


Доброго времени суток)
Приглашаем вас на очередной раунд Codeforces #199 для участников Div. 2. Как обычно, участники Div. 1 могут поучаствовать в этом соревновании вне конкурса.
Задачи для вас готовили авторы Павел Холкин (HolkinPV) и Геральд Агапов (Gerald). Традиционно выражаем благодарность Михаилу Мирзаянову (MikeMirzayanov) за системы Codeforces и Polygon, а также Марии Беловой (Delinur), которая перевела условия задач.
UPD: Распределение баллов по задачам будет стандартным — 500-1000-1500-2000-2500.
Желаем всем участникам удачи, высокого рейтинга и удовольствия от решения задач)
UPD2: итак соревнование завершилось, надеемся вам понравилось)
Поздравляем победителей:
1) chixianglove
2) Logvinov_Leon
3) Yoshiap
4) _moonlight
UPD3: разбор задач можно найти здесь







Почему вы решили провести соревнование утром?
Наверное что бы не пересекаться с топкодером.
Thanks for the contest!
But Why is the name of Author orange(Master) on the title and purple(Candidate Master) in the text??
Here Master↓


---------------------------------------
---------------------------------------
and here candidate master↓
---------------------------------------
---------------------------------------
some copy-paste) fixed
You may want to warn everybody about unusual contest time :)
Good Morning (:|
А будут ли доступны тренировки параллельно с раундом?
Так будут или нет?
Да.
is this contest difficult? gonna to see the problems you prepared! and waiting for the score distribution now... hope everybody can enjoy this contest and get high rating!
Sorry to ask, but is this a rule that there will never be an intersection between CF & TC contests?
This looks like a good reason...
Good time for Chinese participants:)
But I'm sleepy... :(
+1
А-шка и Е-шка — 2 обидных фэйла за 1 контест :( Когда же я исправлюсь?
Еще и С-шка добавилась :(
most of the solutions in problem C is wrong. check it: 11 21
test: 8 7 answer: 3
Very easy pretests in each problem...
That's good for hacking ;-)
Вопрос по задаче C: почему идея: распихать по два шарика во всю высоту и один сверху, если h%r == 0, а иначе по два шарика в высоту прямоугольника + 2 не проходит? код:
См. ветку выше про 8 7.
Идея в том, что если запихать оставшиеся 2, то может остаться место на ещё один посередине.
Условие для одного сверху другое. Я пихал по два шарика пока влезает, и потом проверил, можно ли поместить еще 1 сверху.
Потому что стратегия "распихать по два шарика во всю высоту и один сверху, если h%r == 0" может быть выгодной не только в условиях h%r==0. Кроме того, если пихать "по два шарика в высоту прямоугольника + 2", нам может не хватить места, т.к. за высоту надо в таком случае брать h-r/2.
Шары снизу могут выпирать вверх ещё на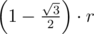 .
.
Can someone find the problem in following logic for A? There are only 3 possibilities: (1 2 4), (1 2 6) and (1 3 6). So I simply read the input find counts for numbers 1 to 7. Let say that combination 1 2 4 is there a times, 1 2 6 b times and last c times. From counts I can calculate a as number of 4s, c as number of 3s and b is number of 6s — c. At the end I calculated counts for used possibilities and checked against input, but got WA.
edit: it failed, because I didn't checked that b is non-negative :-/
b is the number of 6s — number of 3s
UPD: numer of 2s must be must be equal to 4s + (6s — 3s)
and while c is number of 3s it is the same...
I did the same and got AC. Maybe your checks wasn't comprehensive enought.
A is much simpler than that, the point is that only 1 can be set as the first number in every sequence 5 and 7 cant be in the sequence, you can pick 2 and 3 for the second number if you pick 3 you cant only chose 6 for the third and if you pick 2 you have 2 options, 4 or 6. so you simply check if there is any 5 or 7, and if the count of 2 and 3 equal the count of 1 and the count of 4 and 6, and...(if you want more pm me) good luck ;P
I got AC too.maybe you forget some conditions.The number of "1" equals to n/3; a==number of "4";a+b+c==n/3;and a>=0,b>=0,c>=0.
i dont get the point in C, some one help?
some helps with C? i dont really get it.
Consider example of r=8 and h=7. That's the case most solutions failed to answer correctly. You can put two spheres inside box and one more at the center of top semisphere.
pufff! how are we supposed to find that out?!
why down rates? not every one here know that much of geometry!
:D you down rate this as well?!! hahahaha i have 40 downrates already, i dont care!! cows rock!
Geometry is really basic in this task. I used only Pythagorean theorem.
That's why you should practice more problems. Following your logic, I can say any task that I didn't solve is bad because "how is anyone supposed to find that out?" even when the definition of "anyone" is not exactly everyone.
It's simple , but I didn't realize that particular case during the contest.
Imagine that you have 3 circles puted in that way: 2 down , 1 up. You have the distances between their centers equal to r. So you have an equilateral triangle.
Let's name the height of the triangle t. So we have : t^2 + (r/2)^2 = r^2. So t = sqrt(3)/2 * r.
Initially you put h/r*2 circles from bottom to top so you remain with h%r. Up there you will have 3 cases: the 2 ones that are obvious ( 1 or 2 circles ) and the one presented below ( with the condition: t < h%r ).
Sorry for poor English. Hope it helped you.
Simple picture: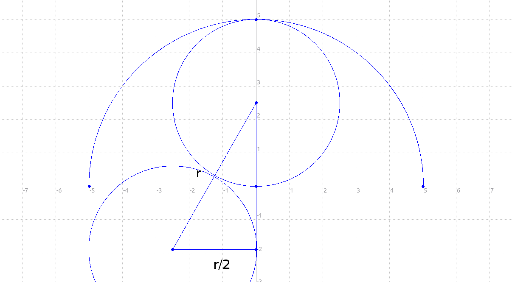
this simple picture is better than any tutorial. :)
I've always wanted to know how to generate/draw such pictures.Would you mind sharing the method with us?
I typed "Geometry" in Ubuntu Software Center. First result was "Kig".
GeoGebra (http://www.geogebra.org) is a nice tool as well.
i dont understand the condition t < h%r
See the remainder height $$$h\%r$$$ part and the semicircle part. Their total height is $$$r+(h\%r)$$$. Let's say we're able to fit 3 circles in the mentioned way, in this area. Now, the total height would be
radius of the upper circle+t+radius of the lower circles, that is, $$$(r/2)+t+(r/2) = r+t$$$.If you want the three circles to fit in the mentioned area, then their total height should be less than or equal to the height of the mentioned area. That is,
Как делать Е?
Sqrt декомпозиция по запросам. Обрабатываем их группами. В конце каждой группы запускаем бфс, который пересчитывает расстояния. В резутьтате мы учтём все вершины кроме добавленных в последней группе. Их не больше корня. Расстояния до них можна считать при помощи лца. Решение за N*sqrt(N)*log(N) можно избавиться от лог при помощи Тарьяна, но это не требовалось.
Ну можно sqrt-декомпозицией по запросам за O(N*lg(N)+sqrt(M)*(M+N)): Каждые sqrt(M) запросов пускаем БФС/ДФС и находим для каждой вершины ближайшую покрашенную, а в одном блоке нам просто нужно уметь находить расстояние между двумя вершинами в дереве, что делается с помощью LCA.
N*lg(N) у меня, потому что я что-то испугался LCA за lg(N) искать, поэтому Sparse Table построил.
не очень понятно как учитывать покраску вершин внутри запроса. Т.е. обрабатываем блок длина sqrt(M). В этом блоке есть запросы 1 и 2 типа. И как так 1 раз запустить dfs/bfs, чтобы учесть покраску?
BFS: Стартуешь не из одной какой-то вершины, а сразу из всех покрашенных. То есть красишь вершины из блока, затем все покрашенные закидываешь в очередь и ставишь им расстояние 0, ну а дальше как обычно.
но в момент, когда просили дать ответ для вершины "A", вершина "B" могла быть еще не покрашена. А если начать из всех покрашенных, то получается, что сначала все вершины покрасили, а потом уже отвечаем. видимо, я что-то не так понимаю. :)
А, понял вопрос.
Ну ты хранишь ещё не покрашенные вершины где-нибудь, и тогда ответ на запрос состоит из двух частей:
1) Смотрим ближайшую покрашенную до начала блока, это мы BFS'ом нашли.
2) Пытаемся улучшить ответ, учитывая что в блоке что-то покрасилось. Улучшить = найти расстояние между двумя вершинами в дереве.
Это то можно делать, если уметь находить LCA, тогда расстояние: (heights[u]-heights[lca])+(heights[v] — heights[lca])
понял, спасибо.
Ты хранишь все вершины покрашенные в этом блоке, проходишься по ним и улучшаешь ответ. Расстояние считаешь при помощи лца.
спасибо
Есть решение за O(N * log^2 N). (На контесте не зашло из-за тупого бага, в дорешку сдал). Идея: построим heavy-light декомпозицию. Для каждого пути построим дерево отрезков на максимум для величины 2 * h[v] — f[v](v — вершина, h[v] — расстояние от корня, f[v] — минимальная высота по всем красным вершинам — потомкам данной). Запрос на обновление — обновляем все на пути от вершины до корня. Ответ на запрос второго типа = h[v] — best, где best — наибольшая из величин 2 * h[v] — f[v] на пути от вершины до корня дерева.
Any ideas for solving E?
I have no idea whether there exists a nice solution which is both easy to code and fast enough. But as far as I can see now, you could use data structures like heavy-light decomposition or use brute force BFS/DFS with some tricky optimization ^_^
UPD: You could cut the whole tree into blocks of size sqrt(n) by choosing sqrt(n) key vertexs. For coloring, use BFS in its block and use LCA for each key vertex. And that'll be enough to deal with queries in O(sqrt(n)) each. So you get a O(nsqrt(n)) algorithm overall.
But your solution fails on this test :(
http://pastie.org/8305596
apparently I knew its algorithm using HLD, But I thought that this structure should not be given in atleast Div 2 round.
I am bit surprised when I saw the solution http://codeforces.net/contest/342/submission/4421565 which mentions that this is same problem as spoj http://www.spoj.com/problems/QTREE5/
Yes, I thought my program is quite likely to get a TLE in the system test.
Many accepted solutions are wrong(Only BFS/DFS)!I can easily hack them!--!
You can see my O(N*sqrt(N)) solution. The idea is to handle sets of 300s red nodes with BFS, and the rest with O(1) LCA. Not sure if it is considered "easy to code" though :D
I used centroid decomposition and reconstruct "centroid tree". This has O(log n) max-height and has all nodes of original tree. Every node of centroid tree has minimum distances to red node. Query Type 2, i can get minimum distance exploring nodes on the path from queried node to centroid tree's root. Query Type 1, update nodes on the path from queried node to centroid tree's root. Overall, using LCA, O(Qlog^2 N).
Very nice idea. Do you know any similar problems ? ( that use centroid in solution )
problems like dealing with distances on the tree. TMK, SPOJ/QTREEn series(as above), POJ 1987 and Croc Champ Round 2E[problem:293E].
Thank you !
Thank u! I know Qtree,poj and Croc Champ Round 2E,but what's TMK? Can you say it in details or give me a link? Thank U again!!
To My Knowledge :)
..ok.. I know it.. orz..
uwi Can you explain the approach to solve the same problem but to answer max queries(farthest distance to a red node) instead of min using centroid decomposition? Thanks.!
could you explain how you reconstruct "centroid tree" ??
А почему в В не проходит решение "в лоб"?
В лоб — это какое? Я действовал довольно глупо: всегда шёл в одну сторону, не делая ничего, если наблюдают за текущим шпионом или тем, кому надо передать записку. Такое решение проходит.
Вот и я так делал — WA 21. 4420514
Цикл на n+m поменяй и заходит твоё.
попробуй тест 100000 1 1 100000 1 1 2
Все, понял, спасибо.
проходит же
ты про какой лоб? там вроде все одинаково решали: надо идти вправо и ксения не смотрит ни на текущего ни на соседа справа — иди вправо, аналогично для лево, иначе стой.
http://codeforces.net/contest/342/submission/4425751
Проходит, если не ограничивать продолжительность моделирования числом M (или 4*M, как у Вас). В противном случае возможна ситуация, когда Ксюша уже не наблюдает, но мы все еще не пришли в конечную точку.
Да уж, надо было просто поставить мое любимое условие while(true). Ведь гарантировалось, что решение существует.
My code gave TLE with cin for T,L,R and gave Accepted in practise when I used scanf for the same.. :-/ Isnt it a bit harsh..??
what is you algorithm?
Just simple simulation..
This takes O(length), use Res+='X';
But the solution which passed actually just used scanf instead of cin.. Dont u think in an algorithmic contest it is better if such things which are language based should be avoided..??
Runtime with scanf = 1746 ms (your solution), I got Accepted in 404 ms using cin.
Runtime with scanf and += operator = 92 ms (your solution).
what's the complexity of
Res+='X';?It depends on the capacity of the string, if s.size()<s.capacity() then it's O(1).
http://ideone.com/p0UzsL
If you are appending n = 131043 characters, it's O(2n); string will change the capacity 17 times, sum of capacities = 257902, 257902 / 131043 = ~2
my silly mistake in B : could not realise that f could be smaller than s. so stuck with wrong answers on pretests even.
Когда обновится рейтинг?
Spent 2 hours only on problem D and finally got accepted...just 1 min before the contest ended.
I think the problems are harder than usual div.2 contests.
Мне одному кажется, что в B было весьма мутное условие?
Как по мне, то ни по условию, ни по примеру так и не было понятно, то ли шпионы передают записки в каждый целочисленный момент времени, то ли только на тех этапах, которые упомянуты во входных данных.
Ну не совсем уж мутное. Но да, за одно прочтение трудно врубиться.
i had advanced to Div-1 in the last contest, but i would still have liked to take part in this one unofficially. unfortunately missed it due to the unusual time and because Codeforces decided not to send a mail to its users! :/ please make sure this doesn't happen again! :)
You don't receive any notification about Div 2 only contests if you're Div 1.
There's virtual participation for that. I, for one, miss many contests, since I'm often in regions without solid internet connection, but I always participate virtually later.
Very weak pretests for task C.
The test data for task E is too weak. Many solutions only used brute force BFS which would fail on most tests where the tree's height is big ( e.g. form a string ).. but the system test didn't include any of these cases. What's more many O(n^2) brute force even ran faster than my O(n\log^2 n) solution, while some O(n\sqrt n) solution got TLE or MLE.. Just a remind to the task setter.. Don't just use complete random data when designing test cases.. Think about possible "strange optimization" for brute force and designing test cases against them is very necessary, since passing system test with brute force is unfair to the ones who wrote complicated correct solution and to those who didn't write brute force.
however, i think the test data of this problem is really hard to designed.
p.s. your solution may be improved to ? the usage of priority_queue is redundant.
? the usage of priority_queue is redundant.
I didn't use priority_queue.. I think if we solve it by the original heavy-light weight decompisition, it's hard to achieve time complexity better than n\log^2n.. Maybe this solution can be improved to O(n\log n) by Yang Zhe's 'global balanced binary tree' technique ( link: http://wenku.baidu.com/view/75906f160b4e767f5acfcedb.html ).. But I'm not sure..
It seems that task E can be solved by tree's divide and conquer algorithm in O(nlogn) instead of "the original heavy-light weight decompisition". I just solved it by which.
I read your code, it's really a nice solution. Thank you very much :)
sorry for my mistake. I hadn't seen your code yet. as Sunayuki pointer out, an O(qlogn) exists indead.
additionally, "global balance tree" isn't invented by Zhe Yang. some papers have been published before that.
It's not an exact true. Look at the 19th test. By the first several numbers you can guess its structure. There are a lot of tests with a huge hight of the tree.
The another thing is that some of bfs' use strange unexpected optimizations. Please, post your generators against such ones, if you see such solutions. We will add the tests to the testset. As ftiasch say, the test data of the problem is really hard to design. We've break a lot of solutions, but some of them passed. We are sorry for that.
this test would make the first several solutions with shortest code length fail.. ( i thought at first these solutions used some proof to ensure the time complexity but soon found out they are just brute force.. )
is it true that the problem-setter can perform hack during the contest?
if it is true, i guess the author should do it to prevent this kind of solutions from accepted.
Can someone please explain problem D 's solution to me ? I am not able to understand the solution from the editorial.
Thanks
can anyone explain more the idea of the problem E (other ideas than heavy light decomposition)