


Tutorial is loading...
Setter's code
int n, k, s = 0;
cin >> n >> k;
for (int i = 0; i < n; ++i) {
int x;
cin >> x;
s += x;
}
for (int ans = 0;; ans++) {
int a = 2 * (s + ans * k);
int b = (2 * k - 1) * (ans + n);
if (a >= b) {
cout << ans;
return 0;
}
}
First accepted Zhigan.
Tutorial is loading...
Setter's code
for (int i = 0; i < n; i++) {
cin >> k[i] >> l[i];
a.push_back(make_pair(min(2 * k[i], l[i]) - min(k[i], l[i]), i));
}
sort(a.rbegin(), a.rend());
long long ans = 0;
for (int i = 0; i < f; i++) {
int pos = a[i].second;
ans += min(2 * k[pos], l[pos]);
}
for (int i = f; i < n; i++) {
int pos = a[i].second;
ans += min(k[pos], l[pos]);
}
cout << ans;
First accepted polygonia.
Tutorial is loading...
Setter's code
st[0] = 1;
for ( int j = 1; j < maxn; j++ )
st[j] = ( 2 * st[j - 1] ) % base;
int n;
scanf ( "%d", &n );
for ( int j = 0; j < n; j++ )
scanf ( "%d", &a[j] );
sort( a, a + n );
int ans = 0;
for ( int j = 1; j < n; j++ ) {
int len = a[j] - a[j - 1];
int cntL = j;
int cntR = n - j;
int add = ( 1LL * ( st[cntL] - 1 + base ) * ( st[cntR] - 1 + base ) ) % base;
ans = ( 1LL * ans + 1LL * len * add ) % base;
}
printf ( "%d\n", ans );
First accepted div2: RaidenEi.
First accepted div1: Lewin.
Tutorial is loading...
Setter's code
int query(int x,int y){
if(x==-1)return 0;
cout<<1<<' '<<x<<' '<<y<<endl;
string ret;
cin>>ret;
return ("TAK"==ret);
}
int get(int l,int r){
if(l>r)return -1;
while(l<r){
int m=(l+r)/2;
if(query(m,m+1)){
r=m;
}else l=m+1;
}
return l;
}
int main() {
int n,k;
cin>>n>>k;
int x=get(1,n);
int y=get(1,x-1);
if(!query(y,x))y=get(x+1,n);
cout<<2<<' '<<x<<' '<<y<<endl;
return 0;
}
First accepted div2: polygonia.
First accepted div1: V--o_o--V.
Tutorial is loading...
Setter's code
ll dp[32][2][2][2];
ll sum[32][2][2][2];
void add(ll &x,ll y){
x+=y;
if(x>=mod)x-=mod;
}
void sub(ll &x,ll y){
x-=y;
if(x<0)x+=mod;
}
ll mul(ll x,ll y){
return x*y%mod;
}
ll pot[32];
ll solve(int x,int y,int z){
if(x<0||y<0||z<0)return 0;
memset(dp,0,sizeof dp);
memset(sum,0,sizeof sum);
vi A,B,C;
rep(j,0,31){
A.pb(x%2);x/=2;
B.pb(y%2);y/=2;
C.pb(z%2);z/=2;
}
reverse(all(A));
reverse(all(B));
reverse(all(C));
dp[0][1][1][1]=1;
sum[0][1][1][1]=0;
rep(i,0,31){
rep(a,0,2)rep(b,0,2)rep(c,0,2){
rep(x,0,2)rep(y,0,2){
int z=x^y;
if(a==1&&A[i]==0&&x==1)continue;
if(b==1&&B[i]==0&&y==1)continue;
if(c==1&&C[i]==0&&z==1)continue;
add(dp[i+1][a&(A[i]==x)][b&(B[i]==y)][c&(C[i]==z)],dp[i][a][b][c]);
add(sum[i+1][a&(A[i]==x)][b&(B[i]==y)][c&(C[i]==z)],sum[i][a][b][c]);
add(sum[i+1][a&(A[i]==x)][b&(B[i]==y)][c&(C[i]==z)],mul(z<<(30-i),dp[i][a][b][c]));
}
}
}
ll res=0;
rep(a,0,2)rep(b,0,2)rep(c,0,2){
add(res,sum[31][a][b][c]);
add(res,dp[31][a][b][c]);
}
return res;
}
int main(){
int T;
cin>>T;
while(T--){
int x,y,x2,y2,k;
cin>>x>>y>>x2>>y2>>k;
--x;--y;--x2;--y2;--k;
ll res=0;
add(res,solve(x2,y2,k));
sub(res,solve(x2,y-1,k));
sub(res,solve(x-1,y2,k));
add(res,solve(x-1,y-1,k));
cout<<res<<'\n';
}
return 0;
}
First accepted div2: xsup.
First accepted div1: anta.
Tutorial is loading...
Setter's code
struct node {
int prior, sz, dp, add;
node *l, *r;
node ( int x ) {
prior = ( rand() << 15 ) | rand();
// sz = 1;
dp = x;
l = r = NULL;
add = 0;
}
};
typedef node * pnode;
void push( pnode T ) {
T -> dp += T -> add;
if ( T -> l )
T -> l -> add += T -> add;
if ( T -> r )
T -> r -> add += T -> add;
T -> add = 0;
}
void merge( pnode &T, pnode L, pnode R ) {
if ( !L ) {
T = R;
return;
}
if ( !R ) {
T = L;
return;
}
if ( L -> prior > R -> prior ) {
push( L );
merge( L -> r, L -> r, R );
T = L;
return;
}
push( R );
merge( R -> l, L, R -> l );
T = R;
}
void split( pnode T, int value, pnode &L, pnode &R ) {
if ( !T ) {
L = R = NULL;
return;
}
push( T );
if ( T -> dp >= value ) {
split( T -> l, value, L, T -> l );
R = T;
return;
}
split( T -> r, value, T -> r, R );
L = T;
}
int findBegin( pnode T ) {
push( T );
if ( !T -> l )
return T -> dp;
return findBegin( T -> l );
}
int findMax( pnode T, int n ) {
if ( !T )
return 0;
push( T );
return findMax( T -> l, n ) + findMax( T -> r, n ) + ( T -> dp <= inf ? 1 : 0 );
}
pair < int, int > a[maxn];
pnode T = new node( 0 );
pnode L = NULL;
pnode M = NULL;
pnode R = NULL;
pnode rubbish = NULL;
void solve() {
int n;
scanf ( "%d", &n );
for ( int j = 1; j <= n; j++ )
scanf ( "%d%d", &a[j].f, &a[j].s );
for ( int j = 1; j <= n; j++ )
merge( T, T, new node( inf + j ) );
for ( int j = 1; j <= n; j++ ) {
split( T, a[j].f, L, R );
split( R, a[j].s, M, R );
if ( M )
M -> add += 1;
int cnt = findBegin( R );
split( R, cnt + 1, rubbish, R );
merge( T, L, new node( a[j].f ) );
merge( T, T, M );
merge( T, T, R );
}
printf ( "%d\n", findMax( T, n ) - 1 );
}
First accepted: ksun48.
Tutorial is loading...
Setter's code
#include <functional>
#include <algorithm>
#include <iostream>
#include <fstream>
#include <cstdlib>
#include <numeric>
#include <iomanip>
#include <cstdio>
#include <cstring>
#include <cassert>
#include <vector>
#include <math.h>
#include <queue>
#include <stack>
#include <ctime>
#include <set>
#include <map>
using namespace std;
typedef long long ll;
typedef long double ld;
template <typename T>
T nextInt() {
T x = 0, p = 1;
char ch;
do { ch = getchar(); } while(ch <= ' ');
if (ch == '-') {
p = -1;
ch = getchar();
}
while(ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * p;
}
const int maxN = (int)2e5 + 10;
const int maxL = 17;
const int INF = (int)1e9;
const int mod = (int)1e9 + 7;
const ll LLINF = (ll)1e18 + 5;
int mul(int x, int y) {
return 1LL * x * y % mod;
}
void add(int &x, int y) {
x += y;
if (x >= mod) x -= mod;
}
void sub(int &x, int y) {
x -= y;
if (x < 0) x += mod;
}
int n;
vector <int> g[maxN];
vector <int> d[maxN];
vector <int> coefs[maxN];
int phi[maxN];
int inv[maxN];
int a[maxN];
int tmp[maxN];
void productToTmp(int a, int b) {
for (size_t it = 0; it < d[a].size(); it++) {
for (size_t jt = 0; jt < d[b].size(); jt++) {
int x = d[a][it];
int cx = coefs[a][it];
int y = d[b][jt];
int cy = coefs[b][jt];
add(tmp[x * y], mul(cx, cy));
}
}
}
void precalc() {
inv[1] = 1;
for (int i = 1; i < maxN; ++i) {
phi[i] = i;
if(i > 1) inv[i] = mul(mod - mod / i, inv[mod % i]);
}
for (int i = 1; i < maxN; ++i) {
for (int j = i; j < maxN; j += i) {
d[j].push_back(i);
if (j != i) phi[j] -= phi[i];
}
}
for (int i = 1; i < maxN; ++i) {
coefs[i].resize(d[i].size());
}
coefs[1][0] = 1;
for (int x = 2; x < maxN; x++) {
if ((int)d[x].size() == 2) {
coefs[x][0] = 1;
coefs[x][1] = inv[x - 1];
} else {
int lp = d[x][1];
int z = x;
while (z % lp == 0) {
z /= lp;
}
for (int y: d[x]) {
tmp[y] = 0;
}
productToTmp(lp, z);
for (size_t it = 0; it < d[x].size(); it++) {
coefs[x][it] = tmp[d[x][it]];
}
}
}
}
int nodes[maxN];
int len = 0;
int sz[maxN];
int blocked[maxN];
int level[maxN];
int anc[maxN];
void calc_sizes(int v, int p = -1) {
nodes[len++] = v;
sz[v] = 1;
anc[v] = p;
for (int x: g[v]){
if (blocked[x] || x == p) continue;
calc_sizes(x, v);
sz[v] += sz[x];
}
}
int sum_phi[maxN];
int list_len;
int list[maxN];
int depth[maxN];
void get_list(int v, int par = -1, int dpth = 1) {
list[list_len] = v;
depth[list_len++] = dpth;
for (int x: g[v]) {
if (par == x || blocked[x]) continue;
get_list(x, v, dpth + 1);
}
}
int sum[maxN];
int calc(int value) {
int cur = 0;
for(size_t i = 0; i < d[value].size(); ++i) {
int x = d[value][i];
add(cur, mul(sum_phi[x], coefs[value][i]));
}
return mul(cur, phi[value]);
}
int total = 0;
void solve(int root) { //root is a centroid
for (int i = 0; i < len; ++i) {
int u = nodes[i];
int y = a[u];
for (int x: d[y]) {
add(sum_phi[x], phi[y]);
}
}
for (int child: g[root]) {
if (blocked[child]) continue;
list_len = 0;
get_list(child, root);
{
//excluding everything which can be counted twice
for(int i = 0; i < list_len; ++i) {
int u = list[i];
int y = a[u];
for(int x: d[y]) {
sub(sum_phi[x], phi[y]);
}
}
}
{
for (int i = 0; i < list_len; ++i) {
int u = list[i];
int d = depth[i];
int value = a[u];
add(total, mul(d, calc(value)));
}
}
{
//including back
for(int i = 0; i < list_len; ++i) {
int u = list[i];
int y = a[u];
for(int x: d[y]) {
add(sum_phi[x], phi[y]);
}
}
}
}
//clear
for (int i = 0; i < len; ++i) {
int u = nodes[i];
int y = a[u];
for (int x: d[y]) {
sum_phi[x] = 0;
}
}
}
void build(int v, int lev) {
len = 0;
calc_sizes(v);
int centroid = -1;
for (int i = 0; i < len; ++i) {
int u = nodes[i];
int maxChildSize = len - sz[u];
for (int x: g[u]) {
if (x != anc[u] && !blocked[x]) {
maxChildSize = max(maxChildSize, sz[x]);
}
}
if (maxChildSize <= len / 2) {
centroid = u;
}
}
blocked[centroid] = true;
level[centroid] = lev;
solve(centroid);
for (int x: g[centroid]) {
if (blocked[x]) continue;
build(x, lev + 1);
}
}
int main() {
// freopen("input.txt", "r", stdin);
// freopen("output.txt", "w", stdout);
ios_base::sync_with_stdio(0);
precalc();
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> a[i];
}
for (int i = 1; i < n; ++i) {
int x, y;
cin >> x >> y;
--x; --y;
g[x].push_back(y);
g[y].push_back(x);
}
build(0, 0);
total = mul(total, inv[n]);
total = mul(total, inv[n - 1]);
total = mul(total, 2);
cout << total << endl;
return 0;
}
First accepted: radoslav11.






O(1) solution is possible for 810A. Link
My shorter, haha. http://codeforces.net/contest/810/submission/27240056
it's good to mention the First accepted
In "809 A — Do you want a date?", the last line of explanation says
2**(i-1) * 2**(n-i-1). I believe it should be(2**i - 1) * (2**(n-i) - 1), i.e. make sure at least one of[1, i]gets picked, and at least one of[i+1,n]gets picked.Those subsets are allowed to be empty.
x[i+1] - x[i]is added to final answer for all those subsets where there is at least one integer picked from[1,i]and at least one integer picked from[i+1,n]. Note the closed intervals, and the fact that the implementation of the solution is doing what I described.Yea, you are right, I will fix editorial soon.
Oh, OK. I misinterpreted the ranges you were considering.
I really don't understand the explanation: if a subset s contains xi and xi + 1 and also contains other two points xa been a ≤ i and xb been b ≥ i+1, as points are sorted xa < xi < xi+1 < xb by definition of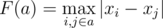 then F(s) = | xb — xa |
then F(s) = | xb — xa |
Can someone help me here ?
I meant that I'm dividing the whole range a, a + 1, ..., i, i + 1, ...b in edges between neighbours, so the answer is xb - xa = (xa + 1 - xa) + (xa + 2 - xa + 1) + ... + (xi + 1 - xi) + ...(xb - xb - 1). We add each part separately.
anti-quicksort test ??? seriously ???
Someone can explain me the point of that test cases ?
Java use different algorithms just for memory issues not performance.. :(
This test was added automatically when someone hacked someone's solution, so you should always be careful using sort on java.
It seems that Div1B has weak data.
http://codeforces.net/contest/810/submission/27251518[My submission]
I made some mistakes on edge cases that I can't pass the data
But I didn't fail the system test.How can I add this data?
While the event is in progress, you can challenge, and I am pretty sure that successful challenges are added to final tests (even though I could not find this stated anywhere). I don't think this can be done after the competition ended. One option could be creating a mock competition with that problem, but I am not sure how much you can change the data.
in Div2E / Div1C can anybody prove me that the cell(i , j) is equal to (i — 1) xor (j — 1 ) + 1 ?
The formulation is just an obfuscated form of Nim with two piles.
so ... No prove ?
Can someone link an article about that or care to explain to help us understand that?
Found proof: link
I am unable to understand the solution to Div2E / Div1C mentioned above. Can anybody please explain the solution?
I want to join your demand. Can someone, please, give a reference on any valuable information about this type of problems?
I will briefly go through probably the most confusing part of the code
if(a==1&&A[i]==0&&x==1)continue; // and the two lines followThis line ensures that the X values considered for dp are LT/EQ to X, another way of putting this line is:
if(prefix_is_equal && x > X[corresponding_bit]) then skip this state. //If the prefix is smaller then there are no restrictions to the less significant bits
The state transit below also makes use of the same idea
dp[i+1][a&(A[i]==x)][b&(B[i]==y)][c&(C[i]==z)] // and the two lines followa&(A[i] == x) implies that the equality flag remains true iff prefix is equal AND the current bit is equal.
mul(z<<(30-i),dp[i][a][b][c])Just to add the values of sum according to the XOR value and the significant of the bit.
Just in case, this is a way of querying 2D plane.
If you are interested in trying-out similar questions with similar difficulty I'd recommend 747F.
(These types of DP questions mostly appear as the last Div2 question, it pretty much decides who will be the first of that round as you can see here)
what does the dp and cnt refer to ? same goes for the dp parameters i failed to understand even tho i read the tutorial many times :( can u please clarify :)
dp and sum has the same parameters, namely:
dp[bitmask position][equality flag for x coord][eq flag for y][eq flag for k]
bitmask position (i): we are currently evaluating the value of (1<<i), from the most significant to the least, since ...
eq flags: this represents if the value of {x, y, k} is going to be strictly smaller than our queried upper-bound. If the flag is true, that means we have to be careful of not over-counting stuff because of counting above the upper-bound. If the flag is false, that means the considered value is less than the upper-bound no matter what, so we would consider all transitions.
The only difference between dp and sum is that dp represents the "ways" of reaching this state, and sum is the weighted value of the dp array.
That explains it :D Thx
I have linked a proof for why cell (i, j) has value (i - 1)xor(j - 1) + 1 above.
Let's make a function sum(i, j, k), which gives the sum of all integers less than or equal to k that are in the upper-left i * j fragment of the matrix. We can use that to calculate the answer for any fragment.
Sum for fragment (x1, y1, x2, y2) is equal to sum(x2, y2, k) - sum(x1 - 1, y2, k) - sum(x2, y1 - 1, k) + sum(x1 - 1, y1 - 1). If you don't know why, research "2D prefix sum."
How do we compute the answer for that function efficiently?
Let's come up with an algorithm for computing sum of all x xor y, such that for each x and y such that x ≤ a and y ≤ b and (x xor y) ≤ k. Using that we can easily compute value of sum().
Let's define dp function bt() which will compute that value for us (we'll add arguments to that function one by one when we need them). For computing the value, let's add binary digits to possible values of x xor y one by one, starting from the most significant bit. Let's add argument i to function bt(), which is the index of the digit we're currently adding.
Now, for every digit i, there are 4 possibilities: we make the ith bit of x 0 and of y 0 resulting in 0 for (x xor y), or 1 and 0 resulting in 1, or 0 and 1 resulting in 1, or 1 and 1 resulting in 0.
But how do we know which of these possibilities is valid (i.e. doesn't result in exceeding the limit for x, y, or (x xor y))?
Suppose we're adding bit 1 at index i in x (while adding bits one by one from most significant to less significant), which initially doesn't exceed a.x would exceed a if and only if we're adding bit 1 at index i, while the ith bit of a is 0, and suffix starting from bit i + 1 of x in binary representation is equal to suffix starting from bit i + 1 of a in binary representation. UPD: by suffix, I mean bits with index i+1 through MAXLOG, which can also be viewed as prefix depending on how you visualize it. I'll call it suffix in this post. By ith bit, I mean bit (1 << i). If it's unclear for you why that's true, here's an example:
In the above example, we can't add 1, because x would become bigger than a. Note that in this case suffix in a (11011) is equal to suffix in x (11011).
Another example:
Here, we can safely add 1 without making x exceed a. That is because suffix in a (11011) doesn't equal suffix in x (11001).
The same goes for y with b and for (x xor y) with k.
Thus, we only need to keep track of whether the suffix of x currently equals suffix of a, same for y and k. Thus we add 3 boolean arguments to bt, which becomes bt(i, sufA, sufB, sufK).
Back to the four possibilities: Pairs (1, 0) and (0, 1) result in 1, thus add to answer (1 << i)*numberOfCellsIn(i - 1, newSufA, newSufB, newSufK)*bt(i - 1, newSufA, newSufB, newSufK). Pairs (0, 0) and (1, 1) result in 0, thus just add tp the answer numberOfCellsIn(i, newSufA, newSufB, newSufK)*bt(i - 1, newSufA, newSufB, newSufK).
We can compute numberOfCellsIn in a fashion similar to bt().
You can check my code if it's unclear how to compute newSufs. Also check out my code for how to apply that for computing answer of sum, since I'm too lazy to finish this tutorial and I think I already explained the confusing parts and the rest is easy.
Note that the dp does $lg(max(a, b,y))*2*2*2
operations, which is sufficient to solve the problem as there are only 10^4 queries.
My code is too long because I made functions numberOfCellsIn and bt separately, but I think that only makes it clearer.
Hope that helps
I am very grateful to you. It realy helps.
However,
Why cant I add 1 at this place and follow it up with 0 afterwards?
I'm sorry, that should have been reversed, and it should be called prefix instead of suffix. The most significant bit is on the left instead of the right. I'll fix this
EDIT: Updated
last problem of div 2 explained so easily. thanks
27270104 This is my submission to div1 A and it gets wrong answer can someone help please
When you write
ans += (arr[i] * ( (b-c) % mod ) ) % mod;modulo operation is performed only for(arr[i] * ( (b-c) % mod ) )part. Soansis still without moduloThanks
Here is the modified version of your code. 27270623
Thanks
Hey! I tried the problem 809A but got wrong ans.Please can someone suggest what I did wrong?
Code:
#include<bits/stdc++.h> #define MAXN 100010 #define pb push_back #define mp make_pair #define ll long long #define mod 1000000007 using namespace std; int cmpfunc (const void * a, const void * b) { return ( (int)a — (int)b ); } int main(){ int n,sum=0,power=1; cin>>n; int arr[n]; //set arr:: iterator it,it1; for(int i=0;i<n;i++){ cin>>arr[i]; } sort(arr,arr+n); for(int i=0;i<n-1;i++){ power=1; for(int j=i+1;j<n;j++){ sum+=((arr[j]-arr[i])*(power))%mod; power=(power*2)%mod; } } //it=arr.begin();
cout<<sum%mod<<endl; return 0; // 1 3 4 5 }
It looks like an overflow of
intbut i tried with long long int too but still got wrong ans
You need to do modulo operations each time you do any other operation, cause it can lead to long long overflow otherwise. The real answer for this problem can be as big as 2^300000 is big, so the problem requires to print it modulo 10^9 + 7. Furthermore, your solution is not fast enough for passing all tests.
Thnx for the help! :)
Didn't get the tutorial for 809A/810C. Can someone help ?
Tutorial is very confusing. Here is a much simpler solution:
http://codeforces.net/contest/809/submission/27245918
What we are doing here is adding up the sum of each point and all the pairs it can make to the left. For any point i, when we transition to point i + 1, we must do dp[i + 1] = dp[i] * 2 + (2^i — 1) * (difference between i + 1 and i), where dp[i] represent the answer if i is the right endpoint. (^ denotes exponentiation) This is because we can view this as adding difference between i + 1 and i to all the intervals, and the 2^i — 1 is because we want to extend the leftmost interval by diff so we must multiply diff by 2^(i — 1) and the leftmost + 1 interval by diff * 2^(i — 2)... and so on, which adds to 2^i — 1.
I don't quite understand how does the randomly generated prior value of a node helps maintaining the treap while merging in the implementation of Div1D, would someone mind explaining it to me?
If you are using classic binary tree, its depth could be O(n), if the values come in sorted order. When you are randoming priorities and use them while merging, your depth of tree would be O(logn)
Ah, I see. That's much more faster to code compared to the spin method.
In 809C , can someone help to prove that number in (i,j) is [(i-1)XOR(j-1)]+1 ?
The position (i, j) could be regarded as two nim stacks with size of (i-1, j-1), thus the mex value of the set {(a, j) | a < i} + {(i, b) | b < j} is equivalent to the grundy value of the nim state (i-1, j-1), i.e. (i-1) ^ (j-1), plus 1.
(Search grundy theorem to learn more about the "grundy value")
Perfect ! Thanks so much.
In Problem Div2C/Div1A, we can also count the number of times xi is added and is subtracted from the result. Consequently, the answer becomes the sum of
xi * (2^i - 2^(n-1-i)) for i=0,..,n-1.That's right . I solve it this way , too.
Can someone help me debug this code: This code is for "Do you want a Date?" problem. I am getting the wrong answer for test case 6. This will be a great help.
In line 13
1<<varmay cause overflowIt's still not working after considering 1<<var. here is updated one. btw thanks for helping:)
i<(pow(2,var))Brute-forcing every possible subset is not feasible as you have to consider all 2^(3*10^5) sets, which is going to take a whole bunch of time. You should rethink your strategy a bit. =)
For 809B, the editorial states:
So we always know in which of the halves [l, mid], [mid + 1, r] exists at least one point.
Why is this statement true?
Because if the half doesn't contain a point, it won't give us information, that the closest point is closer than in a half with a point. Why? Because any point in the interval is closer, than any point out.
In the solution of Div1 E.Can you tell me how to prove the formula about the coefficients of C ??? Thanks :)
Hi guys!
I made a video editorial on the problem 'Glad to meet you'. I couldn't solve it during the contest, so I had to get back at it somehow. :-)
We use binary search to find the two points.
Here is the link: Div 415 — Glad to Meet You
Why did 2B disappear? The problem seems to be removed, and tutorial is not available now.