


Hi, Codeforces! I'm glad to invite everybody to the #489 Codeforces Round, which will be held as soon as tomorrow, on Monday, June 18, 2018 at 19:35. The round will be rated for all participants from the second division (with rating below than 2100). As usually, we will be glad to see participants from the first division out of competition!
Problems for the round have been invented and prepared by us, pupils of Moscow school №2007, Dmitry DmitryGrigorev Grigorev and Fedor ---------- Ushakov. We want to give thanks to Andrew GreenGrape Raiskiy for his aid in preparing and testing of the problems, to Ildar 300iq Gainullin and to AmirReza Arpa PoorAkhavan who have tested our problems too and to the coordinator Nikolay KAN Kalinin, since our sometimes strange and undeveloped ideas have become eventually the Codeforces round. Also, we say thank you to Mike MikeMirzayanov Mirzayanov for his unbelievable Codeforces and Polygon platforms.
You will receive 5 problems and 2 hours for solving it. During the round you will be helping for an extraordinary girl Nastya, who has been living in Byteland and sometimes receives very strange gifts for her birthday :).
Score distribution will be announced, traditionally, closer to the start of the contest.
We're holding our the first and, I hope, not the last round in Codeforces, so I hope a lot you will like our problems. Please, read all the problems. Anyway, I wish luck and high rating for all the participants!
I'm looking forward your participation.
UPD Score distribution is standart — 500-1000-1500-2000-2500
UPD2 Thank you for your participation in the contest! It's very-very pleasant for me if you like the problems, and I'm sorry if you don't :) I hope the next my contest will be even better, than this. Thank you for all!
List of the winners of the contest:
Div.2
Div.1 + Div.2
My frank congratulations for all the winners!
UPD3







Is it rated? don't downvote plz, tomorrow is my birthday
Happy Birthday rotavirus in advance.
Not rated for division 1.
Finally someone remembered to thank both KAN and MikeMirzayanov.Hoping it would be a good round after the last one.Good Luck everyone.
is that true ??
any one mention KAN and MikeMirzayanov will have upVotes ?
KAN & MikeMirzayanov
You got it wrong it's not the name but the thanks part for the work they do for us in preparing contests and updating codeforces on a regular basis.
score distribution ?
It will probably be announced before the contest
just saw your graph! You have my respect, mate!
we are gladiators ( like viking , icleland football team + mexicans )
well said!
Of course, it will be announced before the contest. I'm sorry, I forgot to write it in the English announcement.
Usually strange gifts will transferred to someone else later. I predict that we will become this "someone else". However, in addition, Nastya will tell us what to do with our gift.
Nastya forces us to do strange things. Do not be like Nastya.
UnUsual Usual contest time !
Do you ever get upvotes ? xD
I was hoping to see one thematic contest of the world cup
creates confusion for non followers and boring too
hoping to see more of mathematics ,all time favorite GreenGrape
Your wish came true :)
true...:D
Getting 502 Gateway error, hope that will be fine at contest time :)
Expecting a good contest....
Score distribution?
Updated. Check now.
Yeah, got it. Thanks
Too keked
In the problem C : Also, you should find the answer modulo 10^9+7 Can someone explain what this means,please?
You should ask questions on "problems" page. There you can get answer momentarily.
If the answer is A, you should print the remainder of division of A on 109 + 7.
Understood,thank you!
Hi, in problem C im having WA on test number 2. However on my computer (with the same code) it gives the correct answer. Can someone check this out please?EDIT:It was my bad, sorry.
Wtf, math contest.
:D :D
It's not funny
Mathforces Round #489 (Div. 2)
What is unexpected verdict when trying to hack problem C?
Drunken and sleepy ㅜ_ㅜ
Oh those wardrobes
How to solve div-2 B?
There are two numbers. Obviously, since gcd is x, therefore common factor is x. so now both have factor x. So first number is in form a*x and second is in b*x and gcd(a, b) must be equal to 1. Since both number can't have other than x. Now GCD* LCM = first_number * second number. So x*y = (x*a) * (b*x) So y/x = a*b so we need to find all pairs (a, b) where gcd(a, b) ==1 && min(a*x, b*x)>=l && max(a*x, b*x)<=r and damn this count is the answer. There is just one catch, that y must be divisible by x. Otherwise the answer will be 0.
I kind of used the same logic, if possible can you please tell why is this solution failing. http://codeforces.net/contest/992/submission/39386988
Same as I mentioned the catch. When y is not divisible by x. Let's take test case 1 100 3 10 The answer should be 0. But it is giving 2 as output.
Thanks go it , i assumed lcm to be divisble by x, which was a stupidity.
in form a*x and second is in b*ywont be second number also in form
b*xYeah typo error Lemme edit it.
Second is b*x. Right? Not b*y.
Yes it was a typo error. Edited !
How to solve Div 2 B ?
If y is not divisible by x, answer is 0. Otherwise, all pair (a, b) that satisfy the condition can be represented by (x * a', x * b'). Let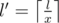 ,
, 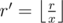 ,
, 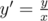 . Now the problem is counting number of pair (a', b') in range [l', r'] such that GCD(a', b') = 1 and LCM(a', b') = y'.
. Now the problem is counting number of pair (a', b') in range [l', r'] such that GCD(a', b') = 1 and LCM(a', b') = y'.
This can be done by iterate over all divisor d of y' and check if pair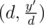 satisfy all the condition above.
satisfy all the condition above.
My implementation
I think its can be done just by iterate over all divisor d of y
its can be done in
O(d^2)where d is number of divisor of y...you can check that here: 39390416 ,unfortunately i don't got that along the contest :(
There are two numbers. Obviously, since gcd is x, therefore common factor is x. so now both have factor x. So first number is in form a*x and second is in b*y and gcd(a, b) must be equal to 1. Since both number can't have other than x. Now GCD* LCM = first_number * second number. So x*y = (x*a) * (b*x) So y/x = a*b so we need to find all pairs (a, b) where gcd(a, b) ==1 && min(a*x, b*x)>=l && max(a*x, b*x)<=r and damn this count is the answer. There is just one catch, that y must be divisible by x. Otherwise the answer will be 0.
why min(a*x, b*x) >= l and not a*x >= l && b*x >= l ??
You have to check both a*x>=l && a*x<=r && b*x<=r && b*x>=l. I done it in two statements min(a*x, b*x) >=l Since if minimum is greater than l, then the number which is greater than or equal to other number will always be greater than l. Same goes for max(a*x, b*x)<=r Since max of both number is less than r So the other number (which is less then the first one) will always be less than r. You can always check all four statements if you like. a*x>=l && a*x<=r && b*x<=r && b*x>=l.
Yeah. Sorry that was a stupid question! By the way, can you explain the case for 0. why would it be 0?
First of all question was not stupid. It was cool. Your solution got a problem. I, myself got 2 WA on this one. Secondly as i told you two numbers are in form a*x, and b*x Now lcm * gcd = product of number (for 2 numbers) so y*x= a*x * b*x so y=a*b*x so y must be divisible by x. if not divisible you can never find any a, b irrespective of l and r. So the count is 0 in such case.
Got it Bro, Thanks :) That's what is missing in my solution, The TC 5.
thats exactly wha i did and i get wa on test 9..... https://pastebin.com/bCfGhsx6
You can refer to my solution 39374707
I'm not able to compile yours on JAVA compiler. Just check on test case 1 1000 3 100 The answer must be 0. I think you didn't check if y is divisible by x or not If not divisible then the answer is always 0.
Simple Explanation is as follows:
LCM(a, b) = a * b / GCD(a,b) ....... eq(1)
and if g = GCD(a, b) you can write a = p * g ; b = q * g such that p & q are coprime i.e. GCD(p, q) = 1
So above equation 1 can be rewritten as
LCM(a, b) = ((p * g)*(q * g))/g
LCM(a, b) = p * q * g ; where g is gcd(a,b)
So now problem became: for given integers y and r , count number of unordered pair (p,q) such that y = p * q * r and p & q are coprime i.e gcd(p, q) = 1.
That you can do in O(sqrt(N))
Ref Solution
How to solve D?
I thought of Divide & Conquer based solution but couldn't merge efficiently.
If somebody solved like this, then please help how!
Notice that the product will get big really fast. So for each starting index you can just iterate over the end index until the product gets too big (e.g. > 2·1018). This will have runtime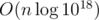 .
.
The only problem with this approach is that this doesn't hold if there are a lot of 1s in it. But you can modify the approach from above so that you jump over the 1s, and check in O(1) if there is a solution (there can be only one) with the 1s that you jumped over..
Really nice and simple. Thank you!
Couldn't code it in the time I had, but my idea was something like this:
I stored the sum upto n numbers in an array, and the value of k for the first n numbers taken consecutively in another array k[n]. Now, for every element for which k[i]>=k(required), just check if there are consecutive numbers up back till the last element with this property.
I've compressed segments, that contains only "1". Then you can just bruteforce all segments ([0; 0], [0; 1], ... [0; n-1], [1; 1], [1; 2], ...), refreshing p and s for O(1) and breaking when p>z, where z=(2*10^5)*(10^8)*(10^5).
It's working for O(n*log(z)), but you must handle overwflows carefuly.
my incorrect (WA on pretest 7) solution for B — Nastya Studies Informatics is to find all factors of y, then generate all pair, if the pair satisfy gcd(first, second) == x && lcm(first, second) == y then increment result
what is wrong with the solution?
You should check the case 1 1 1 1
It cost me 3 WAs as well :(
Edit: Answer for this case is 1 BTW, it gave me 2 due to an error in my code only for this specific case.
my code output for case 1 1 1 1 is 1
what it should be?
Oh wait... have you checked both numbers in each pair >=l and <=r as well?
You wrote in the program:
If a and b are too big, it can be overflow (109·109 = 1018 > maximum value of int).
For example:
test case:
1000000000 1000000000 1000000000 1000000000correct answer:
1your output:
0oh thanks! got accepted on practice submit because of that
that was some noob mistake :( i should check any overflow case later
Pro tip: write
#define int long longat the beginning of every solution and usesigned main().What's the difference between
int main()andsigned main()?I think that if you do the define the compiler will think you wrote long long main and it would say that it's an error, but if you write signed main() it would be alright
Exact.
worst contest with no creativity
Was E square root decomposition?
I tried a sqrt approach, it was TLE 13. I was using unordered_maps, so I tried to implement hashes, but didn't finished in time. I think there is a log solution
It's too slow solution, the same our solution worked >10 sec
Usually if you think it is solvable with sqrt-decomposition, dump the idea and look for a better solution. In most the cases you would be right.
Of course, No :)
Idea is simple, there are not many positions that greater than sum of previous.
can you explain more ?
It likes fibonacci sequence, there are little terms ≤ 109. So what you need to do is just pick the maximum until it less than or equals 0.
The way I thought about the problem was to always start searching at the first index i = 0, and if that index wasn't the shaman-king then go to the smallest index j such that j > i and aj ≥ sum(A[: i + 1]). Continue doing this until there is no such index j. All of this can be done quickly using segment trees. Worst case aj should double in size (not Fibonacci) for each iteration, and all of the segment tree operations will run in time so my solution should run in
time so my solution should run in 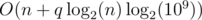 . 39387502.
. 39387502.
chemthan Could you please explain this in brief?
Assuming i1 < i2 < ... < ik are all positions d such that ad > a1 + a2 + ... + ad - 1. Then obviously aic ≥ ai1 + ai2 + ... + aic - 1 + 1. We have: ai1 ≥ 0, ai2 ≥ 1, ai3 ≥ 2, ai4 ≥ 4, .... Because ai ≤ 109 so the number of terms k is not big.
Then let fd = ad - ad - 1 - ad - 2... - a1, using a segment tree to get all d s.t. fd ≥ 0. The number of d s.t. fd > 0 is less than log2(109) so each query we get out at most that number until fd ≤ 0.
Hey My square root decomposition solution 39389380 passed after contest. (missed submitting during contest by 1 minute). Have a look.
Super tight time limit :D
I regret wasting time on D now :(
PS: Found mistake . It doesnt work, Sorry
It was very nice contest:::::: thanks
pretest #12 of C? any hints please verdict- WA
Edit this is the code please tell me whats wrong-http://p.ip.fi/_4l8
Update- I got it thanks for looking over my code everyone. In python n//2 and int(n/2) are not the same it looks like.
take modulus of x by 1e9+7 after scanning input.
Overflow most probably.
Overflow in Python?
Max range of integer in python is around 10^(7000).
Huh?
Maybe your program prints negative number?
Modulus gives a positive number in python as far as I know.
Got it. Hmm, everything seems OK.
if x==0 or x%1000000007==0:This is wrong. Only
if x==0is required.Yes you are right. But I removed that and still WA.
when will the rating changes happen ? (sorry for bad english)
There is a chrome extension called CF-Predictor
i know about it , and i have it ,but that does not mean all of my problems(a,b) will be accepted.
I don't like math problems.
I read only A, B and C, but looked more a math contest than a programming contest to me! Thanks to the author, anyways.
Programming contest are half logics and half maths.
Managed to solve A,B,C. How to solve D?
I think the main idea is that the maximum possible product is TOTALSUM*k, so there can be at most log_2(TOTALSUM*k) elements larger than 1 in a valid array.
Hence we can bruteforce over all possible (i,j) where i is the position of the first element larger than 1 in the array and j is the last position.
Once you have that you just need to look at how many extra ones you can add to the left of i and to the right of j.
I did this but I made a mistake I guess.
What was Test case 4 for C?
k = 0, I think.
i guess its y := 0
ans should be (x<<1)%M
Likely your program didn't pass that test case due to overflow. (That's what happened to me in the first attempt)
Darn. I missed ONE mod sign :(
it was x=0 i think;(
That was test case = 9
How was in Problem C 'n==1' solved??
Just as n==2,n==3,n==4 and so on.
because at the end there will be twice the dresses, but there can be one less dress with 50% probability, so at the end there will be 2 * x and 2x + 1 dresses each with 50% prob. Rest is simple.
This gives f0 = x
answer is twice of fn
I have a doubt. Suppose I submit a solution which passes all pretest. Then I submit a solution which fails on pretest. Will then only my 1st solution be considered ? Or i will have some penalties?
Just the 1st one
My idea for D:
at most I will multiply with 62 numbers greater than 1, so for every number I store the next number greater than 1, and I should take care of the ones between, am I missing something???
No, that it.
I did the same thing.
I did the same but i messed up somewhere.
It seems like I also had some bugs :(
RIP ratings.
This round makes me realize how poor my math is.TAT.
In problem A i was having time limit exceeded on pretest 6 as the judgement. Did any one face the same problem and knows how to fix that?
your code link ??
http://codeforces.net/contest/992/submission/39384811
It's kinda obvious your solution works in O(n^2) for n = 1e5. No surprise you got TL.
can you explain more why that obvious?
_
1) He said he got TL6, not WA1. He just post the wrong link. 2) It's obvious that is was some debug output and he undestands he shouldn't use printf instead of scanf. 3) Now he posted correct link.
Suppose there is no a[i] = 0; Then your code is simmilar to:
Still not obvious?
There is a nested loop in your code:
This nested loop takes O(n2) time.
Note: For this problem, I recommend you to use set data structure.
Your code complexity if N*N (as your code runs n times for every outer loop.) So n*n statements minimum. Generally 1 sec = 10^8 operations. and here n=10^5 so n*n = 10^10 so it will take 100 secs. That's why you are getting TLE. Hope it helps.
div2B was not made for div2B.
Problem E was really nice.
Because you solved it :D
I solved D too that wasn't nice at all!
Well, you don't solve E in every contest ;p
How to solve DIV2 C?
Observe that after k months, there can be 2k * x, 2k * x - 1, ... , 2k * x - (2k - 1) clothes in the wardrobe, with equal probability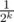 .
.
By using definition of expected value, we find that the expected number of clothes after k months is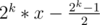 . The answer to this problem is twice of this number, i.e. 2k(2x - 1) + 1.
. The answer to this problem is twice of this number, i.e. 2k(2x - 1) + 1.
Note the special case: if x = 0, the answer is 0 no matter what k is.
I used the same logic still kept getting error on pretest 5. http://codeforces.net/contest/992/submission/39380228
Most likely overflow.
You should append LL to numbers you intend to be used as long long, e.g. "2LL"
Thanks :)
Me too bro :(
You have taken a negative without adding a MOD.
For solving it use
Still try to use mod after avery arithmetic operation
oh gosh!! Thank you so much for pointing it out. I had totally missed it.
F**K only because of x=0 special case I was getting WA.
Let f(x, k) be the answer for input x and k.
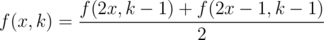
Then we have the recurrence,
For k ≥ 1,
and f(x, 0) = 2x.
By induction, you get f(x, k) = 2k + 1x - 2k + 1.
Use repeated squaring to evaluate the powers with the right modulus.
Can D be solved using two pointer both starting from beginning ?
nope. The solution comes from fact "ones are useless"
Forgot to take mod in C fml. Also can someone tell whats wrong with my code for D — http://codeforces.net/contest/992/submission/39387013 ?
5 2
1 1 2 1 1
Your solution fails on this case, ans should be 3
B is a bit too hard, and the problem involved a lot of maths, but the problemset is nice overall. I liked B and D the most.
Also, I appreciate the fact that pretests is strong and included corner cases (n = 0 in C).
Problem E smells like an interesting problem as well. It's the kind of problem you think you'd go like 'aaa, hmm, mkay, that's pretty cool' haha
I didn't come up with that observation (I thought the upper bound is at first, so RIP). But now knowing that, I think E is also a cool problem.
at first, so RIP). But now knowing that, I think E is also a cool problem.
For problem E, can we solve sqrt(q) queries at a time by pre processing for each sqrt block. My idea is to find all the indices that are updated in that block and then we make a new array having all the subsequent indices that are not updated together as a same element. We can maintain the sum of that element and also create a map to check the sum requirement of all the indices in that element, while for indices that are updated, we can check if the prefix sum till that element is equal to that element. Time Complexity will be O(n * root(q) + q * root(n)).
What was test case 5 for c?
x==0
It should not be x == 0 as I had considered it a special case and printed 0(verifying)
Yes I'm sorry that was pretest 9. Messed up a lot today :/
Solution of problem B already exists on the internet. link : Click . Found it after the contest!
How to modify it to include the range specification?
Edit:
Nevermind, like a tilted fool I read the wrong block of code and didn't realize it wouldn't run in time, give me a minute
That solution would give TLE because it iterates all the numbers until 1e9
If you read the efficient solution which was given in the link above, you can see that the answer is 2^number_of_distinct_prime_factors(lcm/gcd). You can do this: bruteforce through all pairs of numbers that can be formed using distinct prime factors of lcm/gcd such that their multiplication is equal to lcm/gcd, and add to answer if both of them are in range [l,r]. That was my solution (not the best one i think, but it passed).
Its not same at all. You also have to check if a and b are between l and r, which requires a lot more work.
What is pretest 9 in D and why did it bend me over?
probably x = 0, I completely forgot about it
i think thats problem c
sorry, i misread your comment
Found it ! For the case of segments in which the product is 1 I made a mistake and took the cases in which sum = k and product = 1. Changing that fixes everything ! :(
Thanks for strong pretest of Problem C. To me it was easier than Problem B.
Same, I had problems with B corner cases and I didn't bother reading C because there was little time left. After the end of the contest I coded C in literally 5 minutes.
Same situation :(
Why is the system testing happening so slow?
I think is due to the many submissions for problem A.
pretest 5 in B? Coldnt pass it
Case when y is not divisible by x.
Am I the only one who really loves math problems?) Thanks to authors, problems were really nice, though harder than ussual.
The math skills...
The amount of number theory and partial sums is strong with this one.
What could the test case 63 be for Div2 C?...I see many WA's on that test (including mine).
x is multiple of 1000000007
Such a cancer test case honestly.
Bad luck keeps hitting me at contest.
Such a cancer comment, honestly.
Sorry the community if i'm being too negative or toxic,but honestly when i failed that test i can't hold the feeling,i feel like such a loser.
Again,sorry for writing a stupid comment.
spj_29
the writer of problem B is germa 66 fan
How is problem B related to Germa 66? There's barely any backstory to the problem.
most WA are on 66 testcase
Is a lot of test case the reason of this very slow system testing ?
In problem D, what is the maximum p, such what p/s=k exists?
well i know that you could just simulate the entire problem, like iterate for i, then for j with j > i and with some optimizations like, jump over sequences of 1 and when current p is much bigger than s + (n — j) because p rises much faster than s the situation is unrecoverable so you stop the second iteration because you are sure to have no solution with current i ans j' >= current j, Getting a nlogn complexity. Now for your question the answer is s * k
1) s is not fixed. 2) If we say that s = n*max(a) and k=1e5, when p=2e18 can't exist, because all of the numbers would be 1e8, and that means 1e8^n=2e18, which is false.
You can take
to get
Not sure if that's the worst case, however.
Intuition: k should be max (10^5). We would like to use a small number of numbers because otherwise, p is going to be extremely large. So we would use 2 numbers. We would like one number to have the maximum value. So the equation is (10^8*x)/(10^8+x)=k. X is slightly more than 10^5 -> maximum p is slightly more than 10^13.
I didn't prove it but I think it's right and should be easy to actually prove.
It could overflow even unsigned long long. I have checked that a*b < 10^y with log10(a) + log10(b) < y.
Also, I've accidentally set the limit to 10^13 in my solution and it passed.
UPD: yes, maybe such test is impossible to create so that's just an upper bound.
I know that's no argument, but my solution passed with 10^11 as a limit :D
I was for a minute scared, what product can be 2e18, because i used >= and not > :D
Hello Qumeric In problem C : in this solution link i have used modInverse but in this solution link i haven't because i just had to divide the variable by 2 and my numerator is already %M.... Can you please tell me why my answer was accepted in the first case and not in the second? ( M = 1000000007)
Let`s think answer is 500000004. Then before divide you should have 1000000008. But you use modulo calculations and you have 1 instead of 1000000008. If you use modulo inverse you get correct answer. But if you divide by 2 you get 0 (1/2 = 0).
Dear author(s),
Thanks for including n = 0 in pretests (Problem C). Thanks for not making it hackforces and saving my rating...
for C, the correct formula is 2^(k+1)*x — (2^k — 1) ? [after applying proper modulo] If yes, then why is my submission giving wrong answer? 39389996
Should be overflow somethere.
Take modulo of X before multiplying with 2^(k+1)
Hello darkhorse7 In problem C : in this solution link i have used modInverse but in this solution link i haven't because i just had to divide the variable by 2 and my numerator is already %M.... Can you please tell me why my answer was accepted in the first case and not in the second? ( M = 1000000007)
please attach the solution link
oh sorry! in this solution link i have used modInverse but in this solution link i haven't because i just had to divide the variable by 2 and my numerator is already %M.... Can you please tell me why my answer was accepted in the first case and not in the second? ( M = 1000000007)
you have to print ans modulo 1000000007. so you can't simply divide by 2. read this Link
But my numerator is already % M and dividing by 2 would further reduce it then why do i again need to do %M?Please tell....
you have to print (a/b) % m, what you are printing is (a % m) / b
if(b == 0) return 1;
if(b == 1) return a%mod; // ( not a )
Yeah, now that I'm yellow I want to say that my D is wrong ):
It fails for this testcase:
I think the answer is 3, but my code prints 2... I don't know how did it pass system test while failing on that simple case.
I don't deserve this :'(
Anyways, it gave AC 20 seconds before the end of the competition, so that was pretty cool (?
Your ac code is indeed printing 3. https://ideone.com/CHh3Yb
Well that's rare... I ran it on custom invocation and locally, and it printed 2.
Isn't 2 correct? (1, 1, 10, 3) and (10, 3, 1, 1), or am I missing something?
Why leave (1, 10, 3, 1)?
Oh yes I missed that, thanks
How calculate lcm in Div2 B?
lcm(a, b) = a * b / gcd(a, b)Yes it is, but it overflow in test (10^18 * 10^18 / (gcd(10^18 * 10^18)), may be another way?
Yes :)
lcm(a, b) = a / gcd(a, b) * bOH, my math is very baad, thanks!
For the input 1 12 1 12
Why (2,6) isn't a good solution ?
because gcd(2, 6) = 2
The limit is 10^9. 10^9*10^9=10^18. Overflow is not a problem
Oh, you are right, mistake in another.
or you can do this (a/gcd(a,b))*b
can anyone explain D ??
p/s=k; p/s<=k; p<=s*k<=2e18, so there will be at most log_2(2e18) elements in subsegments not equal to 1.
I fst in D in the 132nd test. However,I run this test on my own computer,it gives the right answer immediately. It makes me fuzzy. Here is my code:code link Can anyone give me a explanation?
UPD: I resubmitted the same code in C++17 and C++11, both get AC. Only in C++14, I got TLE again.:(
UPD2: It is due to compiler's(C++14) optimization(level 2 and above). (My undefined behaviour first, it's my fault.)
First of all, how can you run the test if the test is not fully available? :D
More to the point,
This is NOT the right way of testing for overflow. In the C++ standard, you can read that signed integer multiplication overflow causes undefined behavior, which means that you have no guarantee of what happens. It also means it might run well on your machine, but not run the same way on the judge.
The proper way to test for overflow is something like this:
This avoids undefined behavior. Have a look at this submission 39391459. It's your code, but with proper overflow checking. It gets AC.
P.S. I learned this the hard way. To understand how wild undefined behavior can be, I've had this assert (multiply two non-zero numbers and get a zero result) pass on some online judge:
Thanks a lot.
Though my rating is declined, I'm pretty happy to learn something new.
Suppose mod is prime.
We know that (1/a) % mod is equivalent to (1 * a ^ (mod — 2)).
So what is (1 / (a ^ m)) % mod ?
Both approaches in Problem C resulted in AC. I just want to make sure if those are actually correct and if you want, you can also include the proofs.
Not good at math. Only surviving by using theories and luck at appropriate places. :|
From the exponentialtion laws we know: (ab)c = ab·c = ac·b = (ac)b Therefore:
So both approaches are fine.
Got an idea for E 1:58 into the competition... Damn :D I understand the normal solution, but can someone who solved this with the sqrt decomposition elaborate? I didn't understand the comment that was posted here about it :)
Most sqrt-decomposition solutions gets tle :D Idea is to make sqrt(n) blocks of size sqrt(n). If you store b[i] = prefix[i-1]-a[i] then you update, you need to decrease b[pos] and increase b[pos+1, n]. So for every block store this: all possible values of b, lazy value what is needed to be added, and some king shaman. So you need to fix the block with index i/block_size. And then for every following blocks add value to lazy, and find some shaman using lazy value and some map for all values of b.
Thought about the prefix minus value and look for zero, but got stuck on n*n solutions. Really cool! Thanks :D
other sqrt decomp solution: http://codeforces.net/contest/992/submission/39380451
Main idea:
in some block , we will keep values of form val[pos] — block_sum[pos — 1] and we sort them
1) to update val[pos] = x, we update block of x only (just recalc the values)
2) for query, we go through all blocks b1, b2.... bk (which takes O(k = number of blocks))
Say you have sum of first p blocks. Binary search for that sum in block bp+1. If it exists in block bp+1, we have a king shaman
Wow man! This is quite amazing that this is working! Tried compiling it with std::map and got a tle. but using vector of sized 64 apparently is a gamechanger — worked with a time of 1300ms...! sorting once and doing a binary search using bit is a-bit wow haha but kudos it's amazing you got this to work.
I got quite intriguied by the idea and played with it a lot ( you can see the last 50+- submissions of mine haha...), This is the best working version I got:
64-decomposition + your efficient binary search + memory reuse + arrays instead of vectors. http://codeforces.net/contest/992/submission/39407122 1263 ms
Does anyone have an idea why the 64 "magic" works? trying to use 256 or 512 which are closer to the sqrt(2e5) is way better complexity wise, but works like hell. Cache misses?
Thanks for the delightful problems.
Did anyone else here get tle on test 132 in problem D?
Here is what I did:
Since the product increases very fast, for every end index I found the starting index such that p > 2e18 in by iterating over every element. Meanwhile, I updated the count of required segments. It takes at most log(2e18) time. For cases when the elements are 1, I checked in O(1).
my code
What can be the possible mistake?
This comment will help you.
It was one of the most interesting contests that I had participate before thanks for this great contest ^_^
39389999
i was iterating over accepted submissions on the problem E and I've seen that one that i can't understand why it's not getting tle... if we have an array of zeroes and in each query we change the last element to something ...
the segment tree is obviously okay but the "beriz" function seems not okay to me at least ...
because its iterating over all segments that they're min is not positive and go down until the length of the segment is 1 and in my array his function i think will iterate over all elements of the array so that the order seems to be o(n*n)
someone plz help me with my problem ...
these code got ac so it's correct but i don't know why ...
i know the solution of the problem since I've got ac !
His solution is O(n^2) and TL (works more than 5 minutes) on test like this:
n = 1e5, q = 1e5
a_i = 0
p_i = 1, x_i = 0.
If I'm not wrong, I guess, authors tests aren't strong enough.
Shot dead!
Ralsei nice catch (your test is now #95).
Can someone explain algo to use in div.2 D? Seems like editorial is taking time :).
An easier version that helps inspire a solution for the original problem: What if the smallest number in a[] becomes 2? That brute force tag seems fishy.
E solution w/ parallel binary search + segment tree since only sqrt-decomp solution is revealed here:
First step: Reduce the constraint a little bit — Let's say the shamans are claimed as "god-kings" if they have powers at least as much as their predecessors (instead of being exact). Note that the god-king set is a superset of the original king set, so we can check all elements of god-kings to see whether they are exactly kings.
How large is the god-king set? O(lg 1e9). Why? Consider all god-kings (i) in the set, observe that power[i] > sum(power[0:i]), so the power of the next god-king must be at least sum(power[0:i]) + power[i] >= 2*power[i-1], i.e. roughly twice as powerful as the previous one (except in constant corner cases, eg: sample 2, power[0] = power[1] = 2 results in both shamans being god-kings but no.2 is not twice as powerful as the previous god-king), thus the log factor in the complexity.
Now you'd just apply segment tree / BIT to support sum(power[0:i]) queries, and find the first element which is larger than sum(power[0:i]) with parallel binary search.
39403776
I think my solution is similar to yours . Why it gets TL at test 8 ? Thx.
The segment tree query function for sum query is a bit off, it misses a line which returns the sum directly if the current segment completely lies within the current range.
39407362
Something it's still wrong though.
Edit -- And long long. 39407764
Oh..Thanks.I typed the wrong segment tree and i haven't noticed that . I deleted some useless optimization and gets ac. Thanks again
i got A in 2 mins i got B in 99 mins i got C in 93 mins but wrong (sad face) i am in 6th grade