


Throughout the year, Google Code Jam hosts online Kickstart rounds to give students the opportunity to develop their coding skills, get acquainted with Code Jam’s competition arena, and get a glimpse into the programming skills needed for a technical career at Google.
Inviting you to solve some fun and interesting problems this Sunday, March 18, 2018 05:00 UTC – 08:00 UTC.
Link to contest dashboard
Problem analysis will be published soon after the contest.






A gentle reminder, the contest is about to start in 1:30 hrs!!! GoodLuck to all those who are participating :)
Seems like APAC is still using the old way of judging solutions: downloading/uploading i/o files. I am saying "old" cause I heard CodeJam will be shifting to the traditional method of submitting source code and running it on their server for judging.
Anyways, since we have to download input and run the solution on our OWN pc, I think this blog post will be helpful: Increase Stack Size in C++ IDE Codeblocks.
This will help you avoid getting Run Time Error while running your solution against large dataset :)
aka "What to do when your solution runs in O(n^3) and there's no time to optimize it to O(n^2)".
Wish I knew this when I first competed in kickstart. :/
May be try using multithreading? Some thing like this: https://github.com/FallAndRise/gcj-templates
By the way, does it come under cheating or unfair?
It doesn't.
I heard that CodeJam will be shifting to new interface while APAC/Kickstart will continue with the same interface this year.
Fingers crossed, I might have submitted the small output for problem B, hopefully I stay at the third place at the end. :/
Edit: Screw it, I won't have 100% score after system test, I ACTUALLY SUBMITTED THE SMALL OUTPUT FOR LARGE OUTPUT
I was in top 30 previous year, but nobody has contacted me. Which score is good enough for interview invitation?
Which round did you participated? Some offices only recruit on certain rounds.
Kickstart Round D 2017 — top 100
Kickstart Round E 2017 — top 30
Can you give more info about round — recruiting office, if you know?
Last year, I got a call for internship at Google India from Kickstart Round C or D I suppose. I scored 75 rank I guess.
please dont say that B was ruined by allowing O(n*k) solutions to pass.
Also is there a determinsitic approach for C without using hashes
Yes. My solution was O(n*k) and it passed. I know, its weird.
what do you mean by "allowing O(n*k) solution to pass"? AFAIK google doesnt run your solution on their servers, only the output is matched with the correct output.
Expected complexity is O(k*logn) right?
Two main motivations to allow O(N*K) to pass were a. optimize for smaller input files and b. binary search not being the main crux of the problem.
Lol. I overkilled the question using convexhulls.I did not notice the easier greedy part. That was the reason I was sad about O(n*k) solutions .Otherwise there is not much in adding binary search.
There is no need of binary search though. You can just keep shifting the x pointer to the right, as Ek is increasing, and so is xk. Can be done O(n logn + k).
How to solve B and C ?
Check out the analysis https://codejam.withgoogle.com/codejam/contest/9234486/dashboard#s=a
So, who else got into the following dilemma: should I solve A using greedy method or digit dp? :p
for C-large, isn't there sth missing in the editorial? How do I find which dict entries match for a certain length and frequency array (in O(1)), hashing with factor 26?
When you move one position to right, frequency of one character increases and that of another decreases. You just account for this change and update the hash. This takes overall O(N) for a particular length.
The value of N is too strict, even my solution which follows same complexity didn't passed because its update involved a few more multiplications and additions.
I don't think so. For large dataset, my code runs in 11s, and we have 8 minutes. Link to code
EDIT : A possible reason for TLE is that when you access map using operator [], you also insert the element and it might increase the size of your map to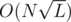 , which is a little too much. For example, if I remove the 61st line from my code, it would give TLE
, which is a little too much. For example, if I remove the 61st line from my code, it would give TLE
Thanks, you are correct. This is the reason why unordered_map was giving TLE in my code.
How can we solve problem B without dp .
Problem A can be solved without implementing both decrease and increase case. I'm surprised that this is not mentioned in the editorial. This trick is really important to reduce complex implementation.
When you implemented decrease case as solve(n), you can calculate increase case by solve(8888888888888888 — n).