


Hi!
Topcoder SRM 753 is scheduled to start at 11:00 UTC -4, March 20, 2019. Registration is now open for the SRM in the Web Arena or Applet and will close 5 minutes before the match begins.
Editorials: https://www.topcoder.com/blog/single-round-match-753-editorials/
This is the fifth SRM of Stage 3 of TCO19 Algorithm. This stage will also help you qualify and win reimbursements/tickets to TCO19 Regional Events.
Stage 3 TCO19 Points Leaderboard | Topcoder Java Applet | Next SRM 754 — March 30
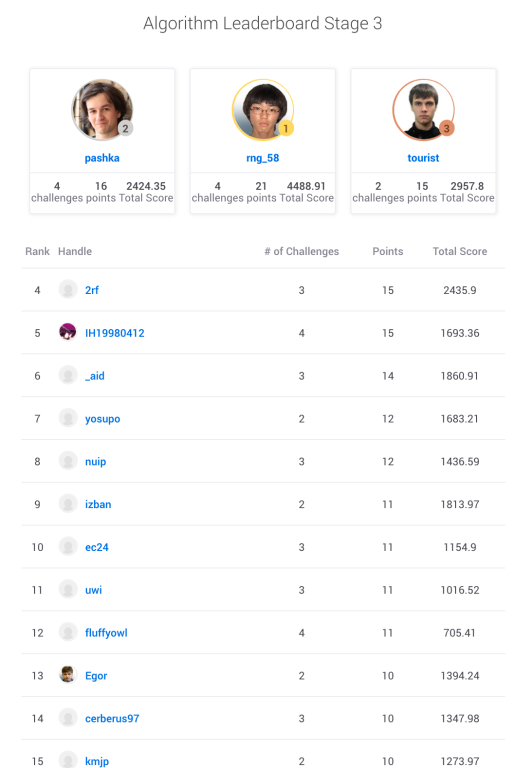
Stage 3 Leaderboard
All the best!







Clashes with second qualifying round of BSUIR Open 2019 :(
Gentle Reminder: Match begins in an hour :) Hope to see most of you competing!
is this a div2 kinda round? this is gonna be my first actual contest on topcoder.
Great idea to make 500 basically the same problem as 1000, but harder xD
gg to everyone who tried writing seg tree with rollbacks similar to dynamic connectivity. And then editorial claims some usage of randomised data (yet to read).
Yeah, I thought of this, I noted this analogy to dynamic connectivity as well, but lacked time. But it seems quite many people managed to get it passed. Editorial is kinda clever, kinda naive. It is kinda easy to construct linear generators in form of a[i] = c * a[i — 1] + d, so that input becomes monotonic or periodical with short period etc and then it is far from being random. Moreover, TopCoder used to put a note that solution doesn't use any properties of pseudorandom generator in problems that required big input. Here it was not put and reason is self-explanatory — since solution used this pseudorandomness, but it definitely causes confusion. Should I add considerations whether pseudorandomness of input might help me and whether am I not screwed by some definitely not random examples of pseudorandom generators to basically half of topcoder problems?
excuse me , but what's this 500 problem in div2 , it's very big problem statement and it's more than 100 words , I know the problem isn't that hard but why this long statement , problem could have had short statement
A much easier solution to Div1-300 was to just find bridges. Then, we can see that the graph formed by only bridges and adjacent vertices will be bipartite. So, we just need to find maximum independent set which is done by bipartite matching leading to a 10 lines code except template. Code-
And what do you think is model solution doing? The same, but it takes advantage of the fact that bridges induce forest to make it even easier, not an arbitrary bipartite graph.
Even though bipartite graphs is a broader class, for me it was easier to do the following: it can't have a cycle as the edges wouldn't be bridges -> it means it's a tree -> it means it's bipartite.
At this point you have an alternative to do dp on a tree or matching on a bipartite. The difference is in complexity though and they usually describe only the best solutions in editorials.
I also remeber other SRM where we had a matrix n x n and were looking for some square. They described O(n^2) solution with case analysis whilst much simpler O(n^5) was enough to get the task.
You don't even need DP on a tree (forest), you can do a very simple greedy. When looking for the minimum vertex cover of any tree, find any leaf and take its only neighbor into the vertex cover.
(Proof: Any solution that takes only the leaf can be converted into a valid solution of the same size that takes only the other vertex. Any solution that takes both isn't optimal, and any solution that takes none of the two isn't valid.)
As the constraints are so small, this is really easy to implement: you can just keep a vector of uncovered bridges and in each iteration you find a vertex that is mentioned exactly once in the whole vector.
Min vertex cover in forests using bipartite matching. Maybe that's not a bad idea. Nowadays I use Berlekamp-Massey to compute $$$10^{18}$$$-th Fibonacci number. It's just copypaste, and the biggest time is spent on finding my library document.
I keep getting 0 points in recent SRM's but due a big portion of other contestants also getting 0 I don't fall down to Div 2. Maybe calibrate difficulty a little bit?
Difficulty is good. Tasks are getting more interesting again. You don't want to get back to times, when nobody wanted to prepare tasks for TC and nobody wanted to participate.
Why earlier no one wanted to participate on toc ?
Because the tasks were really bad. Nobody wanted to prepare good tasks, so they started taking some old XX'th century archived tasks.
I'm having some trouble with remembering graph definitions, not specifically about this problem. Say we have a graph G = (V,E) with two vertices and one edge between them:
V = {0,1} // vertices
E = {(0,1)} // one edge
If we delete this single edge and E becomes {}, this SRM problem would say that the adjoining vertices are also deleted, and the vertex set V becomes also {}.
But is it possible in some definitions of graph operations that only the edge is deleted; V remains {0,1}, and therefore 2 connected components are left when we delete the edge? Again I know that is not the right definition for this problem, I'm just asking if this second way is always a wrong way of defining edge-deletion, or could be a valid definition in other cases. For future reference.
In general: when you delete a vertex, you delete all edges with at least one endpoint on the vertex. But when you delete an edge, you don't eliminate any vertex. This is because a vertex can exist without any edge, but an edge with one endpoint in a non existing vertex doesn't make sense, so it is deleted.
Thanks for the answer. Interpreted that way, deleting the edge in my example would leave two vertices in the graph, so the answer for the SRM problem would be "2" (or just "n" for any graph). But the SRM problem correct answer is "1". So is your interpretation standard, or the SRM problem's definition of deleting, the standard? That's what I'm trying to understand.
Read the statement carefully. It says you are to keep some subset of vertices. Which is equivalent to deleting some other set of vertices (the complement). By erasing a vertex, you erase all edges adjacent to that vertex, thus erasing all bridges with one endpoint in that vertex. So to erase the edge {0,1} you should delete either vertex 0, vertex 1, or both. Optimal answer is to delete one vertex (any one).
OK, so I know why the wording was in terms of "Subgraph of G induced by a set S of of vertices". I was wondering why they defined it that way. Thanks!!
Div I Easy/Div II Hard is a great problem. But editorial is not so great. Explanation is too short, code is not syntax highlighted, and in code functions are called "hi" and "hello" and there are some checks (like if(parEdge>1), for duplicate edges) that are not possible by problem statement.
it simple mean that author is not intereseted in writing editorials . so bad editorial for 753 round huh !
Editorial solution for div1 hard works in 2.844s and the time limit is 3 seconds, that's not cool.
I have a general question, but d1 500 is a good example. It uses the fact that the sequence is pseudo-random. However, even though it is pseudo-random, it appears in the top coder's tasks quite often. And quite often the randomness of the sequence has nothing to do with the actual solution.
So the question is: how can you deduce, that you should use the pseudo-random way of generating the sequence and it is not only a way to provide a larger data through a limited top coder API? It should be also clear that it is not easy to generate a worst-case scenario during the challenge phase.
I noticed few times a note, that the solution does not use the way, in which input is generated but is it always the case? Which means if there is such a note, then we don't assume the sequence is random and if not, then we assume the sequence is random?