


On CF 256 Problem A, I use lower_bound to binary search on a std::set. However, I've found that using std::lower_bound(set.begin(), set.end(), val) makes the solution blow up, resulting in TLE (>3000ms), while using set.lower_bound(val) works perfectly fine (~300ms).
AC (358ms): 48402685 TLE (3000ms): 48402684
It appears, then, that std::lower_bound(set.begin(), set.end(), val) is not actually binary searching. What is causing this behavior?
Thank you!






See the "Complexity" section of std::lower_bound. In particular,
std::setiterators are not random access, so you'll degrade into linear-time performance from repeatedly incrementing iterators.std::set::lower_boundon the other hand is a specialized implementation that does binary search within the BST, so it takes log time.lower_bound(s.begin(), s.end(), value)is O(n). For exmaple it computes the distance between s.begin() and s.end() and this is already O(n). Then it is doing standard binsearch. Generallyset<T>::iterator itis not a random access iterator. So you can not easily compute let us sayit + 2137.s.lower_bound(value)is O(log n) and uses red-black tree structure for computation.I think it is not O(n), but actually O(n*logn*logn).
Well, ok. Maybe I wrote it too fast. But it is O(n log n) at most.
it++is O(log n) so naively we have:T(n) = T(n/2) + O(nlogn)Which by master theorem, or just by common sense is O(nlogn).But when you are doing
it++from the beginning till end, then you are not traversing the same RB-tree edge twice in the same direction. So I believe there is some amortization. Then it would be O(n) as I wrote.http://www.cplusplus.com/reference/algorithm/lower_bound/
It doesn't account for the cost of actually moving the iterator (e.g I could do an iterator that is incremented by 1 in O(N) and it will become quadratic)
Still for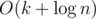 so overall it will be
so overall it will be 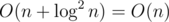 . Not sure it's guaranteed by standard though.
. Not sure it's guaranteed by standard though.
std::setit's easy to see that incrementing by k will work inAlso in the problem CF1041C, I get TLE by writing lower_bound(s.begin() , s.end() , val).
But in the other hand, there's still some problem that I used lower_bound(s.begin() , s.end() , val), and it does not give TLE. For example, Submission of CF 749D, an another account of me. Can anyone gives me the reason?
As fruwajacybyk mentioned,
std::lower_boundcomputes distance between given iterators. If given iterators are random access iterators (as they are forstd::vector), then distance is computed in O(1). But forstd::setiterators are not random access, but bidirectorial, thus, distance is computed in linear time. Then, while doing binary search,std::lower_boundfinds an element in the middle in O(1) for random access iterators, and O(distance) for bidirectorial iterators.But it's also a problem about set...
I guess that maybe because of some reasons, the size of one set or the set together is small enough (For example, the sum of their size do not exceeded 1e5), so that the total computed time is fast enough to pass the problem. :)
P.S. My English is bad, please don't mind.