


Competitive Programmer's Handbook is a new book on competitive programming, written by me. The book is still in progress but almost ready, and I decided to release it now for a wider audience.
You can download the book here:
The book consists of 30 chapters and is divided into three parts. The first part discusses basic topics such as programming style, data structures and algorithm design. The second part deals with graph algorithms, and the third part introduces some more advanced techniques.
The book assumes that the reader knows the basics of programming, but no background on competitive programming is required. I think that the book is useful for future IOI participants, as the book covers most topics in the IOI syllabus.
The final version of the book will be ready later this year. The PDF version of the book will be available for free also in the future, and in addition, there will be a printed version that will cost something.
Before the final version, I will do small fixes, improve the language and add references. Of course, I appreciate all feedback on the book — you can send it to this blog or directly to me.







YOU HELPED IN A GREAT WAY ____///////////////\\\\\\\\\\\________ A BIG SALUTE
iN last of every chapter makeexercise of some problems of various ojs
Good job!
I love it :) But I think you can add more problems , and more advanced topics too
Are certain sections highlighted at the start of the section that its exclusively for ICPC participants? So that those aiming for IOI may not go in much deep! Thank you Keep up the good work
At the moment there is no such classification, but it might be a good idea. However, new topics are regularly added to the IOI syllabus, so it is difficult to say what is needed in future years. I also think that all topics in the book are worth learning, even if they are not in the IOI syllabus at the moment. :)
Logged in just to Upvote this blog and say thank you to pllk. Great job :)
Thank you! I think it is a really good book with very focused content. Just a suggestion, maybe you could include some competitive programming tricks into your book? For example, how to write a shortened version of a common algorithm (e.g. union-find can be written in 4 statements without using union-by-rank heuristic and is still good enough in competitions)?
You are right, I should at least mention the other heuristic. I have used the union-by-size heuristic, because I think it is both easy to code and explain why it works in logarithmic time.
Thank you for sharing. The book is well written. Definitely a plus!
Very useful and well written :)
Wow, this looks like a tremendous amount of work. I'm really curious about a few things.
How long did it take you? How old are you and are you a teacher? Have you written it in your free time, without the money compensation from e.g. university?
Good questions. I'm 29 now and I teach (among other things) at university.
It has been a long project, I started it in about 2013. First I wrote the book in Finnish (and rewrote it several times because I was not satisfied), and finally I decided to translate it into English (because most people can't read Finnish).
It is my free time project without salary, this is also one reason why it took so long time. But I've learned a lot, both about competitive programming and writing.
The amount of hard work truly shows up in the explanation of your book. Thank you for making it "priceless" :)
You made great job, thank you. How we can donate you?
Brother its fantastic. I salute you.
I think this may be the best competitive programming book for beginners, I've ever seen! I've read some of Competitive Programming by Steven Halim already, and I would say that it is indeed a good book. However, truth be told I don't think it is necessarily beginner friendly. The way the sample code is written makes it somewhat difficult to read at times. Personally, I didn't know much C++ when I started to read it so the constant one-liner "if" and "for" statements he often uses obscured the meaning behind a lot of algorithms, for a few weeks, at times. So the clean code in your book is a huge plus.
One reason I can see this book being the best beginner book is that you "spell out" everything for the reader. I read the chapter on bit manipulation and I certainly believe it is the most well-written piece of literature on it I've ever seen. I don't think I've ever seen a coherent article written on using bitmasks for DP problems written for beginners either, and I can't wait to sink my teeth into the remainder of the book.
Awesome Work !! You can add some related problems in each chapter.
If you share the book sources, the community can translate it to other languages.
The source code is available here: https://github.com/pllk/cphb
It would be great if somebody would like to translate the book (after the final version is ready).
Do you think it's a good idea to start translating it now or is it better to wait for the final version?
There are still some issues I have to fix, but they are small things and there will be no remarkable changes.
So it's already possible to start translating, and I'm very happy if somebody would like to do it. But please contact me before starting so that I know who is doing what.
The translation into Spanish has already begun (github repo), we have 3 active contributors: luismo, jlcastrillon and me, but we hope to join us more!
I read some prefix of the book
It's easy to read (but I didn't find anything new yet but that's pretty normal I suppose)
What I want you to consider is to promote a cleaner code. I think it's quite important especially when there are more than 1 coder in a team (but i find it useful even when I participate in personal contest)
What I mean, for example:
f(l) = true, f(r) = false:By the way, You explain how to sort vector before introducing what it is, so may be it's worth moving sorting chapter after the introduction of vector because or at least say something like if you don't know what it's don't worry, you'll know in the next section.
Good points, I'll try to improve code readibility and other things you mentioned.
It is very difficult to decide when to use 0-indexing and 1-indexing. In algorithm theory 1-indexing is usually more convenient (or look at any Codeforces problem), but of course C++ uses 0-indexing.
Usually in CF problems you decrease by 1 while reading everything 1-indexed and after that you don't fight with the language :)
Usually one doesn't do it. I went through AC-ed submissions of red/nutella people for 768G - The Winds of Winter. 7 of 18 used 0-indexing. Though I believe that 0-indexing is more common in two groups of people: Russians and Java users.
That being said, I don't know which indexing should be used in books. I prefer 1-indexing.
EDIT: typo in quite important place
That's why russians are so cool in ICPCMaybe I live in skewed reality of Russian bastards, then :)
Also more than 99% of Iranian experienced coders use 0-indexing(i.e. Reyna, Haghani, LiTi, mruxim, Deemo). Is there any relation between Iranian coding style and Russians one?
I believe 0-indexing is the only indexing used outside of competitive programming.
But 1-indexing is more people-friendly because we use 1-indexing everyday ("You got the 0-th place? Congratulatons!").
It's also convenient to say "the first element of the sequence" and "the k-th city", so maybe 1-indexing is better for talking about algorithms. And I agree that 0-indexing is more convenient to code.
Stick to 1-indexing, it's more common IRL.
TRIGGERED!
Actually, for this comment to not be completely useless I tried searching for my explanation of why I definitely prefer version presented in book. It is here: http://codeforces.net/blog/entry/17881?locale=en What is funny is that also there you were my main opposer ;p.
As I told you, I'm the guy who likes useless discussions
I've noticed that you add pairs t vector using
v.push_back({1, 2})andv.push_back(make_tuple(1, 2, 3)). I believe, braces initialisation should work for tuple too (and also you may use emplace_back) in either caseDo you mean that I could replace
with
like with pairs? At least I couldn't compile the second code.
Yep, that's what I meant.
It compiles fine on ideone
I see. This has to be a new feature. In Codeforces, if you use the compiler called "GNU G++14", it works, but if you use "GNU G++11", it doesn't work.
Seems like a bug in older g++ or in c++11. Both g++-6 and clang on my machine compile this fine in
-std=c++11mode.you must do v.emplace_back(2, 3) instead of v.push_back({2, 3})
A very well resourceful book.
Thanks a lot for the effort :) I think it would be great if you can add interesting sample problems for each topic and also add some more advanced techniques and algorithms. By the way, I would love to donate and to translate it into Turkish.
Thank you very much for your efforts. I literally learned more today than I did for the last month.
Surely great amount of work. But it will great if you add problem to practice section after every chapter of your book.
Wonderful book, and I think I'll use it often. But I do feel some important topics are missing. Perhaps they could be added into later editions? This could be another of the aspects where the codeforces community could help.
Topics that come to my mind would be fast exponentiation and its applications to DP, along with other dp optimizations like Knuth or convex hull trick, etc.
In fact, Chapter 23 discusses DP optimization with fast matrix exponentiation.
But you are right, there are many advanced topics that are missing. I have plans for about 15 new chapters for the second edition of the book.
Method 2 for binary search would be cleaner if you change b = n/2 to b = (n+1)/2 and b /= 2 to b = (b + 1) / 2. This way you don't need the while loop.
Also, the data structure for minimum range queries is usually called Sparse Table.
Good comments. You can also change b=n/2 to b=n for a shorter code in this case. I will check how established the term 'sparse table' is. I have seen it but it sounds a bit strange.
I also heard a term "sparse table" many times.
About the binary search implementation: it seems that more changes would be needed to remove the while loop, because if b = 1, then also (b + 1) / 2 = 1 and the loop would run forever.
Oh, right. I actually only use method 1. Maybe it would be best to modify it so that the loop iterates over all powers of two, like in the sparse table approach.
People like you , are a blessing for the entire coding community .. :) Thanks a lot :)
If you add some problem name from different oj in each section . It will be more helpful .
Maybe a good solution would be to create an extra file (available on author's website) with links to problems for each chapter. This way it can keep being updated, and the book can just say "if you need problems about some topic, go to this website".
This sounds good. Many people have asked for problems, so it is clear that something should be done. Personally I often don't like lists of problems in books.
Don't take it in wrong way. But you ruined some simple concepts by giving them in iterative form rathar than recursive one. examples:- segment trees,
I was pleasantly surprised to see that the segment tree implementation in this book was like the (beautiful and fast) implementation here: http://codeforces.net/blog/entry/18051
Yes! I think they make books look ugly. Maybe we could make something like awesome-cpproblemslist then
хорошая книга
Thanks pllk, great work, and really amazing coverage of many topics, it would be really helpful to add some practice problems from OJs.
As it turns out, a lot of people are asking for practice problems. So I propose that you guys create a Wiki and make some top rated people willing to contribute an admin of the wiki. Anyone can add problems / editorials here and it will be approved if and only if the quality of the problem / editorial is high enough and actually helps someone to improve their skills.
I don't see why pllk should be obliged to create this wiki. He has done more than enough already by just creating this book and I think the people asking for problems are, more or less, missing this purpose of this book. The book is entitled "Competitive Programmer's Handbook". In my opinion, it seems like a book for beginners to get their feet wet, and understand concepts and aspects of implementation in the process, and for intermediate people to use it as a reference manual when solving problems.
The second reason why I'm against this idea of putting problems in the book is that there are more than enough posts on codeforces with titles such as "What are some good problems involving segment trees" or whatever, and I don't see how it is any at all difficult to simply search for them on the site. I mean just look here, here, and on the entire section of Hackerrank about data structures and algorithms, for instance. Since, this post came to my attention, it has become somewhat easier, or at least more straightforward to read the Competitive Programming book, since I can always use the handbook here as a reference for more "difficult" concepts.
Thanks a lot brother.
I haven't understood this line. Please someone explain me this line. In 2.2 Compexity Classes
A special property of square roots is that sqrt(n) = n/sqrt(n), so the square root sqrt(n) lies, in some sense, in the middle of the input.
It's in the middle in the sense that if you want to divide an input of size N into X parts each of size X, you choose the square root of N. A common case when you want to precompute some number of partial results. 'Middle' might not be the best word for this.
Thank you.Now it makes sense to me.
Logarithmic sense: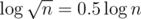 .
.
I've gone through the "Advanced Topics" part and my reaction while reading this book can be described as: wow wow wow wow wow wow.....
Thank you for sharing it.
Thanks loads n loads.
Here is a book I wish I would have got earlier. Went through graph portion. For the first time, I felt dfs, bfs, bellman, Dijkstra are reachable and can be coded.
So kind of you that you have kept it free for all. I will advice this if someone wants to enter competitve programming.
Thanks again. A big hug.
Love the book, especially the advanced topics section, which includes most of the material needed to become a mid-purple.
THANKS SIRRR !!!!!
Your book is awesome. Thanks.
thanks and gratitude
Thank you very very very much!
Thank you for such an amazing book! Im wondering if theres an available epub version of this book?
In
page 259, chapter 29: Geometry, I think it should be:Instead:
Using the formular, we got:
Good catch, thanks!
I noticed it too! :D
You can add Bertrand's postulate to number theory chapter:
There are at least one prime p such that n < p < 2n where n > 1.
Can someone please send me the code for K-th ancestor in a successor graph. I have understood the algorithm but still not clear about writing the code. Thanks in advance.
You can't have "Successor" without S U C C. Even the function in the book is called
succ(x).A really nice resource, appreciate it.
OH my go-----------d!!! This is really an excellent book for a beginner like me. People learn from each other, share with each other and inspire each other. This is how the world develops generation by generation. I think this world needs people like you. With great power comes great responsibility!! Thank you so much for your invaluable contribution!!
This is #1 on HN right now: Thread. There's a bunch of feedback so I thought you should know. :)
Lots of people there really don't like competitive programming, sad!
Competitive programming threads on most sites seem to degenerate into technical interview bashing.
Yeah, I was disappointed that some people digressed to interview bashing on that thread, but others liked the book. Also, my thanks to the author of the book.
You can understand them :)
cp code:
Real life code:
Hey @pllk, thank you very much! By the way, do you have the printed version available for purchase? I would love to buy this book.
Not yet but it will be released later. I will announce here when it is ready. :)
hey pllk
thank you very much for your awesome work
your book was very helpful to me
i'm using it to train for the IEEEXtreme programming competition
which — by the way — will be on October the 14th .
so if i may ask you ... will your book be ready before the competition or not ?
Thank you! You can consider the current version as ready, no new contents will be added.
How can the complexity of Bellman-Ford algorithm implementation in the book be O(N.M) ? shouldn't this code be O(N^2.M) UPDATE: O(N^2.NM) ? (Although the real algorithm complexity is O(N.M) !)
Book page : 123
Good point! Actually the complexity of the above implementation is O(n(n + m)), because the innermost loop will be iterated a total of m times during a round. However, the current revision of the book (page 125) already contains a better implementation whose time complexity is truly O(nm).
Current revision ?
Could you please create something like e-mail subscription! This would be very helpful to notify the community about updates and changes made to the book. Thanks :)
The current revision of the book is always available at https://cses.fi/book.html. If you want to keep track of all updates, it is possible at https://github.com/pllk/cphb.
You're saying that, for example, a dfs will take O(NM) or so. Be careful, learn how to get the complexity of a dfs or equivalently, of this code
Both dfs or this will take O(N + M), why? try to think about it.
Does the book talk about how to problem solve?
What does that even mean?
In the greedy Section Minimizing sums
there are a solution for this:
Minimize (a1-x)^2 + (a2-x)^2 + (a3-x)^2 .... (an-x)^2
And the solution is x = (average (Ai) )
That is because the average is the avarage of the
polynomial roots from nx^2 -2x(a1+a2+...+an)
Someone could explain me why works please??
How prove this??
And it works for every power different to 2?
It is the point where parabola has its minimal value. Google 'derivatives' and learn more
Thanks dalex
It's 100% confirmed now: I've got personal downvoters
Says the guy with +117 contribution :D
...
I have already try to learn CP through some famous books but that books are either difficult or no code in C++ illustration. Thank you very much. A good book for me, also beginners who start to learn CP.
I've never understood this, Why do you need code?
I usually read codes. when i read codes, i understand more quickly.
I think this is especially true for those who are weak at english, so it is harder for them to understand what's written, but yet when you read the code, you kinda get to understand what the author is trying to say.
Great work! I'm trying to translate into Japanese.
It's WIP and I completed until Ch.8. https://github.com/kmjp/cphb
Every book has a nice cover. This book is excellent. It deserves a nice and cool cover!
Would be interesting to have ideas for a book cover. So, let the ideas flow in!
Very good stuff. Good job!
My review on this book:
EVERY F*CKIN' ALPHA-NUMERIC CHAR WORTH
pg. 266, draft Dec 2017, discussing a general formula for the area of arbitrary quadrilaterals, you give the shoelace formula for which 'there are no special cases'.
However, the shoelace formula gives negative area if vertices are given in clockwise order, so you may want to add absolute value signs around the formula if you want 'no special cases'.
Apologies, read ahead to pg. 271, where the ambiguity is cleared up. Ignore the above, and here come the downvotes :)
13.1 Bellman–Ford algorithm
I think the graph in your example should be directed, see this answer. Thank you.
That's a good point and it's on my to-do list to fix this. Indeed, the current example graph is misleading.
It would be great if someone shares an ideal 20-page Cookbook for ACM ICPC Regional.
All the ICPC Regional contests are widely different. For example, NEERC is much harder than a random US regional.
Your iterative union-find find function doesn't flatten the tree, making it slow on average, you have:
int find(int x) { while (x != link[x]) x = link[x]; return x; }You should use a recursive one which flattens it:
int find(int x) { if (x == link[x]) return x; return link[x]=find(link[x]); }The implementation given has worst case O(logn) operations, which while slower than inverse Ackermann, isn't slow on average.
I asked pllk a long time ago why he had this version of union-find in the book, and if I remember correctly, he said that he prefers having the log(n) version in the book since it's a bit simpler, and the complexity of the other version is hard to analyze.
This is kind of odd, since for some problems using his version might TLE over the other and also the flatten version is also worst case log(n) on first call, every next on same index is constant. Other than that the book is great and learned a lot!
Yeah but even the O(log n) implementation in the book is really fast.
I always use that implementation when competing. If I'll ever get TLE because of that, I will definitely change my mind :)
I have been using your version since I got TL in this problem:
TL 5
AC
There is one special case of DSU where that flattening step must be intentionally avoided: In constructing persistent DSU.
Thanks for your work.
Here's the link for the online version of the book.
Competitive Programming
EDIT: My bad, if (S&(1<<k))>0 then partial(S^(1<<k),k)==partial(S^(1<<k),k-1), as S^(1<<k) has kth bit not set, so the k iteration didn't do anything so it's same as (k-1) iteration.
PRE-EDIT: Once again a great book! On page 105, you show the recurrence of partial(S,k) = partial(S, k-1) + partial(S^(1<<k), k-1), but that last term seems to be partial(S^(1<<k),k) in your code on the next page since you use only one array sum, and S^(1<<k) is smaller than S, so it is already calculated for k, not k-1. Which is right here?
Is the final version of the book available? pllk
Yes, he finished the book. He changed the name of the title, but you can see by the name of the author that is him.
you can buy via Amazon here.
How do I know -> Source.
I really appreciate your help. Thank you.
pllk Hey! I want to buy this book. How and where can I get it?
I live in Bangladesh. Is there any way of buying this book in Bangladesh?