


There are N (<= 2*10^5) 2D points with coordinates x,y and cost c. There are M (<= 2 * 10^4) queries, each query is a point (x,y) with cost c. For each query, you need to return the point with cost <= c that is closest to the query using euclidean distance. In case of ties, return the point that appears first in the input. The full problem statement can be found here: https://icpcarchive.ecs.baylor.edu/external/77/p7744.pdf.
Any ideas on how to solve it? I've got the feeling that some efficient spatial partitioning data structure might be of help, but I'm not sure of which one. For instance one idea I have in mind is to sort both the points and the queries by their costs, and then use 2 pointers, so that one pointer advances through the queries and the other pointer advances through the points, and as I advance through the points I insert each point to some dynamic data structure that would allow me to quickly find the nearest neighbor to the current query (and somehow break ties using the point indexes). Using this strategy, a static data structure such as a kd-tree would not work because the structure would need to be dynamic (support updates). So I just googled dynamic spatial partitioning data structures and for instance I found R* trees, but I'm afraid that learning R* tree might be overkill for competitive programming (?)
Any ideas/hints/suggestions will be appreciated.







Auto comment: topic has been updated by pabloskimg (previous revision, new revision, compare).
I'll throw some ideas in here and come back to this problem later (tomorrow probably) since nobody answered it.
I'll assume that you have a structure that can answer "what's the closest point to (x, y)". Since I've never coded something like this, I'll just link this post that could be useful: https://codeforces.net/blog/entry/54080.
This solves one part of the problem but you have to make sure that you get points with cost <= c and there's a simpler way than making a dynamic structure that just adds a log to the structure. For this part, you can create a segment tree (or fenwick tree since cost <= c and not l <= cost <= r). The tree in this case is a tree of structures that solve the problem above and you can answer the queries directly using this structure. The sugestions for trees above use O(N*logN) memory but there are also O(N) alternatives. This solves the problem in O(answer one query in the "closest neighbor" structure * logn) regardless of the structures used.
K-D trees can be updated dynamically but it looks like dynamic updates should make the code way more complex (not sure since I never coded it). This proposed solution should solve this problem in at least O(N * logN for construction maybe with an aditional log depending on how you construct the structures) + O(M * sqrt(N) * log(N) for answering queries) but it might solve the queries with a good constant.
Ninja edit: Now looking at that complexity of O(M * sqrt(N) * logN) you can also solve it using sqrt decomposition in the cost. Have a buffer of points and use a sweep line over the cost. When the buffer of points has more than O(sqrt(N)) reconstruct the structure so you'll need to query the structure and go over the whole buffer to answer one query. This makes the complexity O((N + M) * sqrt(N)) and with a better choice of the maximum number of points in the buffer you might achieve even better complexity since the complexity is O(N * N / K + M * K + M * sqrt(N)). Looks like the best choice would be around K = N / sqrt(M) and it would achieve O(N * sqrt(M) + M * sqrt(N)) complexity.
With respect to using a fenwick tree to combine the answers of O(logN) structures per query, that should give a complexity of O(M * log(N)^2) for answering the queries, which seems to be fine, but that's assuming we already have a structure built for the range of each position in the fenwick tree. A fenwick tree has length N, and each position maps to a range whose length is roughly O(N / logN), so for example if you build a kd-tree for each range, you would have to build N kd-trees, where each kd-tree would contain O(N / logN) points. If you build a kd-tree with K points in O(K*logK), then the full construction complexity would be O(N * N/logN * log(N/logN)) ~ O(N^2), so if my reasoning is correct the construction step would give TLE before we even start answering queries (?).
"A fenwick tree has length N, and each position maps to a range whose length is roughly O(N / logN)."
That's not true, each position i maps to a range of size LOWBIT(i), where LOWBIT(x) is the least significant bit of x. Summing up the sizes of each range gives us a total size <= N*logN.
Good point. I was thinking that the answer for an O(N) range required combining the answers from O(logN) positions in the fenwick tree, so my naive estimation was that each position in the fenwick tree would be in charge of a sub-range of length O(N/logN) on average.
Do you know the formal proof that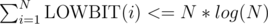 ?
?
Instead of LOWBIT(i), consider the positions that the index i will be included in. There will be at most log(N) such positions for every i. Think about update in a fenwick, the positions that you pass through in the update are the positions that I'm talking about.
wow, you are absolutely right! I didn't think about it like that. Instead of adding up the lengths of all the sub-ranges, we can just add up the number of sub-ranges each position is contained by, and as the fenwick tree's update operation shows that's just O(logN) per position. That reminds me that I still don't understand the correctness of the fenwick tree's update operation, I just take it for granted.
Another issue is how do you efficiently break ties when multiple hotels share the same minimum distance to the current query? No idea of how to do that.
I think you can modify the "closest neighbor" query to "every closest neighbor" query without much trouble, the bound looks at first O(log(N) * K + sqrt(N)). That + the fact that there are few (dx, dy) with (dx^2 + dy^2) == dist, should solve that part.
There is also another way to make a static DS expandable: Create data structures of size 1, 2, 4, 8, ..., n. Adding an element to the DS is similar to incrementing a number's binary representation, where we rebuild the DS of size 2k + 1 from scratch every time there are two sets of size 2k. (see https://codeforces.net/blog/entry/48417, section 4)
data structures of size 1, 2, 4, 8, ..., n. Adding an element to the DS is similar to incrementing a number's binary representation, where we rebuild the DS of size 2k + 1 from scratch every time there are two sets of size 2k. (see https://codeforces.net/blog/entry/48417, section 4)
I almost mentioned that but decided that using a fenwick is simpler. That's the O(N) alternative that I talked about. Do you know the name for that trick? I call it binary representation partition since someone proposed that name to me and I liked it.
I don't think it has a name. dacin21 also mentions it, without giving it a name: http://codeforces.net/blog/entry/52695?#comment-368275, http://codeforces.net/blog/entry/59694#comment-433345
I'm not sure if I'm getting it. If you have logN DSs, where the k-th DS is in charge of the first 2^k elements, how do you answer queries for, say, the first R elements where R is NOT a power of 2?