


Welcome to 2013-2014 CT S01E02: Extended 2003 ACM-ICPC East Central North America Regional Contest (ECNA 2003). The training duration is 5 hours. It is opened for teams as well as for individual participants. After the end you may use the practice mode to complete problem solving. Also it will be availible as a virtual contest for whose of you who can't take part today. Please, do not cheat. Only fair play!
It is possible that the problems will be too easy for some participants, it is possible that we will add some problems.
The registration is available on the Gym page and will be opened until the end of the training. Be careful registering team: please, choose only whose members who will take part in the contest.
Good luck!







PS: I'm sorry . I should post it after the contest. Sorry about that.
so , I just want to say , the problem J 's data maybe have problem . Beacuse of speaking too early , it's deleted.
Won't the solutions be public?
No, the solutions for any problem on Gym are public only when you solve the problem.
Oh ok. How do I learn the problems that I do not know then? I'll try to solve but I know I can't solve all of them.
I guess the point of Gym is that you train as if in a real contest environment (except there's no time limit).
Egor posted his solutions (codes) of 10 problems of the last training separately, because people were asking. Maybe someone could do it this time.
what was the logic for solving problem B?. My idea was to dp (i, lastPosition) lastPosition denotes position from the strings [1..m]. Now I iterate over all the characters and try taking creating new Possible valid transitions.
Complexity: l * m * 26 * log m. My solutions gets TLE??
OFFTOPIC: Could anybody tell me how to find number of test cases in the problems ??
If you store the strings by hash value, then you can solve it in I*26*log(m)
The idea is that since there are only some allowed strings that you can use, you start building the decoration using those strings. dp(i, j) — j the index of the last word used.
If the allowed words are ABC and BCD you start with ABC ( dp(0, 0) ) and then you can add BCD ( dp(1, 1) ), so the decoration will the ABCD.
You need to precalculate the available transitions and you get O(L * M^2), but the bound for M^2 is very loose (there will be much less transitions).
got accepted by your idea, Thank you very much mate :)
Test case 2 in problem J was evil. I could not figure it out during the contest. Only thing that I could figure out was that this test has longest string length = 0.
I got WA on test case 2 problem J during the contest and replaced cin by getline and got AC
Any idea for solving C? I tried some simiple generation idea which took around my 2-3 seconds on my system but it gave me TLE on the first test case :(
You can generate all numbers. To find the next number, factorize the current one, then you would need to take the minimum multiple of one of its prime numbers, which hasn't been used.
This was essentially my algorithm but it was running for 2-3 seconds on my PC and got TLE on the Codeforces. Can you please suggest some modification in my code. http://ideone.com/YqhwZV
You can keep only one prime divisor for each number.
Also you could use an array of next multiple and array of booleans indicating whether a number has been used. You can use the second one to keep the other updated. I think that is faster than using vector <set > st
I could not understand keeping only prime divisor part. I think by maintaining only one prime, we might miss some numbers because we have to satisfy the condition gcd (a, b) > 1.
What was the second test of problem J?
Many people got wrong answer on it and corrected their code, but I don't find the mistake!
I changed cin >> s on getline(cin,s);
I changed while (cin>>a && cin>>b) to while (getline(cin, a) && getline(cin, b)) and it gets WA on test 1 now!
Try this;
while(getline(cin,a)){
getline(cin,b);
My solution on previous edit. P.S. 'z' > 100. Change your array sizes.
at last got accepted! Thanks!;)
A strange thing happened to me on problem J.
When I read the input using a
while(scanf("%s %s",a,b) == 2)loop, I get WA. Same withwhile(cin >> a >> b. When I read usingwhile(gets(a) && gets(b)), I get AC. I've been using cin (on strings of letters) for a long time and I've never had any problems with it. What's different this time?Depressed from J, I decided to only solve problems that I feel like solving (unlike a real competition, where I go by estimated difficulty). So I did I and L. I even managed to get AC on L with an O(N3) dynamics, very close to the time limit (but I did an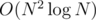 one later). It would've been fun to have a time limit 0.2s on L... I'm gonna put this to some Slovak training sometimes :D
one later). It would've been fun to have a time limit 0.2s on L... I'm gonna put this to some Slovak training sometimes :D
I think you had problems with empty strings. Was it possible under problem's limits?
I see. That explains all. But if an empty string is a valid "string of letters" here, then there is an infinite number of such strings on every line, thus contradicting the claim that there's such a string (one string) on every line of input, no?
This logic is strange. If you see empty lines of latin letters — could it be interpreted as one string? Yes. So, empty line is valid input for the problem.
Of course, you can interpret it as multiple strings, but 1) this contradicts to the problem statement 2) some way to separate strings from each other should have been given. So, such understanding of empty line doesn't seem to be correct.
Any hint for problem I? I saw that the sequence could be reconstructed, and was thinking about using DP to go through the sequence. The condition of being independent appeared in a recent round, but I couldn't find a way to express the condition of dominating in a recurrence.
It's quite easy, actually. First, you can just reconstruct the original permutation (this can be done in O(N2) easily). An independent set corresponds to an increasing subsequence S. If the set is dominating, it means that for every element not in S, there must be either a larger element before it or a smaller one after it, in S. Since S is increasing, it's sufficient to consider just the element of S just before it and another one just behind it (we can add ghostly -inf and +inf at the beginning and end of S).
The time limit is pretty loose, so we can check for every two elements A[i] and A[j] (i < j) of the permutation, whether they can be successive in S, by checking the necssary conditions A[i] < A[j] and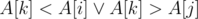 for all i < k < j. Also check for every A[i] if it can be the start of S (in the permutation before it are only larger elements) or end of S (after it are only smaller ones).
for all i < k < j. Also check for every A[i] if it can be the start of S (in the permutation before it are only larger elements) or end of S (after it are only smaller ones).
Now, we can do DP: let C[i] be the number of allowed S which end with element A[i]. Try all possible j > i and if A[j] can be right after A[i], increment C[j] by C[i]. Time complexity: O(N3).
There is also an O(N2) solution. The only step we need to optimize is checking valid intervals. But I leave this question open for you to think about...
In problem J , as it is not specified the number of test case , how do I know what no. of test cases we have to take. I am writing it in java and it is getting runtime error when i write this code if((string1 = reader.readLine()).isEmpty())break;
You should terminate when line is null. That's why you got a Runtime error (NullPointerException, I would guess).
I did it using BufferedReader in.
String line = in.readLine();
while(line != null){
//do stuff
line = in.readLine();
}
Old contests are always full of bugs, especially in tests...
i think there is no point of preparation if there are no editorials ,because for teams that are not very good they cannot improve without proper explanations of the problems,I think if editorials are added then this type of contests would be really helpful,or else the are for teams that are already very good
Well, in fact, nobody forbids you from searching for the judges solutions for the problems. They are publicly available.
And you should remember that it's much easier to explain the problems orally [to Saratov teams] than to make a written editorial. This is a sufficient reason for not writing one.
I am not asking for editorial but feeling sad for not being in a saratov team. :P
I saw many people and teams got WA 1 on H (This Takes the Cake). What was the problem with this test case? It wasn't sample from statement?
I had a problem with output. I hadn't read the problem carefully, so hadn't noticed that the word in the output is "Cake" not "Case". Maybe someone else had this bug.
The problem B. I can't understand why the answer to test, where L is less than the lengths of combinations, is 0. I think it's n^L. Cause all combinations in every string with length L (there are zero of them) are contained in given set of combination. I didn't forget about this case the first time I sent my solution (later i tried to understand what authors could think and got AC). And I still don't understand why it's wrong. Tell me please where I read the problem wrong.
I think so, too. But as that's heavily based on the problemsetter's view, it's best to ask about that kinda stuff.
My practice submission for problem L fails on test case 22. I guess that this might be due to long long overflow. For the case n=1000 and p(i)=i, the answer according to Wikipedia should be about 2.4*10^31.
Can anyone who has got this problem accepted confirm that big integers are indeed required to get AC? Thanks.
Finally got AC after defining a bigint struct. O(n^2*(log n)).
If someone has O(n^2), please share the idea. Cheers.
I put in comments after trying to understand my friend's solution. You should be able to see it since you have solved the problem :) If the comments are not clear enough... I can give more examples.
http://codeforces.net/gym/100228/submission/4534527
Yeah, big integers are necessary. I got AC on one submission with O(N3) and bigints, though. The trick I used is that a bigint is just represented as two 64-bit variables (as 2 digits for a base around 1017), which is faster than representations by digits etc.