


Hello!
I'm glad to invite you all to Round 485 which will take place on Tuesday, May 29 at 18:35 UTC+3.
There will be 6 problems in each division, 3 of them are shared between divisions. 2 of div.2 problems created by KAN, 7 others created by me. The contest duration is 2 hours. My problems were originally used in HSE Championship.
I would like to thank Merkurev and GlebsHP with whom I discussed the problems, I_love_Tanya_Romanova for testing, KAN for round coordination and Codeforces and Polygon team for these beautiful platforms. I would also like to thank HSE for organizing the event. Oh, and kb. for writing great legend for one of the problems (he will be surprised).
For those who for some reason like to know score distribution in advance:
div.2: 500 — 1000 — 1250 — 1750 — 2250 — 3000
div.1: 500 — 1000 — 1750 — 2500 — 2750 — 3000
But I didn't properly discuss it with KAN so this is subject to change :)
UPD: Discussed with KAN, scores for C and D in div.2 increased by 250.
Good fun, have problems, read all the luck. As usual.
Oh, and if there will be no bad things, round will be rated. I hope.
I'm very sorry for issues with queue. I understand that it could ruin the contest for many of you. But please be understanding. Bad things happen. It could be some network problems or some electricity problems. MikeMirzayanov, KAN and other people behind Codeforces trying their best to provide good service. But sometimes it's very hard for some reasons. I hope that you enjoyed the problems despite all the bad things.
We decided that round will be rated.
Editorial will be posted tomorrow.
div.1 winners:
1. tourist
2. jqdai0815
3. Radewoosh
4. webmaster
5. LHiC
div.2 winners:
1. sminem
2. Fortza_Gabi_Tulba
3. cheburazshka
4. Lomk
5. 2ez4me
Editorial is up.







Good fun, have problems, read all the luck. As usual. Love how the words were jumbled and at last as usual :P.
Meow ! :)
bow wow XD
And also thanks to MikeMirzayanov for systems Codeforces and Polygon:)
Bot test comment .
meooow hello.
Dont forget to add me in contributors.md
KAN is my favorite
If KAN didn't invent easy tasks, we would have div 1 only round :D
No, you would have bad div.2 round :)
B and C in div2 have the same score ,Will they have the same difficulty ?
yes
too many spoilers
I don't think so.
For those wondering, there are 31 spoilers.
I counted 32...
Spoiler limit exceeded
thanks
it is 32
Huseyn_Hajiyev You really spoiled the thing.
Good Question. And nice observation.
could you please make the start time a 1 hour earlier (at 17:35 Moscow time) . we in egypt have fast breaking at (19:35 Moscow time) as we fast in this month from dawn to sunshine every day so we won't be able to compete :-). like if you agree
Every hour there is muslims have fast breaking , not only in Egypt, i think that is the main reason for ones who downvoted your comment
GOOOOD LUCKK 4 EVERYONE :з
on 11-th line it is incorrect to say i didn't discussed because did is always followed by a verb in PTS(present tense simple)
*in infinitive
Nice catch. Thanks. Fixed.
discuss not discusse :)
Ok then, you should say "If there are no bad things, round will be rated", cause it's first conditional.
2 of div.2 problems created by KAN, 7 others created by me
should be
2 of div.2 problems were created by KAN, 7 others were created by me
successful hacking attempt +100
My comments will have more downvotes than upvotes on this post. Do Down Vote.
Two hours and we have problems worth 1750, 2500, 2750 and 3000. Is that best choice of duration?
I just think that standard distribution is bad because you usually solve C on 0:30 and E on 1:55 -> they give the same points. Also we added easy problem so we had to increase scores of other problems. So, yes, I think that the difficulty is comparable to "average round" whatever that means. But I may be wrong :)
That's the answer I wanted to hear (y)
I think you read it :)
but he wanted to hear
you know you are on CF, when the red gets +40 for stealing your joke, while you get -20. you guys really don't know how to apply your logical reasoning outside solving useless problems
But maybe I wanted the very Um_nik to whisper it gently to my ear, but somehow stopped desiring it the moment whe he replied here to me? Hm? Have you ever thought about it?
I just wrote my opinion: I think you read it :)
I'm just writing my opinion: I think you should shut the fuck up.
KAN gives t-shirt winner in the contests.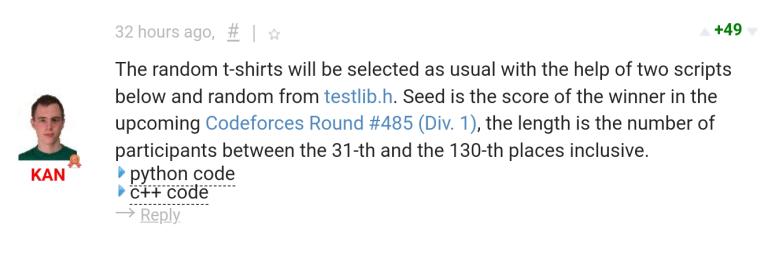
So rating 1953 will be rated in division 2?
No, purple coders will be rated in Div1 as before. Nothing has changed for Div1 rounds.
Just that purple coders can now officially participate in Div2 — only rounds (today's round is Div1 + Div2 so they are rated in Div-1).
I hope there are no problems from Graph Theory.
Really??? I hope all problems will be related to Graphs. They are great!
Indeed , I love Graphs !
Very, very true ! I think all the problems will be great, not only the graph ones ! Anyway, there is no perfect contest if no graph problems or problems that are solved using data structures based on graphs are included !
Oh, and kb. for writing great legend for one of the problems
Hope that's the only problem with legend :(
Oh, and if there will be no bad things, the round will be rated. I hope. :D :D :D
Nice statement.
Where can I see problems of past HSE editions?
HSE is the university I attend. I made a championship for its students. As far as I know that was the first one.
Happy to see you in the list of top contributors.
I hope tourist will regain His position after this contest
I also feel so.
Petr rlz!
hacks window not opening. -_-
terrible queue :(
20 pages of queue...
30 now ... :(
50 now
What happened?
smells like unrated round :'(
That's terrible!
queue:(
Extend the contest.
So Long Queue I guess Codeforces need to work on that, so that it occurs less often... Please See to that Admin.
queue is gone
in div1 still 5+ pages
After waiting 10 minutes for my solution to be judged I found out, I printed "um_nik" instead of "Um_nik".
And I declared array of size of 10^5 !!!
Submissions in queue!
Oh, and if there will be no bad things, round will be rated. I hope.
Yeah, you jinxed it right then...
if there will be no bad things, round will be rated. I hope.
After waiting for 20 minutes my solution starts being judged, passes 9 pretests, and then...Voila!!! It's "in queue" again!!! WTF is that???
So, we have to wait more than 20 minutes for verdict, but time is extended only 10 minute. Is it fair?
Codeforces is crashed again and again and again. In queue ........ (20+ minutes later) Compile Error (because of different version of C++)
Another semi-rated round? lol
is it rated?
It should not be rated as many submissions(more than 40 pages) remained in queue even at the end of the contest.
after a long time i see a comment "is it rated?" and that have upvotes (Wow)! :D
Nothing personal, but round must be unrated
Submissions after 1:30 was in queue even after a long time after contest’s end
Longest queue ever -_-
I beleive u r new to cf
I beleive u r new to cf
I believe you have poor internet connection.
No, but my laptop is lagging too much today.
The most stupid thing ever:
Ouputted "Alex" instead of "Um_nik".
Aaaaah, so this is why I got WA #3. Shit :D
How to solve E?
Basically the question is about checking whether a permutation is odd or even. If there are c disjoint cycles in a permutation, then the permutation is even if n-c is even, and odd if n-c is odd.
(Source)
My solution was on based on the fact that if that if there are n swaps to change an array then we can't do the same with x swaps if parity_x != parity_n. So I counted the number of swaps in bubble sort same as number of inversions in an array and checked its parity with n. If same, ans if Petr else Um_nik
The round was really good until Problem E appeared, it is bad problem and made the queue completely full
I thought I (most probably) solved four problems (Div 2 A,B,C,D) and would be blue within this month but this is how my hope is dashed :'(
seems unrated to me :(
CF don't feels so good
how to solve Div2-D?
A multisource BFS will do the job.
can you please explain it a little more?
Just push every starting vertex into queue, and do normal bfs.
In a normal bfs, you put initially in the queue just one nod. In this problem you must put all nodes that have the same color, and run the bfs for each color.
I am unable figure out the intuition behind it. If u don't mind can you please elaborate? thanks !
We can get the distance from every point to it's nearest source of each color. After that, sort it for every point and add the first s elements together.
You need to compute a matrix like this:
dmin[i][j]-> minimum distance from node i to the closest node with color j.If this matrix is computed, we can find the anser by sorting each vector
dmin[i]and taking the first s values.This matrix can be computed using the bfs described above ;)
I based my solution on the fact that k is small (<=100), so an O(n*k) or similar solution is feasible. Basically, we can just let an array
least[n][k]be the minimum distance to node n for good of type k. We can fill these array by using k BFS, one for each color. Then for each node i, we can just take all the distancesleast[i][k]for 1..k and then select the s smallest.Note that k is at most 100. Therefore, we can try the following:
Denote dist[i][j] as the minimum cost of town i to get a good j from any town.
For each type of good i, push all x such that ax = i into a queue, and set dist[x][i] = 0. Then, we do normal BFS to update the dist array. This has O((n + m)k) time complexity.
Then we find the sum of s smallest elements in dist[i] for each i from 1 to n, which can be done by sorting.
It's now the end of the contest but my solution from 1:38 is still in queue now. I did Mo's algorithm and how can I be able to now if my block size is not optimized? And how can I even debug my solution if I get a WA. I spent my whole contest doing this...
UPD : I got RTE with the very first sample test which ran fine on my computer now. :/
UPD2 : I should write idx[NP + 1] instead of idx[NP]. Really...
Should a k*(n+m) solution pass Div 2 D?
If so, could someone tell me what's wrong with mine?
Solution here (in Java): http://codeforces.net/contest/987/submission/38744336
I think 'Collections.sort' is too slow to pass tests with big constraints.
Dang, I was hoping klog(k) in the sort wouldn't matter that much. How could I get the s smallest values in the list without sorting?
You are sorting the costs. -> therefore you have an additional log factor.
How do we get the k smallest without sorting the costs?
The selection algorithm does it in linear time.
Thanks! Even partial_sort is good!
Was it slow or my internet connection became slow at the last few minutes??? :o
BTW. How to solve problem C?
I used dp there.State of my dp were dp[n][2],dp[i][0] tells me what is the minimum cost in which I can select two displays(k and i) such that s[k]<s[i] and k<i. Now my dp[i][1] tells me the minimum cost in which i can select three displays such that the condition is satisfied therefore dp[i][1]=min(dp[k][0]+cost[i]) for all k<i such that s[k]<s[i]. Hope that it helped a bit :)
CF was slow for me also! C can be done by Dynamic Programming.
For every display i (i from 2 to n), find the display
x[i](x[i]fromi + 1ton) thats[x[i]] > s[i]and has the smallest price (you can do it with 2 'for' iteration. Then you run 2 'for' iteration(i = 1 to n - 2)(j = i + 1 to n - 1), updatereswithmin(res, c[i] + c[j] + c[x[j]]).resis the result.Sorry, guys :(
I completely has no idea what happened. One network service unexpectedly started to be slow (first time ever!). Probably, because of network/system issues. I worked hard since noticed an issue, but without any progress.
This fail is completely surprising for me (
Sorry, Um_nik. I hoped as much as you to host a great round. Very upset about the situation.
I continue to investigate the situation.
is it rated?
Make it unrated .
"Oh, and if there will be no bad things, round will be rated. I hope."
are system down and long queue considered as bad things?
Woah! Hey, Nobody mentioned that ranklist will be frozen during the last hour. Was away from cf for sometime, when did they introduce that?
My question is still in queue!??
Lol my hack is still in queue. Just a suggestion, for div2C a bonus problem can be included where n<=10^5. Just like Round 350. How to solve it in O(nlgn)?
I don't know about O(n) but u can do O(nlogn) using Segtree
Sorry edited my comment. O(n) might be impossible. How to do it in nlgn using segment tree?
U got the n^2 dp ri8? dp[i][j <= 3] = min cost with j elements in increasing order.
So dp[i][j] = c[i]+min(dp[k][j-1]) where a[i] > a[k],i > k
Make a segment tree for each j, keep updating seg[leaf a[i] or whatever] by c[i]. Now take min 1..a[i]-1 as query
Can the dp be formulated as dp[i][j] = minimum cost obtained upto position i with maximum size being at index j?
I tried doing this way but got WA on pretest 7. Am I doing some mistake?
You can use Fenwick tree with minimums
54 pages of queue right now. Make it Unrated please.
For D, I understand the solution is basically "find the smallest power of 3 >= N, N/2, N/4". But how can I find that power for constraints that are this insanely large? Even if I know the exponent and want to check if N isn't just a little bit larger/smaller than that power of 3, it seems impossible with these constraints...
Also, I can't post this comment, CF is broken again.
Fast exponential + FFT for multiplication seem reasonable.
So that's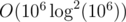 plus the not-very-great constant factor of FFT? Note that I wrote "with these constraints".
plus the not-very-great constant factor of FFT? Note that I wrote "with these constraints".
Well okay, fair enough. At least there are accepted solutions like that. Also my solution works in >10 sec. and I hope that's not the intended solution.
You should estimate logarithm by something like length * log(10) / log(3) and check constant number of integer values close to it (by computing this power for smallest of numbers we want to check, let it be (length — 1) * log(10) / log(3) — 1) and then try multiplying it by 2, 3, 4 in desired manner. You should group digits in some blocks to make it pass in TL with FFT exponentation (what I haven't done).
Complexity of this is something like multiplying two polynomials on degree 200000 once. Note that in binary exponentation, in terms of complexity I can ignore all multiplications except last one because length grows two times with every step.
Yes, I know I should estimate log, so I can check only ceil(log) and possibly ceil(log)-1 if the fractional part of ceil(log) is close to 0. Note that I wrote "want to check if N isn't just a little bit larger/smaller than that power of 3".
If FFT exponentiation is actually the official solution, then this problemset would have massively benefited from having D removed from it. In that case, there wouldn't be any problems with stupid constraints, any boring problems (AFAIK), any problems that are only hard because of bigints, any FFT (AFAIK), the contest difficulty would be more appropriate for 2 hours...
I tried submitting in the last 20 minutes . but it only showed queued . Make the contest unrated. Its not fair .
I cannot understand the statement in Div1D.. :(
ID is not a number, it — is an array of [a1, a2, .. am]. good luck.
For example: n = 36, m = 3 b[] = { 3, 3, 4}
so number of different arrays are:
{ 1 , 1, 1 }
{ 1, 1 , 2 }
{ 1, 1, 3 }
{ 1, 1, 4 }
{1, 2, 1}
..........
{3, 3, 4 }
Total number of such arrays equal to 36.
It might be better give an example as usual in other problem. I really confused what ID refers *_*
How to solve Div2-F or div1-C?
Still queuing the contest should be unrated.
I feel stupid... for not solving B. Don't think I even have a valid clue -___-
D is easy to reduce to calculate ceil(log3(101.5e6)). Is it well-known?
Round is still rated? That's unfair. 30+ minutes queue at the end.
Atleast make it "semi-rated".
yep, yep, you are right it must be FunRated
And people started to think it "unrated". Then came the announcement! ;)
No, it's not like D was everywhere million times, no. However this time with bonus in form of bigints. Yesterday I was making fun of Radewoosh reminding him how he got TLE on bigints because he used them in base 10 last time when Um_nik was a problemsetter. Today I did the same in D...
Me trying to understand this comment
Some nutella things
i hope to live enough to discuss a problem with them
We all hope :(
OK, slowly. Um_nik set this problem in the past: http://codeforces.net/contest/756/problem/E and it required bigints. Radewoosh more or less did this problem, but calculated bigints in decimal base instead of base 1e9 what led to significantly slower time of execution and he got TLE. He whined about this in comments and because of that he was kinda ridiculed by Um_nik for using base10. I reminded this situation yesterday to Radewoosh and laughed about it, but today I did the very same mistake.
if i never solved the problem, this can't happen to me
Maybe I just hate you guys :)
I hope that it didn't ruin the contest for you (maybe some other things did haha).
This is not a very glorious problem, but I think I am more angry at myself than at you. I think F is a very good problem, too bad I didn't have time to fully appreciate it. And B and C were cool as well.
Thanks :)
I agree that D is not very fresh, but bigints also require some small ideas (but yeah, more implementation).
So you wrote this comment not to let Radewoosh write it?
Is it correct for E?
n = 2 2 1 ans should be "Um_nik"
N can be 1000 at least
Key to solve this problem:
Parity of a permutation
Can parity of a permutation be computed using this method: Count minimum number of swaps required to make the array sorted and if it is odd we can say that the permutation has odd parity else even parity. If not then can anyone provide some test case to counter this?
I think your method is correct (Since only the number of swap matter).
http://codeforces.net/contest/987/submission/38747479 Can you tell me whats wrong with this solution ??
The problem was with indexing of arrays :( :(
So if (3*n-x) is even then answer is Petr else Um_nik. Is it?
xuanquang1999, dheeraj_1997 Can you please explain me how did you reduce the problem to finding Parity of Permuation?
To be honest, this is just experience. I learned about parity of permutation in a TopCoder problem. When I meet this problem, I noticed that the parity of the number of swap in Petr and Um_nik are always different, and get reminded of this.
I didn't get this. Can u please explain me how parity for Petr and Um_nik are different, with an example?
Assume that n = 2k + r (k is integer, r is 0 or 1).
Then the parity for Um_nik minus parity for Petr is:
(7n + 1) - 3n
= 4n + 1
= 4(2k + r) + 1
= 8k + 4r + 1
which is always an odd number.
Very end of the contest?:| Really?
Cool trick bro!
Is it even possible to solve Div2D in Java? Very few Java solves on it, and I saw people submitting in Java and then switching to C++ with the same code get accepted.
I had to change my graph representation from List<Integer>[] to int[][] and change sorting algorithm to Egor's ArrayUtils.sort() and it passed systests.
Before doing that I had TL6 like many others. Here is my accepted code: 38738273.
I tried to solve B in the last 30 minutes after trying to solve C all contest. Not getting any feedback was not nice :/
Well at least I can participate in Div2 contests now.
EDIT: the reason my original submit didn't pass was that somehow I thought 3 * n was always even, and compared number of inversions % 2 against 0 instead of n % 2. Well this one is on me.
Despite the issues during the round, i enjoyed the problemset a lot. Thank you guys!
It was a good contest. The problem sets were cool. (Though I was unlucky and completely ruined my contest). Anyway I submitted C n D at the very end n I wish I could know if anything was wrong coz surely i think i could have corrected it. (even with weak pretests as they dont have any corner cases in my opinion)
I think it will be unfair to keep the contest rated (i dont know when the system started to become slow but i submitted my C on 1 hour 40 min n still no verdict).
Are 40 minutes considered as the VERY end of the contest in which the actual rank of the contestant is decided and matters a lot in his rating
General announcement ***** We discussed the issue with the queue and decided that the round will still be rated because the queue only appeared in the very end of the contest. Of course all submissions in queue will be judged. We apologize for the issue and thank you for participation in the round, I hope you liked the problems.
Yeah, right, around 1 hour 35 minutes mark is VERY CLOSE to the ending of a 2-hour contest. Nice!!! Really nice!!!
Can Div 2 C be done better than O(n^2) ?
You can optimize it with Segment Tree or Fenwick Tree, but O(N^2) is enough.
O(N log n) using the segment tree and compression
Precompute (Si < Sj), adjust Si (smaller in range [1..3000] — I dont know how its called in English). in Si, mark the node[s[i]] in segmen tree as Ci, then Query from [Si — 3000]. Every not-filled nodes, mark them as INF.
How can this round be rated? Submissions were not evaluated for more than 30 mins towards the end of the contest. This is really sad.
Проблема возникла в самом конце раунда, да
Примерно четверть раунда в оффлайне, а в остальном все огонь
for problem f, can we do it by creating binary trie? we insert each element in trie (by representing each element in 23-bit format). then for each element, we traverse trie bit by bit. if current bit of current element is set to zero we go either zero edge or one edge, else if it is 1 we can only go towards only zero edge(this way we traverse for all 23 bits of element). if we reach end of trie (while representing elements at last bit, i stored indexs) we can make a pair . then after all elements are done we can do a dfs to check connected components. will it work ?
Lol, the linear algebra class I attend this semester helped me to solve div2E/div1B easily:) Was literally looking into my linear algebra book during the contest
How to solve E?
It's about sign of permutation. Use the fact that
the evenness of number of swap for generating a specific permutation from identity permutation is consistent(i.e.if a permutation is 3 swap away from identity permutation, it can never be generated by even number of swap from identity permutation)
a cycle of length k in permutation is equivalent to k-1 swap (by "cycle", I mean, consider ith number in permutation as "the next node for ith node" like in a graph question)
How to solve C? My brain kinda stopped working after spending nearly entire contest thinking about it.
We can simply rephrase the property "X&Y==0" into "X is submaask of inverted Y". Then simply for each element go through all of it's submasks :)
I think that number of edges is still too big.
Yes, but in the end you go through only O(2^N) states, if you remember the ones you already visited.
We dont need to use DFS or BFS on graph to count answer. Just using DSU and DFS on the mask is fine.
If the number of edges is big, DSU or DFS is still too much.
I agree.
But we are using DFS on the mask, not on the graph. So edges number is about 22 * (2 ^ 22), and vertex number is 2 ^ 22.
I think we can improve it by dividing the vertices in a similar manner to SOS DP
I even cannot submit ( no respond when clicking on the submit button, refreshed a number of times ) during the last minute......
Hi, we apologize for the queue. We discussed the situation with Um_nik and decided to make the round rated because
Thanks Um_nik for great problems and thank you all for participation!
I think it's unfair.There're a lot of solutions for Div.1 E which has a complexity that can tightly fit into the time limit (such as O(n^1.5logn) and O(nlog^2n),even O(nlog^3n)).We don't know whether it fits into TL and can't decide whether to make the program run faster or change to another problem.It will affect participants a lot.
Same for D. I do not know how much this queue affected Div2 Participants, but it was significant for Div1 participants.
I have 4 submissions in Div1D because I did not know whether my solution was efficient enough and I did not get the verdict for a single one.
I even lost my E for being RTE on sample test. What should we do with these undefined behavior cases of compiler without being able to resubmit it?
There are also cases when someone got compilation error and learnt about it long after contest's end xD
I think Rated is an acceptable result.
But I don't like your first reason. It has been stuck for over half an hour. I waited for a long time and receive a MLE, eventually I had no time to fix it. Meanwhile, for those who stuck in the first or two problems, they are very likely to solve two problems in the blocking time if the queue is normal.
Anyway, I think these problems are interesting and Thanks Um_nik and Codeforces.
1) Больше 40 (!!!!!!!) минут не было вердиктов по сабмитам. На кф теперь такие правила? Почему не предупредили перед началом контеста?
2) Может тогда время от времени рандомно давать +-100 к рейтингу каждому, ведь "есть много раундов и рейтинг постоянно меняется"?
I wanted to try D using python (which might be TLE), and in case of TLE I would implement a C++ solution. And I saw lot of people submitting D in python. I think the long queue affected in this way many people...
Beside this, it was a really nice set of problems.
so
30 minute of queue and system down are not considered as bad things.
nice to know it
I remembered similar case happened in round# 449(the long queue was like 30-40 minutes if I remember correctly) and the final decision is to make the round semi-rated. So why is the decisions inconsistent and how to distinguish when to be rated, semi-rated and unrated.
"There are plenty of rounds and the rating always goes up and down, so you shouldn't worry about a slight change that may be caused by the issue.". This was the worst justification I've ever seen LOL
Agreed. I can't believe that I heard this from a large coordinator on Codeforces.
I think that logic can be applied the other way. There will be plenty of contests in the future so it won't matter that much if this one is made unrated.
I submitted 4 solutions (if I had more 5 minutes, it would be 5) at last 30 minutes, and for all of them I didn't see the verdict. Now I see that my F got WA :(
Why so afraid of unrated round? Is it fair to submit several minutes after queue fuckup and receive RE1 because of UB, which can be fixed in 10 seconds? Point on rating going up and down is ridiculous, how the participant should estimate what problem to code if he doesn't know on which point the system is gonna go down? The rating of the comment shows what the audience feels about this, hope CF won't ruin the fun for participants this time.
On the first point: in the announcement it was intended that the queue would resolve before the end of the contest, wasn't it? This ruins completely your first point.
I got MLE on test 15 in div1C. I submitted ~3min after the end of the standard 2 hour round. This is fixable in a minute, but I had no idea it would happen until ~2hrs after the end of the round.
One could argue I couldn't have submitted before the contest ended had the queue worked normally. One could also argue I could have checked if 22·222 > 256·10242. That's irrelevant — I'm arguing that a slow queue for a non-negligible part of the round makes the round unfair.
A few minutes before the end? I could accept your argument (although squinting a lot) because it doesn't mess up a round significantly. Half an hour before the end, or more? No.
Actually there will be at max 12*(2^22) edges, which is nearly 200Mb. What is even bad is that it was really close to memory limit and maybe reusing some vectors would had solved the problem easily.
"so he can test his only problem throughly" — There were quite a few problems with tight TL, and then it's very important to test the running time on CF with the custom invocation. I was impossible because of the big queue.
The decision isn't terrible but I suggest making it unrated next time with similar circumstances.
দ্য হেক!!!!!! কন্টেস্ট রেটেড!!!!???????
আপনাদের কি রোজায় ধরসে?
I have a question. Will we face a penalty for extra submissions, when we didn't know the verdict of previously submitted codes ??
EDIT : I have submitted three codes for E in intervals of 5-10 minutes with some optimization, starting at 1:38, and the first solution has passed pretests. If a non empty subset of the other two pass as well, will it be skipped in system tests with a penalty??
Obviously (not that it makes sense, but it's definitely how the system works). I even think that technically they don't have the means to store the time when you saw the judgement result.
Surely, we will. This is like this on Topcoder in every contest.
I'd be fine with round being rated if you hadn't announced that long queue will be resolved shortly tbh.
Very last period= 1:30+ I think it should be unrated becasue the influence is really big
In Div1 there was queue for around 25 minutes in the end (35 including the extended 10 minutes) , I think that's significant to not keep it rated.
Anyone solve C div2 using DP?
Is there any other way of solving it ?
add left and right in a heap and pop from them. the answer would be minimum when done for all elements. The added complexity of adding into a heap comes into picture with this but I think it should pass.
There are two ways: Brute Force + RMQ (DP) or DP (LIS variation).
Brute Force preprocess for each position i the minimum cost of any j > i such that ai < aj and fix i and j in a double for to get something like this:
DP uses a LIS variation such that
memo[i][k]has the value of the minimum cost of using a valid sequence of length k ending in the position i:Finally, get the minimum valid value from each memo[i][3].
Both complexities are O(n2).
Yes there is ! Fix j and then iterate over elements in interval 1-(j-1) and find the best of them(the c[i] minim that so v[i] < v[j] and i < j) and then the same with k(find c[k] minim that so v[k] > v[j]) and then update the global solution so you have a O(N^2) solution. Sorry for the bad english !
What the complexity of your code?
I think it is supposed to use DP.
My solution used an offline approach using segment tree with O(nlogn) complexity :) Don't know if it will be AC, but it passed pretest.
Mine is O(n^2) :) I think it will pass
It won't get TLE that we can be sure (y)
This was the easiest div2 CF round I have ever participated in.
The submission for questionB in div2 stuck in the queue for the last half an hour,
Why couldn't you fix it?
I was vey dissappointed. It still says the the code is in queue -_-
Worst div2A I have ever seen -_-
Very, very true ! The story just didn't have anything to do with the other problems ! I think the writers focused on the harder problems because they knew that an Div. 2 A or B can be made in under a minute, so they didn't pay attention to make it good
I think System testing will be over after 6 hours, any one thinks more??? let's see who can guess correctly :D
I'll bet for 3:15(UTC+8)
It's still in queue. Guess Codeforces servers are working perfectly fine :-p
35 minute queue..... Do you want anymore??
Please leave it rated, round was great!
This is what happens when you forget to thank MikeMirzayanov
yeah,it's seems that there are always some incidents occur when setters forget to do that.
Is the pretest always contain tests with maximum test data?
Usually
Yes or No, depends on the interest of writer.
For the last 15 minutes of the contest, I've waited for my verdict of D. But it's still in queue after half an hour of the contest. Even the hack page was not responding. And you're saying it's rated! Although, rating is not the purpose of the contest but making this contest rated is not fair.
I also did not see the results of my submission + hacks did not work.
Same here :(
Many of us agree, but there are too many comments of the same thing on this page ! Stop it ! There should be only one comment of this posted and the rest of us just upvote it ! Are you just farming upvotes or what ?
Real reason why round is rated:
So tourist can become number one again
yeah,that's a interesting take.
In div2E/div1B (I will be getting WA but still in queue) why is this wrong
Find min number of swaps required to sort the array. let it be x. then if 3*n — x is divisiblle by 2 then Petr else Um_nik.
I've done the same thing, but got Pretest Passed.
I checked on some sample with OO0OOO00O0OOO0O00OOO0OO code and it gave wrong for me
Maybe my implementation is wrong? I took the min swaps from geeks for geeks.
I've done simply that iterated over 1 to n and put the ith number on ith index.
Well also i guess for minimum swap u need to appy merge sort.
Can anyone explain Div2 D ...??
For each type of product, do a bfs and find minimum distance between any node with type i and each other node Knowing costs for all the types, you can just sort each of the n arrays and take the smallest k values
Try to find the minimum distance between every node i and a specific kind of good j,let's make it mind[i][j].all you need to do is run BFS for every j and sort mind[i] out. (maybe some stupid grammar mistakes,forgive me for that,please.)
Contest
statusqueue is stuck again.Too long queue to keep it rated. Everyone who submitted between 1:30-1:55 has a very big disadvantage because they have to check their solutions otherwise they can fail at PRETESTS AFTER THE CONTEST. Who didn't submit this time of the contest just gained 10 extra minutes to solve 1 more problem. This is unfair. Make the contest unrated.
Agree ! But there are too many comments of the same thing on this page ! Stop it ! There should be only one comment of this posted and the rest of us just upvote it ! Are you just farming upvotes or what ?
Can anyone give me hints or solution for Div2 D and E. The best I could think for Div 2D was brute and I'm clueless for Div2E
Still my submission is in the queue and they want the contest to be rated.
Mine too ! But there are too many comments of the same thing on this page ! Stop it ! There should be only one comment of this posted and the rest of us just upvote it ! Are you just farming upvotes or what ?
Same condition here .. 50 minutes still waiting for the submission to be evaluated
It's "after the world closed to the end" :v
emmm
ahh
It seems round was unfair to java users..
Did anyone else also find time-limit too strict for problem div2 D? got TLE with N*K*logK solution.
Er,I think the best solution is O( K*(N+M)+ N*(KlogK)(that is for sort) ) by using BFS.
yes, I also had done the same. I had used heap(priority_queue) instead of sorting.
But finally got accepted with (N+M)*K.
Yeah happened to me . I would like to know if this is a problem specific to Java. I didn't use
ArrayListfor adjacency list , maybePriorityQueuecaused the issue. I think using just arrays everywhere instead ofCollectionscould speed things up.It passed 1h after the contest,but my solution for Problem E(Submit at 123min after the contest starts) is still in queue...
Why does life have to suck so much? I got tle at problem E because of a stupid mistake i make,instead i have to wait till the end of the contest not know anything about my mistake. If the queue isn't retarded today i would have AC problem E. Thanks so much life.
And why is cf so laggy nowadays,after the contest i can't get into the website for 2 hours.Stupid.
Thanos's glove dissipated my rating.
i have no idea why my code was showing wrong answer on pretest 1 even when locally the answer was right
sorry my good sir,
i just wanted to point out that my C got MLE on test 1 that i couldn't fix because i got the verdict after the contest ended :) .
AND NOW I AM TRIGGERED :) .
const string top3[]={"tourist", "jqdai0815", "Radewoosh"};
good job Radewoosh
no chance to beat Gennady:/
I know your pain :/
I am trying to know your pain...
Div2E, is it enough to consider only num_components % 2? I submitted when the queue was too long, and can not see how result is.
in div2E\div1B why was it given that permutation was random, or that n>1e3? it confused me so much :D
So that you think twice before submitting. And It should look like it is div2E\div1B problem.
asymptotically my submission for problem Div2 D looks right can someone point out why I got TLE my submission
You did it in Java. There's your mistake. :^)
I had a Java solution with an O(K*(N+M)+N*(KlogK)) running time that TLE'd. I'm wondering what the running time of the expected solution was.
can you please tell why I am getting TLE my code complexity is O(k*(n+m))
One asymptotic issue I see is that you're sorting each city.cost, which bumps up the complexity from O(nk) to O(nk log k).
A linear-time selection algorithm like C++'s nth_element keeps the complexity at O(nk).
FML, seriously (ignore D, I'll be ranting about E)
Once I saw MLE I got rid of #define int long long and changed a few "int" to "LL" and submitted. After 15 minutes I saw that I got compilation error, facepalm (because I didn't have macro #define LL long long). I typed "make E" and saw that it doesn't compile locally, so I quickly added "#define int LL" instead of #define LL long long" and submitted once again, not compiling locally again and you can see the result. I learnt that I got second CE a few minutes ago. .#profitsoflongqueue #plsunrated
I'll just leave this here 38749776
Not related: You got the coolest template ever!
Yeah, I just got AC by resubmitting my code with correct macro xD. And this is going to be rated. Ridiculous.
Oh, and if there will be no bad things, round will be rated. I hope.well predicted Um_nik .After 105 minutes of the contest, I saw, I printed N — 1 integer, instead of N in Div2D.. Thank you CF.. :)
Because of long queue I couldn't correct my solution. It will affect our ratings.
Can anyone tell why this is giving mle? I guess maximum no of edges will 2^22*12 so shouldn't that be ok? http://codeforces.net/contest/986/submission/38747668
I hope the rounds must be unrated.
Have you thought of scc solution to the problem C? If yes, was dfs intended to fail due to the memory limit? If no, have you actually tried to come up with a solution which differs from yours? Why 2^22? Why not 2^20 and 2s?
This is not about the ratedness of this round, but this queue fuckup obviously shuffled the scoreboard, you can't deny it
Solutions with building graph explicitly were intented to get ML
Me and my friend didn't store edges of the graph and had linear memory usage, but got ml15 due to the recursion. Again, what is the point behind 2^22 and 4 seconds? Just for storing the whole graph to fail?
OK, I'm not in right mood to apologize for your mistakes. My solution uses ML/5 memory and TL/4 time. It is way better than standard rules about choosing TL and ML. 256 MB is just regular ML, so I didn't even think about setting some special ML because two my solutions (completely different) weren't even half close to 256 MB. On HSE Championship I saw that solutions that build graph explicitly get ML. I thought that it is OK. Your solution is just not good enough to get AC.
I have never asked you to apologize for anything. As I understand now, each time you see a question you don't want to deal with, you tend to avoid this by being rude.
Why do you think that 4 seconds are better than standard 2? Is there any reason why you chose to make n = 22 = 20 + 2? Was it lazyness to move your finger from
2to0?And just in case I want to let you know that you don't have to answer this question, I don't even consider apologizing from you for anything.
I guess that Um_nik chose 22 just because he is a big fan of Taylor Swift https://www.youtube.com/watch?v=AgFeZr5ptV8 That may also be connected to fact that he is currently 22 years old (at least computed by subtracting his birth year from 2018, if I'm not mistaken), so this is likely his favourite song currently, outlining his life goals etc.
How do I see your comments: I didn't solve a problem because my solution wasn't good enough for n = 22, but it would be good for n = 20. It's a small change and probably won't change the problem much. Now I will tell funny ridiculous things trying to force author to do something.
Nope. n was up to 22, it was in the statement. Let's say that I've chosen it to annoy you. That's not true but whatever. How does this change the fact that you didn't solve the problem which was given to you? And it's completely not my fault.
How I see your comments: "I'm going to act like that long queue didn't exist."
Yep, I was wrong not to consider it. But all comments of Golovanov399 barely mention queue and focus on ML and n = 22. So I answer to that.
Yeah, we may agree that Golovanov399's solution was not good enough for required constraints, but let's focus on a different issue.
Does setting n up to 22 makes problem more interesting? Is necessity of being conscientous about used memory equally valuable piece of that problem as coming up with any O(2n·nO(1)) solution? I think no and that's why I would lower constraints to make people life's easier. However I agree that setting it to 22 and failing some people that were less careful with memory is not some problemsetting crime, but failing because of such issues is always a bummer.
Dear sir,
Do you mind explaining your solution to me ? It looks quite different and I'd like to understand your logic. :)
How about the long queue, is that his mistake as well? This whole thing is only relevant in the context of "I didn't get feedback because I tried D before C", if the feedback works as normal, then even when not noticing the ML, it's a small change in code and one resubmission.
You know how it's done when memory matters? You set a tighter ML and maybe even put "note the tighter memory limit" in the statements. It's the same if you want to fail some barely too slow solutions (e.g. extra log in complexity or a constant factor), you set a tight TL and tell people to watch out for it. Then you don't have a lot of angry people who didn't notice until 2 hours after the contest.
Wut? Do you expect author to put statements like "Watch out for tight ML (only 256MB) which you may exceed if you store the indirect graph explicitly"? I also think that n<=22 was not a good idea, but this explanation is not convincing me at all.
No, I meant "watch out for tighter ML (only 128 MB)".
Why would I set lower ML?
Come on, your idea doesn't make sense. TL or ML is a bit too tight (but hard to notice) only if it's hard for organizers to distinguish some two solutions. Then the last thing they should do is decreasing TL or ML. We should always keep in mind that the invented solution might be too slow or too memory-consuming.
I passed pretests with SCC solution — Had ML 15 twice but it was because I had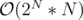 memory.
memory.
I submitted a dfs solution with O(mn) ML which should get an RE. However, the system tests are not strong enough. There is even no case like n = 22, m = 2n. Saved my rating thanks to this lol.
This should be unrated. It would be so annoying to lose rating because of the queue. I couldv'e corrected and resubmitted if i got the result during contest.
wow this sol could pass? 38747568....
Actually, there is a reason behind it. Less swaps means we have a bigger probability of a fixed point. I've written a similar solution which takes some random permutations of Petr and Alex for given N, counts expected value of fixed points and answers depending on "which was closer". I've tested it locally and passed without any problems.
WA10.
????
The numbers of swaps are large enough and close enough to each other that I imagine such probabilistic tricks won't work reliably. Sure, it can pass 49 tests out of 50, but so what if it fails just one?
lol I actually tried the same thing and WA10 too. But the submission above could easily WA in like N = 1000 data?
The N / 1000 will work fine for large enough N (as I tested, N ≥ 104 works pretty well).
However, the problem has constraint 103 ≤ N. I guess this small N ( = 103) is to fail these kinds of probabilistic attempts? If so, there should be more tests with N = 103.
From my experimentation, for cases with N = 103, comparing numbers of
a[i] == iandN / 1000should fail easily.Here shows approximated distribution of "the number of
a[i] == i" when N = 1000:So I guess there is a large overlapping interval and thus, sufficient number of N = 103 tests (like perhaps a few is sufficient?) should be able to fail these kinds of submission.
For
N = 1000000, this is fine, since the number of fixed points tends to be ~2500 for Petr and ~5 for Um_nik.Unfortunately, for
N = 1000, the number of fixed points is like ~3 for Petr and ~1 for Um_nik, with too much intersection probability to reliably pass even a couple of such tests.Here are the cycle lengths for 20 random tests with
N = 1000: first 10 for Petr and next 10 for Um_nik. Looking at #9 of the former and #1 of the latter, we can conclude that the cycle structure doesn't allow to separate them reliably.I used MLE (with assumption that p(i)=j are independent) in my solution and it works fine.
Nice, that's essentially the same as counting fixed points.
Looks like there are just tests 2-5 with N being 1000, 1001, 1002, 1003. In all other tests, N is at least 10000. I'd call that weak tests.
It seems that the author did not consider statistical approaches at all: otherwise, any of them has the least possible N as its worst case, and repeated worst case becomes essential. Alternatively, if the lower bound was at least 10000, counting the fixed points would work with high enough probability to pass hundreds of tests (no error on 1000 tests locally).
Well, that's true. My bad.
The point of the problem was to joke about such problems and I didn't expect someone to really use such solutions.
Well, the joke was certainly successful in my case :) .
I have first written a generator, and neglected the "swapping different elements" part. It's statistically insignificant, anyway, right?!
Later, when the idea of parity crossed my mind, I just checked it with my generator instead of giving it another second of thought. And guess what, it didn't show the right parities! because the answers mod 2 are statistically insignificant of course.
Haven't felt this stupid for a long time, the feeling is refreshing.
Nice joke and thx for strong tests for these solutions ;)
The idea for the joke is awesome, but when you're saying "let's do a problem that looks like being solvable with this method", you have to try to solve it yourself with "this method" :D
And btw. the joke worked on me too.
My solution was even weaker. I just count a[i]=i and if count>2 print Um_nik else Petr 38748615. and still it passed
Yes, but with reasonable coefficients, but anyway the mistake ~0.2 ((
CF uses windows system and i believe RAND_MAX is 2^15 — 1. It is possible it failed for some large value of N (10**6)
Duuuuuuuck. Thanks. I should have remembered about it.
For 15 minutes I wanted to distinguish 3n swaps from 7n swaps. I tried many heuristics like this one and none of them was even close to being precise enough for n = 1000.
A very cool problem btw.
According to formal logic, this statement is perfectly fine.
If there are no bad things, he hopes the round will be rated. That doesn't say anything about what happens if there are some bad things. (Then we hope the round will be unrated.)
I think Problem B has weak tests , i just realised after the contest that i'll get for sure a wrong answer caused by overflow , however i got accepted lol .
Too slow system testing :P
The round must be unrated.
You have extended the contest duration by 10 minutes. But still the submission which were in queue didn't get verdict. Many of these submission didn't even passed the pretests. If there were no queue at least in the extended time, all would get the verdict and get the chance to resubmit the code after correcting. Then you may make the round rated.
Instead of diminishing the unfairness to the coders whose solution were in queue, the extended time worked in the opposite way ! The coders who got verdict earlier or were not in queue, get extra time to solve more problems, when the coders with in queue were keeping the eye on the my submission page.
The coders with in queue issue lose time by keeping on eye on my submission page, though they didn't get verdict at last — losses time to solve other problems. Also, finally they saw that their solution didn't passed the pretests! But if they get that verdict during contest, they could correct and resubmit.
Thus it is totally unfair if the round is declared as rated. Please think and consider.
Can Someone help me why I'm getting WA in Div2 B
Solution 1
Solution 2
Both solution get WA on test case 3. ALthough many of users have done the same thing. Please help me....
Use "long double"
But many people used double and they got ac. Secondly isn't double is precise enough ?
I have seen even using float gives AC. Mine was also similar code but hacked successfully. I couldn't understand the reason.
you should use ,if(Math.abs(d1-d2)<1e-10)) instead of if(d1==d2),its generally unsafe to check equivalency between 2 double values.
Can you explain why so @jonsnow7
test case 2 4 should be ==. You probably get a tiny error in your computation for log (since precision is limited, there is not infinite accuracy in computers).
I noticed that case3 was a sample, so I accounted separately for x==y and got AC with doubles and std::log.
I've got the wrong in the same. Guess 6log6 and 6log6 are different :-p
Also on local machine test case 3 is showing =, which is perfectly find. But on CF, it shows > suddenly. What in the gods name is this ?
In past I've had UB show up on CF judge that did not show up locally. I have gotten used to subtle platform differences; I recommend you acquaint yourself as well. :)
What to change for that. pLease elaborate. How to remove platform differences. peach
I hacked this solution http://codeforces.net/contest/987/submission/38740925 why Ignored :( KAN
:( KAN
Can anyone tell me the reason for this ?
I had no problem with round being rated but now seeing this i do have, not fair :/
What is the point of N=1e5,K=100 in A? What is the point of N=22 in C? What is the point of some disgusting big integers in a trivial problem that ended up to be D (which conceptually is pathetic when compared to C)? Seems like the contest had several problems today (apart from the technical ones). I don't blame only the author. The coordinator should've made sure that shit like this doesn't happen...The contest also had some really nice tasks, but that's not enough to make up a decent contest
At least for C, I guess to make solutions with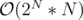 memory fail.
memory fail.
And my question is why would anybody want to do that? The beauty of the problem isn't related in any way to memory efficiency. Also from what I've read, there are also linear memory solutions that failed.
Well I also think that N=20 would have been better :D
I simply stated that this might be the case.
I wasn't arguing with you:)) I was as well stating that if this was the case then we should wonder again what's the point in trying to fail memory inefficient solutions
You shouldn't blame coordinator for any of these things. The only person responcible is me. Personally I think that you shouldn't blame anyone for these things because none of them are bad, but today you are 'the customer' and you are always right.
I feel his questions are valid and you should answer them.
I don't feel that way but OK.
@ What is the point of N=1e5,K=100 in A?
@ I don't understand this question. The point of constraints is to allow good solutions and to not allow bad.
@ What is the point of N=22 in C?
@ I don't understand this question. What is wrong with N = 22 in C?
@ What is the point of some disgusting big integers in a trivial problem that ended up to be D (which conceptually is pathetic when compared to C)?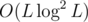 ? You didn't solve the problem.
? You didn't solve the problem.
@ In every problem there is thinking part and implementation part. Often they are not equal. C is more about thinking, D is more about implementing. But I don't think that D is absolute trivial in terms of thinking. If the problem were 'write FFT' you'll get AC, right? (If not — git gud) You are not complaining about some Data Structure problems — they are trivial in O(n2), but how to do it fast? In D you should do some easy things fast. Your solution is
About A, what are these bad solutions you didn't let pass in A?
I looked over Java submissions and in all of them people had to implement their adjacency lists using arrays, which is never necessary (in other problems).
OK, it may be real issue for Java users. My answer will be really bad: do not use Java.
I apologize for not setting proper constraints for Java solutions.
It's not only about Java. When you set a time limit, it should be not minimal TL that allows your solution to pass, but maximal reasonable TL that still doesn't allow wrong solutions to pass.
You could set TL = 5 sec and still no wrong solution would passed.
That's debatable.
My solution to D got time limit exceeded, but when I reupload it without any changes, it gets accepted. Can I somehow get my rating changed?
Would you want the same if your accepted solution got TL after resubmitting? If your score was increased now, in the future everybody would have to resubmit their TLE solutions after the contest and hope for an AC then. That would be stupid.
That being said, your TLE with 2s and then AC with 1762ms shouldn't happen. It's a big difference and perfectly the system shouldn't be affected this much by the overload/queue (because I guess that was the reason).
Thats what I want yo say, its not like 1.99 s, it is 1.762s. I think that the biggest test case was a pretest, because it was only test case 6 and I got AC during contest and tle only eppeared after the system testing
I think that's not debatable, but mainstream for problem authors atm. Usually there are 3 groups of solutions (those that should fit, those you do not care about (this one usually is empty), those that should not fit) and tl is set so that 3rd group solutions would not pass while 1st group solutions pass comfortably. Using only 1st group solutions for setting TL is so 200x
Now that's some serious argument — that you passed pretests with some margin and then got TLE on one of pretests. Still, it's a smaller deal than the big queue and half of participants not being able to see results of pretests at all.
What was intended to pass and not to pass in A and C?
I think it's bad if there exists a not-rare solution ("not-rare" meaning that many people will have it) that barely passes or might not pass (and it's hard to say). A perfect example is the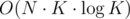 solution in the problem A, what seems to be a lot and might result in TL. I completely agree with "The point of constraints is to allow good solutions and to not allow bad." what means that constraints there should be stricter (if sorting isn't allowed) or should be looser. I'm saying that taking into account only the sorting solution, maybe there exist other solutions that forced the given constraints. If yes, why won't you describe that when people ask you about the problem?
solution in the problem A, what seems to be a lot and might result in TL. I completely agree with "The point of constraints is to allow good solutions and to not allow bad." what means that constraints there should be stricter (if sorting isn't allowed) or should be looser. I'm saying that taking into account only the sorting solution, maybe there exist other solutions that forced the given constraints. If yes, why won't you describe that when people ask you about the problem?
The thing about bignums in D boils down to: if we have a not-easy problem that requires some thinking/observation, should we try to keep it as simple/cute/short as possible, or should we add a reasonable implementation part? In fact, it's about how much we prefer each option.
In the particular case of the problem D, I think that without bignums it shouldn't be used at all, because many people know the main lemma/insight here and it's the main part of the problem. If not that, I would prefer a small N in this problem.
Also, when someone is saying "N=22 is stupid, why not 20?" even without a big explanation, why won't you answer the question?
About D: I completely agree with you. Also I thought that little idea of estimating logarithm in doubles is cute.
I don't answer because I don't have a real answer. I had two solutions, one with complexity O(2nn) and the other with complexity O(6n / 2). At first I thought that the first should be much faster for big n and compared them on n = 22. The difference wasn't big: about 1s for first one and about 2s for second. I thought that TL 4-5s would be OK and let it be.
It is kinda embarrassing to answer those questions from you. I really admire you as a problemsetter and it looks like I'm totally worthless at this kind of thing.
So currently in A the intended solutions work in ~0.5-1s, TL is 2s, the slower O(n2) solution likely works in tens of seconds. Lowering constrains to make it more of a geometric progression (say: 0.3, 2, 20) would much more fit the "allow good solutions and to not allow bad" statement in both its parts.
My solution to D is the opposite of cute. In particular, I needed to divide two bignums. I also tried Java to see if it can convert between bases fast enough :D
In this contest preparation, you haven't done a single thing that is stupid. A lot of that is either the preference or something that is easier to notice with big experience. For example, I was once told (by Zlobober I think) that in easy problems we should be generous with the TL/constraints ratio because of newbies and slow languages, even Python (and ofc. TL can't be huge in an easy problem because it would cause a big queue). No problem setter is expected to think about it themselves, while today it would be some reason to change constraints in div1-A.
Hit me up before your next round for testing, so I would complain about limits before the contest.
Out of curiousity, what is the solution with complexity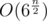 ?
?
Will it be OK if a just give a link to the code?
Go ahead. I'll try to understand the code.
38799853
O(NKlog K) solution passes sometimes and sometimes it is giving tle on test case 6. Now the problem is that for many of us it passed this case in pretests and it failed during systest. So it was a bit of luck whether your solution passes or not which you could have been avoided by increasing or decreasing the time limit i guess so that at least there was consistency in the verdict. Here is my solution which passed in pretests but failed in systests. http://codeforces.net/contest/986/submission/38730342
Regarding D, on first sight it may look like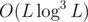 with bad constant solution (one log from FFT, one from binary exponentation, one from some binary searches of needed power or something similar), where L is length of n, but after some thinking we can reduce it to
with bad constant solution (one log from FFT, one from binary exponentation, one from some binary searches of needed power or something similar), where L is length of n, but after some thinking we can reduce it to 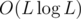 with pretty low constant factor. One log basically doesn't exist from the very beginning (one from binary exponentation) because numbers grow in length by two times in every step, so only last step matters, we can get rid of second log by estimating log based on length of number and significantly reduce constant factor by packing digits in blocks of e.g. 4.
with pretty low constant factor. One log basically doesn't exist from the very beginning (one from binary exponentation) because numbers grow in length by two times in every step, so only last step matters, we can get rid of second log by estimating log based on length of number and significantly reduce constant factor by packing digits in blocks of e.g. 4.
That part of transitioning from "this problem is obviously FFT exponentation, but these constraint are insanely large!" to "ah, so needed runtime is basically something like one FFT on polynomials of reasonable length (~2e5) which is definitely feasible" I consider kinda important and a bit interesting as well ("It's something"), without it problem would be pure trash in my opinion.
Python solutions are failing because there's not enough time to read input. If I set n as 10^1500000 in program it gives answer instantly. Did you intentionally make python solutions fail because we get bigint for free? Usually there is a multiplier to tl for slow languages.
I haven't solved D because I didn't have (still don't) any implementation of FFT that I was happy with (in that most of them seemed too slow for this). But assessing the logarithm or binary searching with powers of 2 after preprocessing 3^(2^k) was not really the main difficulty. And it's not about the hardness of the code. I'm really curious to see how many people actually got AC while coding the FFT from scratch. Probably nobody (or a very small percentage), because that it the kind of copy-paste algorithm. Also, you can never prove its error is not too much, and always count on the results you got in testing it. I think that in FFT problems, it's safe to consider them correct when you have an NTT solution that passes them as well (cause that one is easily proven correct and fast enough). Swistakk's argument that it's actually LlogL seems indeed much more powerful and may make a difference.
Also what I said was mostly asking questions (I'm glad you've answered), not just telling you how wrong you are. The limits were really tight, I see that you may have made that for a reason in C (I was asking why 22, when the standard N for N2^N si 20, and also because reading should've taken, in my view, a lot of time). In D, I wouldn't have had anything against N<=10^(10^5). I mean I would've just used a random FFT and hope it passes it. C didn't affect me at all (I simply wasn't able to come up with the idea). And in A, I was a bit afraid and maybe wasted 2-3 more minutes to think of how to speed it up but eventually concluded that there's no need for a speedup anyway. I was just raising the questions because they seemed atypical choices
Did I understand you correct? First you say that all of 'idea' parts were easy, then you say that you didn't understand that the solution is actually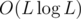 ?
?
About standard N for O(2NN). I don't really know but I think that N = 20 is standard for O(2NN2). For O(2NN) there even was N = 23 by Lewin in the last problem of Goodbye 2017. It was possible because of only O(2N) memory. And that was exactly the case in C.
L up to 105 would be a garbage problem (which is correctly pointed out by Swistakk) because the idea is not fresh and it would be just "use some bigints wow". With L up to 1.5·106 you should think how to do it really fast. Maybe it is not thinking you are doing mostly on contests, but it is part of the game.
You know that basically if I coded what I thought to be Llog^2, it would've turned out to be LlogL so only my analysis was wrong, but yes you got that right. I still think that raising a number to power fast doesn't bring anything fresh anyway. It's just using a well known algorithm, under a very optimized form to do a basic well studied operation. And as I said, I'd be happy to see a implementation of FFT that runs quickly enough for this problem whose precision errors could be proved not to influence the solution. Until then, I may as well assume all the solutions, including the official one are unproved, therefore wrong.
Also, not regarding the main comment, because it seems it's a bit too much hate (although it may be constructive), I want to say that I really liked all the problems but D.
All of them were interesting (well starting from B, it's pretty difficult to find an A that is really interesting cause it's supposed to be easy). I personally loved C and F (wish I read F during the contest=)) ) and really liked B (at the beginning I thought it's the we-don't-prove kind of problem where you need to guess stuff and it really turned out tricky, very well written the statement).
I, and I don't think I'm speaking only for myself, respect and appreciate your work, D was maybe debatable and some limits were too tight, but it's always place for better. Although I almost hated D, overall the contest had a clear positive impact (through the ideas and beauty of more or few of the tasks)
"Also, you can never prove its error is not too much, and always count on the results you got in testing it."
That's a bold thing to say. I've never tried to prove anything there but it doesn't look that complicated. The DFT uses addditions, subtractions and multiplications by values smaller than 1. The subtraction means that we can get huge relative errors in the process, but such a value only linearly affects the following values (we use it to add to or subtract from something), so the final absolute error is fine. It might be also useful that each value will be touched only times.
times.
The infamous FFT precision comes from two things: people try to multiply big (of order 109) numbers that result in answers not fitting in the used float type well, and people compute the first omega (root of 1) value and then multiply it linearly to get the remaining ones, what introduces a huge error. Write that part smarter and you will be fine.
A well written FFT works in practice as long as the resulting values are stored in the used float type with a good enough precision. In C++ it's usually more than 1014 for doubles and a bit less than 1018 for long doubles. You might check that by printing 'DBL_MANT_DIG' or 'LDBL_MANT_DIG', it's usually 53 and 64 respectively.
Yeah, I may have gone a bit too far but I've actually tried to look for a formal proof of the precision error correctness and could find only people complaining about it and others figuring out ways to overcome these errors practically.
Still, I'm not very convinced that the analysis of something like that is that easy, but I don't know anything about how to compute errors so I might be wrong (I do know a bit about how those values are supposed to be stored and it just seems insanely to me that you could have a decent error when doing about logN additions/multiplications per number). Completely unrelated, could you provide some good tutorials on how to assess precision?
Ohh also, how are we supposed to write that part smarter? Applying sin/cos function every time seems too slow, it may be useful to do some sort of raising to power (actually really raising to power), case in which instead of N multiplications you do logN multiplications and the complexity stays the same if you do that smartly, but I don't have any other idea.
There is the "numerical methods" subject in my university, maybe you will find some materials by searching that. Example things are: if you add two numbers with the same sign, the new absolute error is limited by the sum of initial errors, and the relative error is limited by the maximum of initial errors. The multiplication roughly adds relative errors. The most dangerous thing is subtraction, where the new relative error is unlimited. All of that can be proven with simple algebra, e.g. for mutiplication: (a·(1 + e1))·(b·(1 + e2)) = (ab)·(1 + e1 + e2 + e1e2) so the new relative error is e1 + e2 + e1e2. I can't find some materials about it quickly, but the example algorithm to analyze is https://en.wikipedia.org/wiki/Kahan_summation_algorithm.
The above assumes that the computer does computations as precise as possible, e.g. the result of 2.123·3.123 (assuming that these two values are stored precisely in the memory) will be 6.630129 changed only by the type error i.e. around 10 - 50 for doubles. I'm not sure about that for
sinfor example, but I always assumed so and it never hurt me.You can compute all 2k values of sin/cos once in an array and then use them. If you want to speed that up, compute only sin and use the fact that sin/cos is symmetric. It's good find some FFT problem, sort submissions by running time, in the top find something short and read it.
I you are crazy, use the small-giant step algorithm — compute every say 20-th omega value and use the linear multiplication by the primitive root of 1 to get the next 19 values. I once implemented this and it helps a little bit but it isn't worth it.
Thanks! I'll look up "numerical methods" related articles. Thanks for the short explanation (it really seems useful to know) and for the FFT-related answer. I think I got it.
Isn't it well known fact that you can multiply polynoms of length N with max value X via adequate implementation of FFT without fear of getting a precision error if value X2N fits into floating point type of your FFT?
Doesn't my solution have 1/2 chance to pass on each test, so approximately 0 chance to pass all test?
Here is the link for the solution.
It should also fail on any test whose answer is Um_nik and has N=1000:))But how did you compute the 1/2? I'm unable to assess a success probability for your solution
It is 1/2 for n=1000, but for bigger numbers the probability increases. If n is very big, and answer is petr, it will be correct probablly. If n is very big, and answer is um_nik, then it is a bit over 1/2 (because you use ==) So more like 3/4 But even with 3/4 it's .1% chance. I think you messed up the simulation somehow, why do you use n-l-1 instead of just n-1 again? Probably that helped But either way you got very lucky :P
It's terrible that a problem with possible randomized solutions has so few tests.
I agree, but there is a legitimate reason why this happened (in a meaning that it was not like that intentionally, but there is a fine excuse which is not that embarassing), which he explained here http://codeforces.net/blog/entry/59720?#comment-434312
This looks like sarcasm but I totally deserve it :)
Hm, it may looked like it, but actually it was not sarcasm. This problem definitely suggested some statistical approaches (which was fully intentional), but from a perspective of an author who is aware of simple parity trick such solutions may not cross his mind. Not approaching problem from this side is less embarassing than being aware of it and putting so weak tests with respect to it (but of course it is still not good).
The author put so few tests not to make the queue too large.
okay so if this round is going to be rated then there's no excuse to make any other round in the future unrated , I mean people who submitted 30 min before the end of the contest got stuck in the queue then got MLE and RTE on test 1 ( even worse : some of them got Compilation Error !!!) after the end of the contest , I mean if this contest will be rated then I don't see any reason which will make any future contest unrated , maybe even if we are obliged to write our solutions on paper and send them via post mail xD ...
Is F something like this
Let the prime factors of k from small to large (including their power too, but I have no idea how to call it) be x1, x2, ..., xm. We need to know if there is a sequence a1, a2, ..., am such that a1.x1 + a2.x2 + ... + am.xm = n.
Now if x1 > 1e5 then m <= 2. We can use Extend Euclid algorithm for this one.
Otherwise, x1 <= 1e5. Since a1 > 0 then we have the answer as a2.x2 + ... + am.xm = n (mod a1).
Dijkstra for the smallest number mod a1 = n mod a1. If it exists and it's smaller than n then the answer exists.
KAN Weird things happening 38741009
D is called Fair, but it's pretty unFair for Java
MikeMirzayanov http://codeforces.net/contest/987/submission/38741270
The verdict for my submission is "Judgement Failed". I have never seen this before. What does this mean ? Has my submission failed ?
I have a different solution for Div1B.
We can try to do the swaps locally with
n=1e4and then countcount(a[i] == i for i in range(n)) / n. Also we can do it many times and then take an average value.It's easy to see that if count of swaps was
3nthen the computed value will be aboutx=0.0025897and if count of swaps was7n+1then this value will be abouty=0.0000955.So how can it help us? If we know these two values, we can calculate the same
valuefor the given array and check which of computed values is closer, soif abs(value-x) < abs(value-y) then answer='Petr' else answer='Um_nik'.I won't try to prove this solution, but I solved some similar problems using the same idea. You can see the code here: 38739085.
at last testing finishes!
Aim for purple!:)
Can anyone explain me how the heck for input 2 and 4 on test 5 my algotithm gave "=" and for input 4 2 on test 19 the same algorithm gave > ???
38732327
It's the double precision. U need to check if abs(r1-r2) < 1e-6 if yes then "=" else check for greater and smaller.
I got the same problem in B. Then I get to know that actually doubles can't by compared directly because of precision.
http://codeforces.net/contest/987/submission/38751841
http://codeforces.net/contest/987/submission/38751577
Both soln are same. Then how come one is giving wrong answer and one is accepted???
Because in WA-solution you read float values.
Float keep just 6-7 significant digits. So 10^9 will transform to 1000000 * 10^3 +- smth.
I have seen a soln in which long long was taken in palace of float and rest were same and still it got accepted.
Because long long keeps 18 digits. And reading x = 109 will not transform it.
http://codeforces.net/contest/987/submission/38752648
Now see.
t1 and t2 are long long. So integet nums. But you shold compare real nums. So as t1 and t2 you should use at least double.
main() { ios_base::sync_with_stdio(0); cin.tie(0); ll x,y; cin >> x >> y; ll p1=y*log10(x); ll p2=x*log10(y); if(p1==p2) cout << "=" << endl; else if(p1<p2) cout << "<" << endl; else cout << ">" << endl;
See the reality this code has been accepted
This code at least must output '=' at all tests where x * log(y) < 1 and y * log(x) < 1 since p1 = p2 = 0.
Submission.
At other side, if you replace float by double at WA-solution and add checking x = y, you get AC.
Submission.
P.S. If thinking of difference between:
From AC solution and
From WA one should think that first code must give WA and second one must give AC because second code gives more accurate values (x y are long longs instead of long and x * log(y) returns double instead of conversion log(y) to float). This is because I personally don't love such tasks and always use double or long double instead of float.
For div2 B when i try this test case : 1000000000 1000000000 on my machine it outputs'=' which is correct but on codeforces judge it gives '<' .No idea why.Please help.my code
change double to long double. I think here the issue is , different precision of double on different machines.
It's not much about long double. It's the double precision. U need to check if abs(xly-ylx) < 1e-6 if yes then "=" else check for greater and smaller. I got the same problem in B. Then I get to know that actually doubles can't by compared directly because of precision. Instead they need to be compared like this for equality if( abs(a-b) < 1e-6 ) print("=")
But i did the same i think its because of long doible have a look at my code provided above when i changed it to long double it got ac.
See I've used the long double. Solution Link But still got WA. I guess it about elipson and precision in CF system architect in registers and storing of double.
Hey a little help required from someone belonging to the python community. In in problem E div 2/problem B div 1, initially I implemented the logic using recursion and as python has a by default fixed limit on recursion depth approx ~ 1500, I used the code at the bottom to increase the depth and and the stack size. But this gave me a runtime error. On platforms such as codechef and hackerearth I have used this technique in competition and it always works, but when I tried it on CF it didn't. I think it's not allowing me to import the resource library as the sys library is a very standard library. later I changed my code to an iterative one and it worked fine. but in problems where recursion can't be avoided and the depth goes as big as the array/input length, then what should I do. I know python Isn't an ideal language for competitve programming but still It would be great to have some help. Thanks.
I made this on Python2/3: http://codeforces.net/contest/1/submission/38757373.
resourceis available only on Unix systems (and similar, such as Linux). It can't work on Windows out-of-the-box.I'm not sure if Windows API allows to change the thread's stack size after it has been spawned. Therefore, I spawn a new worker thread with a larger stack size. (And somehow, Pypy doesn't try to increase the stack size for the worker).
Also, note that the Python stack frames are pretty large. You won't make your recursion stack a million layers deep with this stack size, and the current size already consumes huuuuuge amount of memory.
So you mean to say CF doesn't use a UNIX system to check our codes. By the code provided by you, will it be able to solve my problem . For eg, A DFS problem has a max recursion depth for some case is 10^5, so will this program run without any Errors. btw I tried implemented your method on my previous solution and now instead of RE its showing MLE. THanks mate.
What is the problem of test case 3 of A no problem, even I faced this problem at the contest time? This Is My Code!!
double A,B,C1,C2; cin>>A>>B; C1=B*log(A); C2=A*log(A); if(C1>C2) cout<<">"<<endl; else if(C1<C2) cout<<"<"<<endl; else cout<<"="<<endl;
It's the double precision. U need to check if abs(C1-C2) < 1e-6 if yes then "=" else check for greater and smaller. I got the same problem in B. Then I get to know that actually doubles can't by compared directly because of precision. → Reply
Failed D because I thought that when n = 1 the answer is 0. Found out that I got WA only an hour after the contest. I guess I'll just go and hang myself.
We should downvote this post for not making this round unrated. My solution of problem D was correct in my IDE, but got wrong answer on test case 1. Seriously disappointed.
We are here to learn.Don't get upset even if your rating gets decreased,rather boost up yourself and perform good in the next codeforces round...Good Luck!!
That sounds really pretentious considering it was CF infrastructure that messed up this round.
Its not what messed up. Its who takes the decision. How this can be a valid contest if there's a queue of 30+ minutes even after the end of contest. So, If again something messed up in future, why don't we just mail our solutions and after 2 hours get our verdict? There won't be any necessity of judge here then.
Что-то мнение сообщества не очень учитывается на этом сайте. Может быть, на русском все же объясните, почему так важно сделать раунд рейтинговым, расстроив 300+ человек, заминусовавших коммент? Просто никто же не обвиняет ни автора, ни cf staff ни в чем, все критикуют именно решение о рейтинговости раунда. Fun от задач и так получили (спасибо, Um_nik), но тестирующая система работала только 1.5 часа (я думал, только за 10 минут до планируемого конца начались проблемы, но в комментах ребята пишут, что за 40 минут посылали и не протестилось даже это), потом прислали клар, что очередь быстро зарезолвится (зачем так писать, если это совершенно не понятно?). Учитывая, что часть финансирования кф идет от сообщества, хотелось бы все же услышать ответы аргументированнее, чем Bad things happen. А то ощущение, как будто рейтинговый раунд это для галочки, типа если анрейт то провал какой-то, а так всё нормально.
It is my submission that passed the pretest before the system test. but, now I've got a time limit exceed for the same case.(pretest case 6) i don't know why my submission is time limit exceed.
it is same code but, one is AC and the other is TLE.
TLE : http://codeforces.net/contest/987/submission/38747543
AC : http://codeforces.net/contest/987/submission/38752740
Your crafting.oj.uz ratings are updated!
Can someone help me fix my TLE for Div. 2 F/Div. 1 C (AND graph)? I think my problem is, To find which ones are connected, I iterate over the submasks of the inverse, but I don't think I'm doing it efficiently enough. Could someone look at my code and help me out? Thanks
38753121
My very important opinion on problem D:
So you also cut off "good" fft from "bad" ones because yours is over-optimized, bravo!
We've already discussed that in private but since I'm unsuccessfully trying to defend my problems:
- This is just ridiculous
- tourist's fft is optimized, mine is not even the best I saw.
- Looks like there are less than 10 people familiar with fft on CF. That's embarrassing.
- Also you can't call a problem dumb and straightforward if didn't solve it.
Why, I believe I can.
Even if we drop the fact that we have kind of different point of view on what it is to solve the problem.
I'd rather say that you just set unnecessarily tight constraints to compensate dumbness of the problem by overloading it with shitty ad-hoc hacks.
Yeah, for me "solving a problem" includes at least "coming up with a solution with good complexity" which you certainly didn't do before I said you how to eliminate unnecessary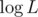 .
.
But even after that he had to squeeze it. I got OK now with O(nlogn) solution, but had to use base 104 (no chance to get OK with smaller base, and it's not obvious that with 104 there can be no precision issues: 105 already gives WA) and even with it the solution works more than a half of time limit. And remember that CF round is 2 hours only (even putting aside absence of testing). For me it's obvious that TL was too tight and didn't allow way more participants to get accepted. Hope you won't tell me that my fft is slow and that's my fault, because in our team we used it many times and it was OK.
But in this contest your fft is not good enough to get AC in this problem, this problem is special. It's your mistake that you had to squeeze it. I guess, you expect someone to apologize for your mistake? Because now you words sound like "the first version of my solution didn't get ac hence tl is not good enough"
Well, my solution uses base 103 (obviously 104 is not better because you are multiplying polynomials of the same size in the last step and only that last step matters), so the numbers are up to 5·1011 which is far from precision issues I suppose. And it works 0.7s. I think that your fft is better than mine just because I know that mine is not fast. For fast fft you can look at tourist solution which uses base 10 (!!!) and works 0.85s. It kinda defeats your point about "no chance to get OK with smaller base". So probably it is your solution itself (aside from fft) which is slow.
Why this happend with div 1 people? Complaining when you couldn't pass a problem due to the tight time limit. You couldn't pass it just because you was weak, so don't blame the other thing to hide your weakness.
At first I was like http://codeforces.net/blog/entry/59657?#comment-433657
But one contest later I went
Omg, do we really have to compare issue of ntt which works only for some special kinds of mods with issue of pretty huge difference in constants between different fft implementations?
As I said earlier, if one likes ntt that much, they can choose proper mods themself and use CRT.
Is cutting log3n from log2n lame? If so, should authors always allow any nlogO(1)n solutions?
Authors obviously can't allow any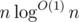 solution to pass. Cutting
solution to pass. Cutting 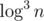 from
from 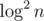 is not so lame because usually you don't need to do anything to cut it off, regular constraints like 2·105 probably would suffice.
is not so lame because usually you don't need to do anything to cut it off, regular constraints like 2·105 probably would suffice.
And cutting from
from  usually can't be done without having input of size like 106 and tight TL which, especially in case of FFT, always brings additional issues with constant factors of
usually can't be done without having input of size like 106 and tight TL which, especially in case of FFT, always brings additional issues with constant factors of  solution. For example, getting rid of just three additional checks in my solution which worked in O(n) speeded it up from ~1.7s to ~1.5s.
solution. For example, getting rid of just three additional checks in my solution which worked in O(n) speeded it up from ~1.7s to ~1.5s.
That is probably issue of using vectors and recursive fft which is strongly undesirable when dealing with arrays of length ~106, but I believe that contestants shouldn't think deeply about that stuff during short contests. They should concentrate on problem itself instead of writing very optimized code.
Recursive FFT, seriously? Do you use some advanced version which is slow not always?
You can see my version in submissions and check it out. When I tested it, it wasn't much slower than non-recursive fft from e-maxx (which is probably lame anyway, so I'm not sure if that is the point)
So far there was only one problem in which it was really an issue. And that's not this problem. Usually it doesn't fit in TL only when author of the problem being a moron and gives unusually large arrays in the input so slow non-recursive implementations would suck also.
The problem with your solution in fact is that you calculate too many powers. If you use binary exponentiation similar to used in this solution, I'm sure it'll be significantly faster.
Let's take your fastest submission (888 ms) and replace your FFT with recursive one. And we will get this with time 685ms.
Ok, it's not that recursive, just a little :) And it's using array, no memory copies, so no surprise it's a bit faster, but I don't consider it as "honest" recursive fft :)
I don't agree with any of your points.
Cutting log2 with FFT from log3 won't be easier than cutting log with FFT from log2.
log2 with 2·105 might be regular constraints but it's still often tight, not that different from 106 for log1.
The issue with distinguishing from
from  is that in the former the time of reading or some other linear parts might matter in the running time. It's the reason why it's bad (sometimes impossible) to distinguish O(n) from
is that in the former the time of reading or some other linear parts might matter in the running time. It's the reason why it's bad (sometimes impossible) to distinguish O(n) from  . But log vs. log2 can be done usually.
. But log vs. log2 can be done usually.
Unbelievable! Can anyone explain for me why this submission 38726384 is WA but this 38754807 is accepted?
Maybe the problem is related to the code using too much precision on doubles when storing them in registers?
https://stackoverflow.com/questions/7517588/different-floating-point-result-with-optimization-enabled-compiler-bug
I added the pragma (is this how pragmas are used? I'm not sure)
#pragma GCC optimize ("-ffloat-store")
and The code passed. Without it, it fails at the same test as you observed.
http://codeforces.net/contest/987/submission/38755343
http://codeforces.net/contest/987/submission/38755311
Locally both give the same answer.
The cout can maybe achieve something similar, by moving a double out of a register.
Thank for your explanation. I changed double to long double and the code is accepted. Maybe i should add pragma GCC optimize ("-ffloat-store") to my Code template from now on Or using long double instead of double to avoid the situation like that.
long double is also giving WA
this 38756347 is my AC submission with long double
You didn't actually directly comapred them.You used the eps, which will remove the undesirable accuracy.
But indeed that pragma thing is really cool. It actually restrict undesirable precision in double by restricting the storing of value into register.
Victim of long queue.
Bad queue is not your matter. Thanks to all you setters for good problems.
So... Can anyone tell me why this program doesn't work for 1000000000 1000000000 in B problem (div.2)?
It return '=' on my computer (g++ -std=c++17) but '>' on CF... (GUN C++17)
P.S. change eps to 1e-6 can solve the WA, but I wanna know why CF's return is different from my computer.
Oh, that's super unlucky :( You can see what's happening here: https://godbolt.org/g/Hb7ALW
When compiling for 32-bit architectures (you can simulate this with the -m32 argument if you have the required libraries), GCC does intermediate floating point calculations using FPU registers, which are 80-bit precision; it then truncates back to 64-bit precision when storing the value in the
avariable. However, since the FPU has enough registers, GCC decides to never storebin memory, so it stays in a 80-bit precision register. Therefore,beffectively got promoted to a long double whileais only a double.Since all x86-64 processors have some SSE support, GCC uses more efficient/modern instructions for floating-point multiplication. Those don't necessarily promote to 80-bit precision.
Thank you for answer my question!!! It's really helpful!!!
Can someone please explain, what is : EOF in the participant's output. I am getting the same answer as jury's answer but didn't passed the test cases.Your text to link here...
It means you do not have any output in this case.
And I try your code in the custom invocation, you have no output.... emmm....
Maybe that means you output nothing in that case...
I appreciate your in-depth answer but why does it gives the correct answer when we change EPS to 1e-6?
Thanks in advance.
Because converting from long double to double introduces some error. On my computer this error is of order 2e-8:
For some reason, some optimizations make this error a little larger (matching the 6e-7 error we see in Codeforces). I haven't checked the assembly code to understand why, but I'll post here if I look at this later.
Excuse me but do you mean in zhhhplus'code,the format of
ais double while the format ofbis long double?Many thanks!How to solve Div1 D? I got TLE using the O(|n| log^2|n|) method...
Now, I see E is quite obvious: work for each prime factor independently + HLD + BIT! O(N × 8 × log(N) + Q × 8 × log2(N)) passed easily!
I have not used absolutely any data structure except LCA. Just do it off-line. And I agree that it is easy.
Honestly, I didn't know to update a vertex and query sum of a path in O(logN) :). I feel so noob @!
I am not sure whether you realized it or not, but it is possible to query sum of path as difference of prefix sums. There is log factor that originates from logarithmic number of prime factors, but taking into account every factor separately takes O(1) per each of them.
Can anyone suggest , what exactly to use in div2 D?
Why were hacks not allowed from problem Div 2 — D ? Surely the randomness is just a false start and what really matters is the parity of the permutation !
You can't just ignore guarantees about data generation. There were some statistical approaches that required these randomness assumption, but that just strengthens this point, first sentence of this response is sufficient explanation.
I don't get it ... Isn't a permutation of the first n integers enough ? Either it will require an even number of swaps to get back the identity permutation, or an odd number. Kindly elaborate your point.
For model solution it doesn't matter. But you can't simply say that something is random in statement and then generate test data not obeying this rule. There can possibly be some people that will try to use that randomness of data in their solution (and it turned out pretty many people tried using that)
Were there any AC solutions that used the randomness ?
How does it matter?
Yes, there were.
How to do Div2b. I saw a couple of submissioms and I am particularly interested in log method. Why does thst work and is there some article from which i can study that. I am feeling dumb even writing it. ;(
If you want to compare xy and yx, take log on both sides. This reduces the problem to comparing y * log(x) and x * log(y) This reduces the problem to a form which you can compute and compare.
Or use log base x to reduce two numbers into y and x*log_x(y), which avoids floating point number comparision(which is annoying)
(Ofc you have to watch out for x = 1)
Why bothering with exponential and logarithms at all? Besides a handful of cases, that you can check explicitly, the one with the greatest exponent is greater! http://codeforces.net/contest/987/submission/38732468
It's not bothering. It's being smart. Writing the log solution will consume less tym in writing of code, thus giving you more points in the same solution.
Also in handful of cases, if by mistake you forgot to include one case, damn you got WA. It's always better to proceed generally then specifically.
?detaR tI sI
Уже n раз вы делали анрейт. В чем глобальная проблема сделать n+1, типа Данилюк обидится?
Can someone explain this solution of E, please? code
He uses a statement
if n/500 <= cnt then Petr else Um_nik.We can change this predicate a little:
n/500 <= cnt=>1/500 <= cnt/n=>0.002 <= cnt/n.And the reason why this predicate works you can see here.
Sorry, But I'm not able to understand the logic. Can you please elaborate why this worked and how it worked. jvmusin
Okay, I'll try to explain the logic.
In problem statement we can see that the elements of an array are randomly shuffled and n is large enough to use statistics (
1e3 <= n <= 1e6).It's a very rare situation that all elements in array have been swapped, so let's simulate this process locally on array [1,2,...,n].
We will do
3nswaps and then count elements that didn't change it's start position. Then we havecountof such elements. We can divide in bynand get rate of count of items that was not swapped.So after doing this operation
ktimes (I did it 100 times) we can take an average value of our simulations.Now we have some ratio, my computed value was
x=0.0025897. Now do the same operations, but with count of swaps7n+1. We will have a ratio abouty=0.0000955.Now we can solve the initial problem. Read size
n, read arraya, then compute ratio of unchanged indexesvalue = count(a[i] == i for i in 1..n) / n. So now you have to compare your ratio to previously computed valuesxandyand decide which one is closer to yours.In other words,
if abs(value-x) < abs(value-y) then answer='Petr' else answer='Um_nik'.Hope it helps.
Yeah Got It. Thanks jvmusin A really cool approach. And using that probablistic thing was really Cool.
OTL I just solve the problem D, but server was down and I couldn't submit the code! wowowowowow
The most stupid thing I did in this contest. It actually sounds as if I did not solve div 2 D on purpose.
When I read the task, the first thing which came to my mind is to run bfs-es separately for each color. However I wanted to calculate all the values for all vertices with given color and I found it very hard or impossible — when I reach the vertex which was already visited, I should somehow propagate missing values and that was very hard.
I did not notice that instead of calculating distances from given vertices to the rest, we can calculate distances from the rest, to given vertices and this way, we will get all the values for every color. Did anybody else stumble upon this issue or once you got 100 bfs-es idea, the rest was automatic?
Thanks
I've a question instead of i,j,k in Div2C if we had to pick 4 displays (say i,j,k,l) then how would we go about solving the problem?
You can use a simple DP approach with a complexity of N^2*M. Let's call dp[i][j] the minimum cost to pick j displays and the last display index is i. To get the answer, you just have to iterate through all possible k that k<i and s[k]<s[i], and update the minimum answer. This solution can be further optimized by using an IT to get the minimum value and update while we are traveling from left to right. The complexity will be reduced to N*log(N)*M. Here is my code for that DP.38760990
Thank You I've understood. Its such an elegant solution of yours which can be extended.
What I had thought of during the contest was for each j find the i(<j) and k(>j) with the conditions given in the question. Which was a proper O(n^2) solution. I never thought of a DP. (I never think of a DP :(.
Thanks again!
Доброго времени суток! Я делаю задания в Студии Майкросфота и затем загружаю в ответ. При этом часто происходит, что компиляция останавливается из-за строчки
include "stdafx.h"
Ничего страшного, я убираю строчку и подаю решение снова. Однако, вчера во время конкурса много решений оказалось в очереди, и система не показала, что компиляция не проходит вплоть до окончания времени. А решение было правильное, и жалко терять баллы. Нельзя ли посмотреть в http://codeforces.net/problemset/problem/987/C http://codeforces.net/contest/987/submission/38748349 — лишняя строчка http://codeforces.net/contest/987/submission/38760294 — правильно и добавить мне балл? Спасибо, Леви
При создании проекта в студии можно нажать галочку Empty project, и не будет никаких stdafx-ов.
Can somebody help me to understand what's going on? Yesterday in div2.B I wrote r = x * log(y) and t = y * log(x). And than I got WA31, where x = y = 1000000000, because r - t was 6.87... Whow?
http://codeforces.net/blog/entry/59720?#comment-434361
Oh, nice!!! Now to solve the problem you must solve the problem and don't forget to think about architectures of CF test system. REALY???
How to solve Div.2 F ?
Can anyone explain me how is this even possible?
You compare doubles without epsilon.
I think this soltuion will still get WA on large tests because of lack of accuracy.
Whar is epsilon ? Please can you elaborate on this thing. I get the same problem with "=" and "<" and doubles. dalex
Due to floating point error, testing for equality of doubles may not work all the time. It may be off by a very small margin so they will not be counted as equivalent. Rather than testing if a==b, you should say abs(a-b)<epsilon and that should work. 1e-9 should be ok for epsilon.
I used epsilon, but also get WA31 where x = y = 109: 38736740 What do you think about that, dalex?
Did you read my message?
Could someone point out the complexity of my solution of Div2D (38748801)? I believe it's supposed to be a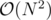 , but it got accepted.
, but it got accepted.
It's N^2. But it works fast because the author didn't make the obvious max test (graph is a line, and the only city with some label is its leaf). In such test you will have to visit ALL vertices to make target == 0.
This is ironic.
Can someone please help me debug the code for DIV2 problem C. I am failing at the sample test 1 itself. 5 2 4 5 4 10 40 30 20 10 40
I am using recursive top-down 2D DP. My code gives 70 as the answer.
Link to my code
Did you make sure 3 displays you chose has satisfied indexes?
Your states are wrong .You are not meimoizing"num " . Your DP state should be DP[ind][x][num] for your solution to work but I don't think it will pass memory constraints . Check my approach http://codeforces.net/contest/987/submission/38744307
It is O(n^2) both in memory and time complexity
Thanks! Jynx that was helpful :)
Jynx You actually saved me. Thanks a ton! So much love to you :D
tourist strikes back
I think it is better to be unrated,I got memory limit exceeded for one which I submitted before 20 mins of end, where I could have easily changed if I known before end, I feel there are lot many cases like this.!!
Did anyone manage to get AC in Div2D/Div1A in Java? If so, could you comment a link to your solution?
Don't use collections and objects, rewrite everything with arrays only.
I didn't use any collection, only custom written vector with arrays and it still failed in the contest-38748879 and gives AC in gym with time-2495ms :( Any other more efficient way to do everything with arrays?
Try to use normal queue on array with head/tail pointers.
Yes I did heres the link to my solution Problem D Div2
Where is the link of editorials ???
Hi! In DIV2 problem B my code is giving correct answer on my local machine but fails for case 1000000000 1000000000. Can someone help me in understanding the reason behind this?
Link to my code
Thanks in advance.
I believe epsilon is too small for log(). EPS 0.000001 must be enough.
Thanks for your quick reply, I changed the code and it passed as well. But I didn't quite understand why it solved the problem? I mean, Isn't a smaller EPS will ensure that the numbers are closer hence there is a far better chance of them being equal. Can you please clarify this as well? Thanks in advance :D
Now I'm confused. Your solution 38766944 gives wrong answer ">" on test 1000000000 1000000000. I was sure the problem is in function log(), because it hasn't so much accuracy...But...
But when I just add
cout << setprecision(40) << A << " " << B << "\n";to see for sure A and B the answer changed to "=". (And A and B are exactly the same — all the digits!). Funny.P.S. Even more — this makes answer to disappear, and abs(A-B) is big enough:
But THIS gives right answer and abs(A-B) is 0:
You need a specialist in data types, not me.
Sorry, I should learn to read comments more carefully: http://codeforces.net/blog/entry/59720?#comment-434361
(But I still [for two years] can't understand why outputting can affect the result).
Printing the variable blocks a compiler optimization (storing values in registers instead of in memory).
Outputting requires a function call. Since the called function can freely use most registers, the compiler is forced to save the contents of some registers into memory before calling the function. If the register is 80-bit precision and the corresponding variable is 64-bit precision, it will truncate the
long doubleinternal register to adoublevariable.Thank you VERY MUCH!!!
Is there a trivial solution for Div2F?
В будущем стоит в таких случаях писать за 5 минут до конца, что очередь не рассосется, контест не будет продлен и скорее всего будет рейтинговым. В этом случае участники внимательнее отнесутся к уже посланным, но не протестированным задачам. Меня это не поаффектило, потому что мой сабмит зашел, но за 5 минут до конца я был уверен, что либо контест продлят, либо он будет анрейтед, потому что предыдущее сообщение было о продлении контеста в связи с очередью, которая за 10 минут не уменьшилась.
P.S. Имхо раунд надо было делать анрейтед, но видимо по какой-то неизвестной причине администрация не любит это делать, давайте тогда больше информации в конце контеста.
Can someone please explain what is: unexpected EOF in participant's output. My answer is same as the jury's answer but it didn't pass the pretest.38742652
The problem is in in two last "else if" statements:
else if(x>2 && y>x) cout<<">"<<endl;else if(y>2 && x>y) cout<<"<"<<endl;What if x>2 and y < x? or y > 2 and y > x? These are valid cases (for example 5 2), but your code doesn't print anything because none of your if statements is evaluated as true. Added two more if and got AC:
x>2 && y < x, andy>2 && y > xYou can check my sumbission if you want! :)
For Div. 2 D, I wrote a multi-source Dijkstra solution using a priority queue first and it got TLE on test case 6, while the same solution with a queue passes. Why?
Because second one is not Dijkstra, it's bfs.
Someone help me how to do 987C-DIV2 problem with segment trees. I used the dp to do it.
Link to a comment.
Congratulations @Fortza_Gabi_Tulba!!
TIL Div2D can't be done (or i couldn't manage to do it) using list instead of vector and queue. Wasn't aware it was that much slower. Got TLE on test 6 with a O((n+m)*k) solution. No wonder none of my 12 submissions during the contest got AC. Changed it to vector and queue and got AC
I also got tle in system test 6 because of list, although it pass pretest after waiting for the long queue. The tle one However it can really be faster, as I tried later. The modified one
I can't believe 987E - Petr and Permutations had so less submissions, and people used BIT/Segment Tree to solve it. I solved it simply by switching every element back to its actual place and maintaining count, and then increment count by 2 until it equals 3*n or 7*n+1, because once all elements are in their right place, you choose two elements and swap them back and forth. This works because for any particular n,the values 3*n and 7*n+1 will have different odd-even parity.
My solution: 38768320
I just submitted the very same solution I submitted during the contest (which passed pretests, but then tled on one of pretests during finals testing, namely pretest 6) and it passed (within about 7/8 of TL)
Please, use long double instead of double. I changed that and got AC. You can check it here :)
Using log2() instead of log() in 2B with eps1e-6 you will get WA log2 log Can someone explain this?Thanks!
Btw,it's really discourage to set problem like 2B, I don't think it's fair to give penalty to those who use base2 other than baseE during contest and eps1e-10 and so on. It's an easy problem but more like testing you luck.
Don't complain about precision If you're not using long double.
Changing the doubles to long doubles makes the log2() solution pass: http://codeforces.net/contest/987/submission/38808634
Additionally, just by adding
#pragma GCC optimize ("-ffloat-store")
the base-2 code gets AC: http://codeforces.net/contest/987/submission/38808774
collares has a good comment in this thread about this precision issue: http://codeforces.net/blog/entry/59720?#comment-434365
Many thanks!
Please, agree that it is very difficult to write problems so that 7039 people like them. As for me, the problems were interesting and many people will agree with me.
Is Um_nik to blame for the long queue? Perhaps you will blame the coordinators? But what could they do?
Please don't forget about how much work did the organizers do to prepare the contest. They worked much more than 2 hours which we spent at the contest. And they are not less upset then we. And making the contest unrated would mean to throw away their work.
I don't say that everything is good and it should be this way. I say we should consider two sides of the coin.
So, MikeMirzayanov, please discuss and come up with rules about being rated/unrated of the contests to avoid this kind of situations.
Why do you downvote my comment???