


302A - Евгений и массив
Если длина отрезка — парное число, и количество 1 и -1 по отдельности не меньше половины длины, то ответ положительный.
302B - Евгений и плейлист
Запомним для каждой песни момент, когда она окончится (например частичными суммами). Дальше просто бинарным поиском или двумя указателями найдем максимальный номер песни, что ее конец не меньше заданного числа.
301A - Ярослав и последовательность
С помощью поиска в глубину посчитаем сколько отрицательных чисел мы можем получить. Заметим, что можно сделать либо все числа положительными либо одно число отрицательное(показать это просто, если изменить знак у числа Ч и некоторого набора чисел, а затем у числа У с тем же набором). Если можно получить все положительные числа, то ответом будет просто сумма модулей чисел иначе нужно поменять знак у числа с минимальным значением по модулю.
301B - Ярослав и время
Бинарным поиском будем искать ответ. Далее воспользуемся простым алгоритмом Форда-Белмана. На каждом шагу будем хранить максимальное значение таймера при нахождении персонажа в конкретной вершине, при переходе будем проверять: не умрет ли персонаж при переходе между вершинами. Если переход возможен, то будем обновлять значение конечной вершины. Благодаря тому что a_i<=d и координаты — целые мы не получим циклов.
301C - Ярослав и алгоритм
Нужно воспользоваться тем, что у нас есть знак вопроса(возможно, есть решение, которое не использует этот знак). Поставим знак вопроса в начало строки. Далее будем двигать его пока он не достигнет конца строки. Далее заменим его на два знака вопроса. И будем тянуть их к началу пока перед ним находится число 9, как только мы нашли другую цифру — просто увеличим ее и закончим алгоритм. Если мы дошли до начала строки, то просто поставим 1 в начало и закончим алгоритм.
Смотрите любой прошедший код для большей ясности.
301D - Ярослав и делители
Зададим все пары вида: (x,y) ((d[x]%d[y]==0) || (d[y]%d[x]==0)). Задавать такие можно с помощью решета Эретосфена. Пар заданного вида будет порядка O(n*log(n)) благодаря тому, что нам задана перестановка. Дальше с помощью сортировки подсчетом отсортируем их. Отсортируем заданные на входе отрезки. Дальше для каждого такого отрезка нужно посчитать кол — во вложенных из заданных ранее. Такую задачу можно решить с помощью дерева Фенвика. На каждом шаге добавлять отрезки в порядке сортировки по правому краю. На каждой итерации будем обновлять Дерево Фенвика, которое сможет считать количество начал уже добавленных отрезков на отрезке. С помощью такой информации легко найти ответ. Сложность решения: O(n*log^2(n)), учитывая, что мы используем дерево Фенвика. Константа в решении очень маленькая.
301E - Ярослав и расстановки
Будем строить нужные нам массивы последовательно добавляя числа. Давайте посмотрим на то, какие параметры нам нужны. Во первых, очевидно что нужно хранить количество способов построить массив на уже добавленных числах, во вторых нужно знать общее количество добавленных чисел. Теперь посмотрим на то, что происходит когда мы добавляем новое число(то есть число, большее всех предыдущих в некотором количестве). Понятно, что добавленные числа должны стоять между числами на 1 меньше. При этом если мы поставим 2 новых числа подряд, то между ними должно стоять большее(так как меньшие мы уже расставили). При этом очевидно, что нужно покрыть все предыдущие числа(между которыми должны стоять новодобавленные).Таким образом имеем еще один параметр: количество чисел, между которыми мы можем ставить новые. Таким образом мы имеем динамику от четырех параметров: dp[all][ways][lastnumber][counttoadd].
Переход.
Понятно, что нужно добавлять не менее counttoadd чисел, но как это повлияет на количество способов расставить числа? Все просто. Пусть мы добавили x чисел, тогда количество способов нужно будет умножить на величину Q(x-counttoadd, counttoadd), где Q(x,y) — количество способов расставить x одинаковых шариков в y разных коробок. Q(x,y) = C(x+y-1,y-1), где C(x,y) — биномиальный коэффициент.







Не понял вашего решения 301D — Ярослав и делители.
1) Что посортируем подсчетом? Пары? Перестановку?
2) Что с отрезками проихсодит вообще не понятно. "Отсортируем заданные на входе отрезки" по какому критерию? L^2+R^2 ?
3) Зачем нужно знать количество отрезков, которые содержатся в каждом?
1). Пары.
2). По Р(далее сказанно)
3). Это будет ответом на задачу.
Блин, нихрена же не понятно. Минут пять втыкал что пары и отрезки это одно и то же. То что на входе вы тоже отрезками называете. Если кто не понимает манеры изложения автора, то поясню что "Отсортируем заданные на входе отрезки. Дальше для каждого такого отрезка нужно посчитать кол — во вложенных из заданных ранее" следует читать из полученных ранее, то есть тех что мы получили решетом эратосфена (еще точнее "отображение" этой пары на инпут (min(posInP[a], posInP[b]), max(posInP[a], posInP[b])). Искать для входных отрезков количество вложенных входных отрезков полная бессмыслица.
Я думал, что это очевидно.
Что очевидно? Неочевидно, что вы вдруг пары стали называть отрезками, а затем искать количество отрезков в отрезках. Конечно сложно понять что к чему при такой манере изложения.
Ну да ладно, сложно оценить понятность объясняемого собой, потому как тебе то все понятно.
Мое решение было другим. Я шёл по массиву справа налево и для числа на позиции i искал все его делители и кратные ему с правой стороны (то есть те, которые уже были обработаны) на их позиции делался инкремент в дереве фенфика. Как число на позиции i обработано, обрабатываем все запросы с L = i посто считая сумму с L по R
301A: Что есть вершины, что есть ребра, можно поподробнее?
Вершины — количество отрицательных чисел. Ребром соединены те, между которыми можно перейти за 1 ход.
Вы крайне подробны.
"Вершины — количество" — правильно ли я понял, что вершины сами отрицательные числа? Между какими отрицательными числами можно перейти за один ход?
Пусть у нас на входе:
-1 -2 3 3 3
Всего 2 отрицательных числа.
Можно получить 5 отрицательных, например:
-1 -2 -3 -3 -3
Можно получить 1 отрицательное, например:
1 2 -3 3 3
Можно получить 3 отрицательных, например:
-1 2 -3 -3 3
Собственно из состояния 2 мы можем перейти в 5, 1 и 3 за один ход.
P.S. Я правильно понял Sereja?
А как быстро узнавать в какие состояния можно переходить из текущего?
Допустим у нас X отрицательных чисел.
Забудем про нули в массиве.
Перебираем i от 0 до min(n,X): сколько отрицательных чисел станет положительными, min(n-i,z) чисел же станет отрицательными, где z — количество положительных чисел.
Следовательно мы можем перейти из текущего состояния в состояние X-i+min(n-i,z).
Вроде нигде не ошибся. Надеюсь понятно.
UPD1 Работает за N^2.
UPD2 Всё же если есть нули в массиве, нужно сначала перебирать сколько умножений мы потратим на них, а потом уже перебирать i.
3683463
А можно ли в задаче D отвечать на запросы онлайн?
Точнее говоря, я знаю, что можно:), но хотел бы посмотреть код. Кто-нибудь писал такое решение?
Какова твоя идея? Единственное что придумалось персистентное дерево отрезков, но онлайн ли это.
Моя идея сжатое двумерное дерево отрезков http://e-maxx.ru/algo/segment_tree#27 , вот тут http://codeforces.net/blog/entry/7557#comment-132480 натолкнули меня на эту мысль, до этого я не думал о парах чисел в терминах точек. Всего у нас nlogn точек и нужно делать запросы в подпрямоугольнике — вроде в точности та задача, что описана на емаксе.
Можно деревом отрезков, которое в вершине хранит её отрезок.
Спрашиваем на соответствующем отрезке по первой координате сколько на нем второй координаты от l до r.
Вроде приятнее :)
UPD: по памяти не проходит, NlogN * log(NlogN) — много
UPD: допихал до 35 теста
Моему решению вроде хватило памяти, но ТЛ 23 188 мб
Почему В D/B не было теста против Флойда с запоминанием уже посещенных вершин? Код.
UPD. Хотя похоже, что придумать такой сложно
В Div-2 D проходит самый обычный Флойд без бинпоиска, форда-Беллмана и всяких запоминаний.
Да и Дейкстра такая же проходит. Самое сложное в этой задаче — правильно понять условие и ограничения.
И ДФС тоже проходит, чуть-чуть правда надо поменять смысл массива запоминания посещенных вершин.
А можете по-конкретнее про то, как надо изменить ДФС?
Пуст used массив, который used[v] == true если вершину v уже посещали. Нужно заменить его на int'овый и запоминать длину, с которой пришли в эту вершину. Далее заместо проверки !used[v], сделать проверку длины, если мы пришли в эту вершину с большим значением длины, значит пересчитать ее заново. Это так потому что с большим значением мы можем достигнуть больше вершин. 1 длины == 1 времени.
P.S. На самом деле тут не только ДФС нужен, но еще бин поиск.
Зачем здесь бин поиск? Такой ДФС заходит если пустить его с конца. Если на контесте, то хоть когда ты понимаешь, что не инициализировать переменные плохо.
Видимо Флойд заходит в силу специфики ограничений. Sereja, объясните, пожалуйста, почему ограничения именно такие?
Чтобы веса всех ребер при запуске Дейкстры были неотрицательны.
Да, но по авторскому решению не кажется, что просто поиск кратчайшего пути должен проходить.
Необходимо, чтобы не было отрицательных циклов. Иначе неправда, что кратчайший путь не будет пытаться проходить по одной вершине два раза.
Без этого ограничения задача как минимум не проще комивояжера с такой метрикой и врядли хорошо решается.
А как коммивояжера свести к этой задаче / доказать, что нельзя решить быстрее чем эту (если без ограничения)?
Расположим финиш на (+inf,+inf).
Остальные точки расположим в третьей четверти, с существенно большой по сравнению с расстоянием до них стоимостью в них. Тогда нам точно выгодно обойти их все, причем сделать это надо оптимальным маршрутом, и вернуться в начало.
Мне кажется, что в таком случае это просто задача поиска цикла отрицательного веса...
Минимального цикла отрицательного веса все-таки. Это меняет дело.
А на чем падает такое решение D(B):
Заметим, что если две вершины находятся на расстоянии друг от друга более чем 1, и мы хотим попасть в более близкую к нам вершину, то нам не выгодно идти из более удаленной вершины (от изначальной) до более близкой. (2*d > a[i] для любого i). А для вершин у которых разница 1, не важно как идти либо через более удаленную, либо просто прямо к ней, результат один и тот же.
Теперь пишем одномерную динамику расстояние до первой вершины. Пересчитываем состояние за O(n) пробегаясь по всем вершинам которые ближе к первой, и обновляя ответ(это можно делать в силу замечания).
Это свалилось на 53 тесте, это я криво написал решение, или есть идеалогическая ошибка?
Представь что надо идти из (0, 0) в (100, 0) а на Y=1 расположена куча станций. Тогда выгодней сделать крюк и пройтись по этой прямой.
Спасибо, действительно упало.
Will English tutorial public?
they need a translator
В Div-1 A проходит такое решение — N раз будем менять знак у N минимальных чисел и среди всех сумм выбираем наибольшую :)
Моим первым сабмитом было это. Только не n раз, а 1000. WA3
Блин, только сейчас осознал, что мое решение — неверное, а мой AC — жуткое везение :) Кто-нибудь умеет ломать мое решение?
Дело в том, что Ваше решение верно :)
На каждой итерации Вы меняете знак не у n минимальных чисел.
Пусть k — количество отрицательных чисел. Тогда после каждой итерации у вас остается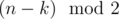 отрицательных числа, если k < n, и n - k иначе.
отрицательных числа, если k < n, и n - k иначе.
Кстати, отсюда следует, что достаточно лишь трех итераций, вместо n :)
Да, ладно. Я да же могу доказать что твое решение правильное...
Поскольку в Е мы добавляем все числа сразу парами (x, x+1) , то если сразу вычитать lastnumber из all, all всегда будет чётным => можно кушать меньше памяти, если хранить именно количество оставшихся пар.
No English tutorial for the round?
We really need a tutorial in English.
Sorry to say but I really dislike tutorials on Codeforces in general, as usual they are very short and all you can see is a brief idea. Is it too hard to write a full solution like people on topcoder do?
this tutorial is just about 'what we should write as code' !!! I think it's better to discuss about 'why'
Maybe this very tutorial is a bit hard to understand, but in general I like these brief tutorials. If these several words are not enough for somebody, it probably means that the given problem is too hard for them.
Reading TopCoder tutorial is like a lecture, you don't need to know anything to understand it. Here you have to put an effort to understand the solution. And writing longer tutorials is definitely harder and requires more time from the author. Who's gonna pay him? Codeforces don't make money like TopCoder does (AFAIK), so we must be happy with cheaper solutions.
Instead of minusing your opinion, I say the opposite thing.
I agree some of what you said. Sometimes the tutorials are fine, I mean in most cases they seem to be like this. I understand that you need more effort to write longer solutions but some authors do this effort (For example I can show you this: http://codeforces.net/blog/gojira). It will be nice if it will be improved. 3 line explanation for Div1 C (also considering that only a little amount of people solved it, compared to other rounds) seems to be very very far from enough.
Actually, authors of Codeforces contests do get paid well enough ;-)
Yes, that's amazing, because I see no evident source of money, except VK sponsorship. And sad from the other side, that if CF didn't have the money, we wouldn't have problemsets. It scares me a bit when I read about VK owner situation. But maybe this miracle is something special to Russia. I don't need to know all the details. Having CodeForces running makes me sufficiently happy :)
I will take the liberty to say that many authors prepare contests not for the money, but because it's interesting, fun and gives you a unique experience.
I am new to programming contests please someone can explain what we had to do in DiV1-problem B in proper english and why ? would be high. greatful :)
You could use Floyd–Warshall algorithm: http://codeforces.net/contest/301/submission/3695726
Because d>=ai,so we can't go through a station twice.So we can use an algorithm to find a shortest path.We can use "SPFA" "Dijkstra" or "Floyd". And I use "Floyd" because it is too easy
Could anyone explain Eretosphen algorithm ,which i cannot find on Google. Thanks
http://en.wikipedia.org/wiki/Sieve_of_Eratosthenes
Thanks.It's very useful
You don't need eratosthenes sieve actually.
there will be about O(log(n)) pairs (a, b)
for n = 200000 there will be about 2 * 10^6 pairs
UPD: O(N log N) pairs of course, thanks Zlobober
You meant O(N log N), I think.
It's quite interesting fact that number of pairs (a, b) such that a divides b has such asymptotic. I really love the way of proving it.
We can see that number of factors of 1 is integer part of N/1, number of factors of 2 is integer part of N/2, number of factors of 3 is integer part of N/3 and so on. Let's remove integer parts away (total sum will increase by no more than N) and take N off the brackets. We obtain N * (1/1 + 1/2 + 1/3 + ... + 1/N). Sum in the brackets is the prefix of the sum of harmonic series — it's well known that it's asymptotic is theta(log N). So we obtain the asymptotic for the original construction: O(N log N).
I know this is necroposting but someone either fix the English editorial or pin the above comment to the top somehow. Wasted a lot of time searching even research papers for Eretosphen algorithm. -_-
Does anyone want to boast with his implementation of the idea presented here of the problem "301A — Yaroslav and Sequence"?
Can someone explain Div1 A solution in a clearer way please?
Problem Div1 A, using dfs is overkill, an observation is if
nis odd, we can reach any states; and withnis even, we can reach any states with the number of flipped position is even. An O(n) solution can be obtained: http://codeforces.net/contest/301/submission/38010389Thus, for Div 1 A, the constraint of
ncould be up to 10^8.Hey Time limit per test needs to be updated to 2 secs for 302A — Eugeny and Array.
No, the limit is 1 second and my normal O(n+m) solution needs 156 ms. 49375836 I've checked your code and it gets accepted with the result 748 ms if you use fast input/output. Just put this at the beginning of the main function:
div1 B can be solved without using the binary search 57610787.
I ran your submission on Ideone with the input
and it gives -899 as the output. I think the answer to this case should be 100.
I think this is the case of weak test cases. You're only optimizing the total cost of the path. It could be the case that your player runs out of time while travelling between two stations.
Update: Sorry! The input is invalid since d should be greater than 1000. My bad!