't submit for system test =P)
It works, I did it like that 23601738.
I solved it using priority queue. Here is the code. 23593559
Another way to do it without priority_queue is to use an AIB and binary search.You split the interval in two types of events.A starting point and an ending point.Every point will know from which interval came.You sort the points first by value and then by type of events if they are equal the starting points should be the first.
For every starting point you add at position X in AIB 1, where X is the position in the initial sorted vector of intervals.When you have an ending point, you try to find in the AIB the smallest position where are exactly K intervals using binary search ,you save in max the result and you Add -1 in the AIB again at the sorted position for this point.The complexity should be O(N*logn + N*log^2(n))
problem c was all about decoding the input . it was quite an annoying problem ...
how to solve A ?? :(
The simplest way: If total sum is not zero, segment is 1 to n.
If it is zero, Find the first non zero point(say index i) then segments are 1 to i, i+1 to n.
So first of all let's see when it isn't possible to answer, and you can see that it is only that case when wall the input are 0s. When the input has an integer different than 0 you have two possibilities:
in 2) you can simply output the whole array
in 1) if you get from the first element to the first different than 0, and from that one till the end. It is guaranteed that both are different than 0
Loved the first question. On first reading it came across as a quite complicated implementation question where one had to keep track of the 0's and couple them to other non-zero elements. But the trick is to see the total sum. If the total sum is non-zero then the answer is : YES 1 N But if the sum is zero, scan upto the first non-zero element (let's call that index Q) and your answer is : YES 2
1 Q Q+1 N
NO : only when all the elements are 0. No further check for NO are required.
Waiting for the rating to be announced.
Could someone help me find the bug in this code? It gives 0 when then answer is different than 0.
http://codeforces.net/contest/754/submission/23607400
I don't understand the negative comments, this is the best round of 2017... up to now.
Rating are updated now.
Would someone be kind and explain me why my solution (23608573) for D fails?
Thank you in advance. :)
In today qs 1.
I know, the answer are different but the sum of any of my subarrays is not 0. I got WA in 7th case system testing. I have mentioned a part of input for 7th test case, can anybody please help, what is the problem.
PS : I am sorry to post here, I have no idea, what else to do!
If you check the test, you output
60 60
66 67
Skipping 5 integers, that's why you have the WA
Editorial please !
What the **** is wrong with C++?
Look at this submission 23592356 on 754A - Lesha and array splitting.
I tried to hack it with test
5 0 0 0 0 0, but on CF it works. Same code fails on ideone: linkNote: It should fail on line
while( t[it] == 0 )becauseit == n.Upd: I think, he used the fact that that array will contain some trash on
a[at]whenitbecomes as large asn. But it's too duty trick.Upd2: Ok, it seems that after this array there lies variable
n(as it defined right after an array), soa[maxn] == n. Because of this there are no access violation error and the loop stops whenit == maxn.You can't hack it by your test.
Update : In my opinion your test it (variable in code) will grow up to MAXN. Because for p = (n+1, MAXN) : a[p] == 0
He checks a[i] for i = 1..inf, so it should be runtime error
But in the same time the solution may exceed MAXN, because it may outbound vector and get to a forbidden zone of memory for the vector.Still in the way is a high probability to find a non zero element so it stops there.
The code at hand has undefined behavior — once
it == maxn+1, it reads past the arrayt. The C++ standard does not guarantee memory order of global variables, and it cannot be guaranteed what is located there. If, say, the adjacent memory contains integern, the condition evaluates to false and the loop terminates. However, if there is only zeroed memory,itwill become too big andt[i]will point to invalid memory, causingSEGV.Am I the only one who got confused at B(ignored the diagonals of size 3)?
Yes.
Lots, lots and lots of implementation codes
How should D be approached .. what is the principle behind solving D ?
(The editorial is taking too long :P )
When we choose k coupons, (x1, y1), (x2, y2) ... (xk, yk), number of products we can use is minimum y — maximum x + 1. So we need maximize this value.
Sort initial points by y coordinate increasing. Let's say we are at position i. We can fix this point as the one with the minimum y, and we need to take k — 1 points from range [i + 1 ... n].
The k — 1 points must have maximum x coordinate as small as possible, in order to maximize the value (minimum y — maximum x + 1).
Let's iterate over all points in this order : n, n — 1.... 1, and maintain a heap / set with smallest K x coordinates we have met until now.
The answer for a position i would be : y coordinate of i-th point — largest value in the heap + 1.
Let's say we divide every pair of coupons in two kinds of events, a starting point one and a ending point one.We know that the largest interval we can find for example (x,y), the x will be the x of a coupon interval and the y will be the the y of another coupon interval.
If you do a line sweep in every point and for example you push the interval which has the x point in a set, when you get to a y point you will erase the interval which has this y point but if you do this , it will mean that if you are at a y point you will have in the set all the intervals (x1,y1) in which x1 <= y and y1>=y. At this point the problems resumes at a classical problem.Which is the x from this set, that if you sort all the intervals in the set by x, it will be the k'th element.
How to solve E?
Consider 1d version:
There are 2 strings a and b (maybe with question marks), we want to find all occurrences b in a.
Create vectors A and B such that
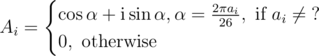
Then calculate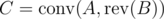 where
where 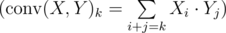 . Now b can start from position i in a iff
. Now b can start from position i in a iff 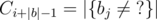 (remember that C is complex vector though).
(remember that C is complex vector though).
For our initial problem we can use similar approach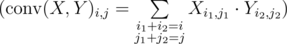 . To find 2d convolution we just need to apply fft to rows, then to columns.You can check my code. Overall complexity is
. To find 2d convolution we just need to apply fft to rows, then to columns.You can check my code. Overall complexity is 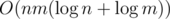
btw, most of the contestants just used bitsets to find substring occurrences, but there is nothing interesting in those solutions.
Dude, seriously, how did you come up with that? What led you to think about these crazy vectors A and B? Could you please list some problems you solved with FFT like that before? That would be an insanely great contribution to the community.
He's russian, it's insanely trivial for him.
editorial?
Are there any problems similar to D? Like greedy + heap? It can be from gym or other sites.
NICE ROUND! I really like Problem A,B,D and solve them quickly.
But which stops me from higher rank is problem C.//I got rank 35 and became purple (:
I used BFS to solve it, but got WA on Test 4.
After the final test, I saw that test and still don't know why I was wrong.
Below is part of test 4:
10
9 SBkyKniF rR5X G7TP K3ddkoeg6 auvBIAv4ZG Q5yW19Zp Hg CdZoe0Hg M 14 ?:Hg!Q5yW19Zp!Q5yW19Zp CdZoe0Hg,auvBIAv4ZG,Q5yW19Zp.K3ddkoeg6,Q5yW19Zp auvBIAv4ZG?SBkyKniF,auvBIAv4ZG, CdZoe0Hg:auvBIAv4ZG!G7TP?auvBIAv4ZG.Q5yW19Zp?Hg.K3ddkoeg6!auvBIAv4ZG?Hg,G7TP,auvBIAv4ZG!auvBIAv4ZG?Hg,Hg..bEu auvBIAv4ZG:Q5yW19Zp.CdZoe0Hg,?!CdZoe0Hg?rR5X,??Q5yW19Zp.K3ddkoeg6?SBkyKniF!G7TP!rR5X,G7TP.K3ddkoeg6.rR5X,Hg O ?:?.CdZoe0Hg?K3ddkoeg6.auvBIAv4ZG!rR5X.?.SBkyKniF!Q5yW19Zp!?!CdZoe0Hg!Hg?SBkyKniF!Q5yW19Zp,Q5yW19Zpx ....
ANSWER: rR5X:Hg!Q5yW19Zp!Q5yW19Zp CdZoe0Hg,auvBIAv4ZG,Q5yW19Zp.K3ddkoeg6,Q5yW19Zp auvBIAv4ZG?SBkyKniF,auvBIAv4ZG, CdZoe0Hg:auvBIAv4ZG!G7TP?auvBIAv4ZG.Q5yW19Zp?Hg.K3ddkoeg6!auvBIAv4ZG?Hg,G7TP,auvBIAv4ZG!auvBIAv4ZG?Hg,Hg..bEu auvBIAv4ZG:Q5yW19Zp.CdZoe0Hg,?!CdZoe0Hg?rR5X,??Q5yW19Zp.K3ddkoeg6?SBkyKniF!G7TP!rR5X,G7TP.K3ddkoeg6.rR5X,Hg O M:?.CdZoe0Hg?K3ddkoeg6.auvBIAv4ZG!rR5X.?.SBkyKniF!Q5yW19Zp!?!CdZoe0Hg!Hg?SBkyKniF!Q5yW19Zp,Q5yW19Zpx rR5X:G7TP!auvBIAv4ZG?Hg,auvBIAv4ZG?CdZoe0Hg,Hg,K3ddkoeg6.Hg?SBkyKniF,G7TP?Hg ?.a...
So why the first message is sent by "rR5X" instead of "M" or "G7TP"? Probably my poor English is not enough for me to understand this problem.
There can be multiple answers. Jury's answer is just one of them.
When will the editorial be published?
Do you remember something called Tutorial !
Editorial ?
my code
can someone give me a counter testcase where my code is failing..
Try this: 4 2 3 7 1 4 2 6 5 8
when you post editorial?
Can D be solved with segment tree?
You can, but I don't think it's an efficient approach.
How to solve D ?
Here is my approach to solving D. 1.Let's first store a vector {l,r} in another vector for all queries. Let's denote this vector of vectors as v. 2.Now sort this vector.Now we have a vector containing l,r pairs sorted by l. 3.Now here is the analysis — The answer to our question is a range such that its 2 endpoints belong to the set of points obtained from queries. Whenever we get a query of form l,r, we include l and r in this set of points. Lets call this set pts. So our 2 end points belong to pts. 4. Now we plan to iterate over the pts set(stored in a vector). We also make a set<vector> called st. Now as we iterate over pts, we keep in our set only those ranges from v such that their l <= pts[i]. We put the sanges into st in the form {r,l}, so that the ranges in set are sorted by r. 5. We plan to use 2 pointer technique here. For each i over pts we increase j (which is also iterator over pts) and remove all ranges from st whose r<pts[j] till the size of st > k. 6.The answer is max of all pts[j] -pts[i]. 7. There are definately a lot of details left to be explained but are not very difficult to figure out. This is just the basic idea. 8. If you feel something wrong with this approach, feel free to tell me.
I understood the problem after reading the following comments:
1. explanation1
2. explanation2
3. explanation3
4. explanation4
After that I came up with my own interpretation — maybe it will be useful for someone.
Let's think backwards. Imagine that we know the largest interval that we get after intersecting some k out of n original intervals. This interval has to start at some position lbest and finish at some other position rbest.
Now let's concentrate on the starting position of the largest interval — lbest. What is the smallest possible value for lbest? In other words, what is the leftmost position where the largest interval could possibly start?
Intuitively, we need to take k smallest values from a set of all possible left coordinates:
Ln = {l1 ≤ ... ≤ lk ≤ lk + 1 ≤ ... ≤ ln} ⟶ Lk = {l1, ..., lk}
The value lk is the largest value among all left coordinates in Lk. The left side of the final largest interval cannot be smaller than lk.
So, here is a skyscraper view of the algorithm:
1. First we set lcur = lk as a starting point of our investigation.
2. We find the largest interval that starts with lcur, by gradually extending rcur.
3. The interval [lcur, rcur] is now a local maximum and we compare it's length to the global maximum achieved so far: [lbest, rbest]. If dist(lcur, rcur) > dist(lbest, rbest), that means we have discovered a better interval that starts with lcur. We update global maximum: lbest = lcur; rbest = rcur.
4. This new interval [lbest, rbest] is largest among all possible intervals that start from lbest or start sooner than lbest. Possibly, there is a better intersection of the intervals that starts to the right of lbest, so we update the set Lk and go the step 1.
Can someone please help me with this : 23624246
According to me, the time complexity is O(2 * n log(n)) which is O(nlog(n)), but my solution is timing out.
I am creating an array of size 2n, sorting it, and then adding half of the points to a priority queue, and also removing all of the n points one by one. None of the points are added multiple times, so the complexity is O(nlog(n)). But somehow it's timing out. Can someone please tell me what might be the problem?
Thanks in advance.