


Author's Disclaimer: This is my first blog in a series of blogs I plan on writing that introduce various types of problems to beginner competitive programmers through providing new ideas and proposing questions about them. That being said, whenever I ask "why?" in parenthesis, this is not me asking because I don't know. This is me encouraging you to stop and think through why something I said is true. I don't want to just give answers, I want to provoke thought. This is how we learn. If you're stuck, feel free to ask in the comments. I am purposefully leaving implementations vague.
Basic Sum Queries (Prefix Sums)
Let's say we have some array $$$A$$$ = $$$A_{1}$$$, $$$A_{2}$$$, ..., $$$A_{n}$$$. Given two indices $$$i$$$ and $$$j$$$, we are tasked to find the following sum.
For those unfamiliar with the notation, this is simply $$$A_{i} + A_{i+1} + ... + A_{j}$$$. If you don't understand the notation, use this fact to try and deduce what it means. This is important, as I will not explain notation further later on!
We could do this by iterating over each element and adding it to a sum which is initially 0. The complexity of this is $$$O(n)$$$ (why?), which is too slow if we are processing a bunch of these queries.
Instead, we can generate some useful information about each index in $$$O(n)$$$ and then solve each query in $$$O(1)$$$. Let $$$dp_{i} = \sum\limits_{k=0}^{i} A_{k}$$$. Thus, $$$\sum\limits_{k=i}^{j} A_{k} = dp_{j} - dp_{i-1}$$$. Stop and think about why this is true (it is very important that you understand this). Also, think about why you need to watch the $$$i=0$$$ case!
These $$$dp$$$ values can be stored in another array (or you can change the original array if you're feeling edgy that day and the problem allows it).
Note: This is technically really simple dp, but I'm in a small minority by actually notating it this way. Most people put psums in a different category.
This is the cses problem that correlates with this skill: https://cses.fi/problemset/task/1646
Next, try using prefix sums to solve this: 466C - Number of Ways
Sum Queries with a BIT
Note: BITs are probably more confusing than segment trees, so if this looks terrifying don't be afraid to skip this section.
Let's say we have the same task but an extra challenge is added. A new type of query is introduced in which we must add some value to one of the elements in the array. If we were to keep using the prefix sum method, suddenly we would have to rebuild the $$$dp$$$ array each time this type of query is called upon (why?). This is where a binary indexed tree (also known as a Fenwick tree) comes in. This uses bit operations (more precisely, powers of 2) to solve both types of queries in $$$O(\log n)$$$.
The main idea behind easily implementing this is that the largest power of two that divides some integer $$$k$$$ is k&(-k) (why?). We'll notate the largest power of two that divides $$$k$$$ as $$$☺(k)$$$ (this is obviously not official notation, please don't use it elsewhere or people will laugh at you). We then build a new array (we'll call it $$$T$$$ for tree) such that $$$T_{k}$$$ contains the sum of all elements in the sub-array that is of length $$$☺(k)$$$ and ends at index k.
To compute $$$\sum\limits_{i=0}^{k} A_{k}$$$, let $$$j = k$$$. Then, while(j > 0){ sum += T[j]; j -= j&(-j); }. Think about how you could use this to find the sum of all values in a range that doesn't start at the first element (you just did this with prefix sums). As an exercise for the reader, try to think about how updating a value would work.
Both of these operations occur in $$$O(\log n)$$$ (why?).
This is a very confusing topic. Here is a diagram that may help (pulled from the cses handbook and edited for generalization purposes). This is also a good reminder to NOT make your BITs zero-based!
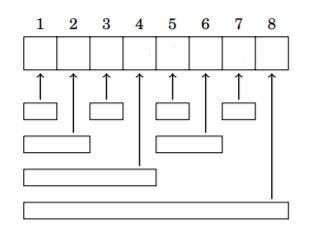
This is the cses problem that correlates with this skill: https://cses.fi/problemset/task/1648
Next, try to use a BIT to find the amount of inversions in an array. Don't be discouraged, this may be challenging! An inversion is a pair of indices $$$i < j$$$ such that $$$A_{i} > A{j}$$$.
Segment Trees (Iterative Implementation)
Firstly, I am only discussing the iterative implementation here. Many believe that the recursive version is easier to understand. If this interests you, I encourage you to learn the recursive implementation elsewhere. Keep reading, however, since this section should still explain what a segtree is regardless of how I code it.
Let's say the task is no longer to find the sum of all elements in a range, but rather the minimum, maximum, or some other attribute of the range that would normally require an $$$O(n)$$$ iteration. Segment trees can do these efficiently ($$$O(\log n)$$$) and are often easier to understand than BITs (which can only handle sum queries). Before I get into detail, here's a diagram (again, copied and modified from the cses handbook) that should give you a pretty good idea of what we're working with.
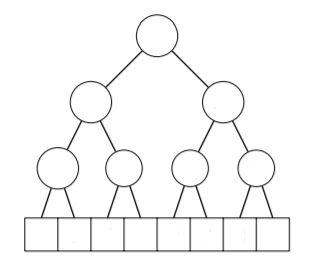
Let's say we're working with minimum range queries. In other words, what is the minimum value in the range $$$[a,b]$$$. We use the fact that each note in this diagram (the original array is the bottom row) is the minimum of the two nodes below it. We can actually store this segment tree in an array $$$T$$$ that is twice the size of the original array such that $$$T_{i} = min(T_{2i}, T_{2i+1})$$$. These, similarly to BITs, should NOT be zero based.
Let $$$n$$$ be the size of the original array and we want to find the minimum value in $$$[a,b]$$$. First, add $$$n$$$ to both $$$a$$$ and $$$b$$$ since the original array is actually stored in the second half of $$$T$$$, which is the data we will be working with. Then, we'll let res=INF where INF is some arbitrarily large value (infinity). Below is an iterative implementation of a minimum query with this segment tree we built.
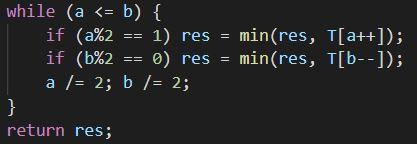
a /= 2; b /= 2; is simply moving up the tree (why?). Also, knowing that the modulus operations (a%2 and b%2) tell us whether a and b are right children or left children, consider why we only apply the operations in these certain conditions (refer back to the picture!).
I know this description is vague, but I am confident that anyone reading this, even if it takes a while, can think through why these things I'm saying are true. Trust me, it's very good for you!
You can edit values in the original array with a segment tree as well. Once you change the value at index $$$i$$$, divide $$$i$$$ by two and do this: while(i >= 1){ T[i] = min(T[2*i], T[2*i+1]); i /= 2; } (are you starting to see why this should NOT be zero-based?). The contents of this loop will vary depending on what your segment tree does.
Above I explained a segment tree build for minimum queries. Test your knowledge of this content with this cses problem: https://cses.fi/problemset/task/1649
Next, go back to the problem I gave you for the BIT and solve it with a segment tree instead: https://cses.fi/problemset/task/1648
Next, let's explore using a different operation: XOR. Solve this other cses problem (note that we don't need to update values in this one!): https://cses.fi/problemset/task/1650
Closing Thoughts
Firstly, thanks for reading this far. I was nervous writing a blog like this since it will most likely fall into one of two categories: too easy for the experienced or not enough detail for the learner. The reason I did this was to introduce a new kind of interactive learning. I encourage everyone who is trying to learn new topics to pick up as much as they can from their own intuition and exploration. I don't want to discourage people who can't figure some of this out. That's ok! I started with a harder topic for a reason. Please let me know what you guys think in the comments. What topics do you want to see next? Do you like this more interactive style of learning or would you prefer more answers than questions? Are there any mistakes I made?
Thanks for reading. Happy coding! -Jellyman







Iterative implementation is difficult for beginners. Recursive is easier. Difference in runtime for iterative and recursive isn't matter for $$$99\%$$$ problems. Recursive implementation is dynamic version of divide&conquer method.
UPD. You did not say about sqrt-decomposition. This is a data structure with easiest idea and it works only in two times slower than recursive segment tree. It can process single modification in $$$O(1)$$$.
Thanks for adding this here. I'm not sure if I'll add it to the blog since there's so much to go through already and the idea of what a segment tree is doesn't change with implementation but I'll add a note encouraging further research on it. To be 100% honest, I have never used the recursive impl myself. I don't want to teach something I'm uninformed about lol
Also regarding root decomp, I'm trying to keep this as an introduction. I don't want to overload people who can benefit optimally from just the very basics. This is a good point, however. Thanks for the feedback.
Is recursive really easier? I would say that iterative is easier and the only reason to learn recursive version is that later there's also lazy propagation. That being said, I might be biased because I learned the iterative version first as a kid.
The speed difference depends on $$$n$$$ and can be easily bigger than "twice slower". And single modification isn't $$$O(1)$$$ for most problems, including RMQ. But indeed sqrt-decomposition is related to segment trees and can/should be taught first, I guess.
"I would say that iterative is easier and the only reason to learn recursive version is that later there's also lazy propagation."
Even lazy propagation can be implemented iteratively.
In BIT, I think you mean k&(~(k-1)) instead of k&(~ k)
k & (-k)andk & (~(k-1))are both valid.Oh, Sorry, I interpreted -k with ~(k) .
ah I see. No worries lol
I'm actually glad you commented this because some people may not know the other way.
In addition to prefix sums, difference arrays can also be used to perform updates on intervals when we only need to print the result once all the updates are done. Every update takes O(1).
I've written about them here if you want to have a look:
An Introduction To Difference Arrays
loved it! It was awesome. I was new to this topic and it was kind of interactive learning. Iam able to code it by just reading the theory.