


Разбор задач Codeforces Round #204
352A - Джефф и цифры
Рассмотрим решение как разбор случаев:
1. Если у нас нету нулей, то ответ -1.
2. Если у нас меньше чем 9 пятерок, то ответ 0.
3. Иначе ответ имеет вид:
4. 1. максимальное количество пятерок, кратное 9
4. 2. все нули, что у нас есть
352B - Джефф и периоды
Будем идти по массиву слева направо. На каждом шаге будем хранить массивы:
1. nextx — последнее вхождение числа x
2. periodx — период, с которым встречается x
3. failx — был ли момент, когда число x перестало подходить
Теперь когда мы получаем число рассматриваем случай, когда оно первое, второе или встречалось больше чем два раза.
Все случаи описаны в любом прошедшем системное тестирование решении.
351A - Джефф и округления
Изначально запомним количество целых чисел — C. Далее округлим все числа вниз, и посчитаем сумму. Теперь мы можем изменить сумму, округлив некоторые числа вверх, при чем не важно какие именно, главное — сколько. Рассмотрим пары, которые могли получится (описанные в условии, первая компонента — число, округленное вниз, вторая — число, округленное вверх):
1. (int, int) (c1)
2. (int, double) (c2)
3. (double, int) (c3)
4. (double, double) (c4)
Переберем количество пар первого типа c1. Тогда мы знаем суммарное количество вторых и третьих типов и количество четвертого типа:
1. c2 + c3 = C - 2c1
2. c4 = N-(c1 + c2 + c3).
Проверим, можно ли получить такие числа (хватит ли нам целых и действительных чисел соответственно). Получим, что мы можем округлить вверх от c4 до c4 + c2 + c3 чисел. Найдем среди них самое подходящее и обновим ответ.
351B - Джефф и Фурик
Заметим что после каждого шага количество инверсий в перестановке изменится на 1. Перейдем от перестановки к инверсиям — пусть их будет I штук. Понятно, что когда у нас одна инверсия, то ответ — 1. Теперь поймем, как это использовать дальше:
1. понятно, что после хода Джеффа инверсий станет на 1 меньше
2. понятно, что после хода Фурика инверсий станет на 1 меньше с вероятностью 0, 5, и на 1 больше с вероятностью 0, 5.
3. имеем формулу для ответа ansI = 1 + 1 + ansI — 1 — 1 × 0.5 + ansI — 1 + 1 × 0.5
4. после преобразования получим ansI = 4 + ansI — 2.
351C - Джефф и скобки
Как решить задачу для маленького NM? Просто использовать динамику dpi, j — минимальная стоимость построить i первых скобок с балансом j. Переходы просты:
1. dpi, j + ai + 1 -> dpi + 1, j + 1
2. dpi, j + bi + 1 -> dpi + 1, j - 1
3. переходы делаем только, если результирующий баланс не отрицателен
4. стартовые значения dp0, 0 = 0
В данной задаче можем считать, что баланс никогда не превысит 2N. Доказательство этого факта оставим как домашнее задание. А использую этот факт задачу можно решить возводя матрицу в степень:
1. пусть Ti, j — цена перехода от баланса i к балансу j с помощью N скобок
2. (TM)0, 0 — ответ на задачу
351D - Джефф и удаление периодов
После первого запроса мы можем отсортировать числа и в за дальнейшие ходы сможем удалять все вхождения некоторого числа. Таким образом ответ это количество различных чисел + 1, если не найдется числа, вхождения которого образовывают арифметическую прогрессию.
Количество различных чисел на под отрезке в оффлайне — стандартная задача, описанная на многих ресурсах, решается за O(N1.5).
Задачу про поиск нужного элемента будем решать аналогичным способом:
1. отсортируем запросы как пары (li / 300, ri), деление целочисленное
2. научимся переходить от отрезка (l, r) к (l - 1, r), (l + 1, r), (l, r - 1), (l, r + 1) за O(1)
3. с помощью таких операция будем переходить от одного отрезка к следующему, в сумме операция выйдет O(N1.5)
Осталось научится делать изменение отрезка на 1 элемент. Такую задачу решать достаточно просто:
1. заведем deque для всех значений чисел
2. в зависимости от изменения отрезка будем добавлять/удалять элемент в начало/конец соответственного deque
3. проверим, является ли полученный deque арифметической прогрессией. это останется домашним заданием
351E - Джефф и перестановка
Сделаем нулевой шаг, заменим элементы на их модули.
Первое, нужно понять каким способом мы будем строить наш ответ. После подбора нескольких способов поймем факт, что изначально нужно определять знак у больших чисел.
Рассмотрим случай, когда на текущем шаге у нас только один максимальный элемент. Понятно, что если поставить знак -, то все элементы слева от текущего будут образовывать инверсии, а справа нет. Если же мы не будем ставить знак -, то все будет наоборот. Выберем лучший вариант и вычеркнем число из массива, больше оно не будет влиять на инверсии.
Теперь поймем, как считать ответ, когда максимумов больше одного. Напишем динамику dp[i][j] — сколько можно получить инверсий, когда мы рассмотрели первых i максимумов и j из них оставили положительными. Из такой динамики не сложно сделать переходы и получить ответ.
И так имеем простой и короткий алгоритм:
1. делаем итерации пока массив не пуст
2. найдем все максимальные элементы
3. с помощью динамики определим знаки, которые нужно поставить элементам
4. удалим элементы из массива







Еще более простой и короткий алгоритм к Е.
Заменим элементы на модули. Далее будем рассматривать элементы массива слева направо. Для каждого элемента считаем, как изменится число инверсий, если сделать его отрицательным, и если это число не увеличится — сделаем этот элемент отрицательным. Иначе оставим его положительным.
Что зашло у меня: В цикле (пока массив меняется), пытаемся изменить знак очередного числа(идем слева на право) на обратный, при условии, что число инверсий уменьшиться. http://codeforces.net/contest/351/submission/4660777
Кто как решал A (Div2 C)?
UPD: Опубликовали, спасибо, но все равно непонятно. Нельзя ли поформальней? Что значит "пара (int, double)"?
Как решал я. во-первых нам не важна целая часть числа, работаем только с дробной частью, пусть это b[i]. а теперь посмотрим как может число при округлении изменить сумму. 3 варианта: 1) число целое — сумма не меняется 2) число не целое а) округляем вниз сумма меняется на (-b[i]) б) округляем вверх сумма меняется на (1-b[i]) Таким образом сумма меняется на p-(b[1]+b[2]+...+b[2*n]), p — количество нецелых чисел округленных вверх. Нужно подобрать такое p, чтобы минимзировать модуль данной разницы, учитывая, что p<=n, p>=0, p+k0>=n, k0-количество целых чисел. 4673093
Можно так: отбросим целые части (они не меняются) и будем рассматривать массив дробей a1, a2, ..., a2n. Из этих 2n чисел мы должны n округлить вниз до 0 и n — вверх до 1. Посмотрим на разность оригинального и конечного массивов. Если мы число ai округляем вниз, то к разности прибавляется ai. Если мы ai округляем вверх, то от разности отнимается 1 - ai. Поэтому общая разность будет
где $k_1, k_2, \ldots, k_{2n}$ — какая-то перестановка чисел 1, 2, ..., 2n. Это можно упростить до
Теперь остаётся один особый случай, когда $a_i = 0$. Округляя его вверх, мы всё равно получим изменение разности 0, а не - (1 - ai). То есть, от ответа отнимается на одну единицу меньше. Пусть количество нулевых ai есть z. Какое количество q ненулевых ai будет округлено вверх (то есть, сколько единиц надо отнять от результата)? Не меньше max(0, n - z) и не больше min(n, 2n - z). Переберём все возможные q и выберем такое значение, что величина
минимальна. Это и будет ответ.
Я, наверное, медленный, но мне вообще не очевидно, что в div1C достаточно баланса O(N). Можно чуть поподробнее?
Пусть мы имеем баланс >= N, тогда можно поюзать уменьшение(мы его когда-то поюзаем). То есть максимум, что необходимо получать это (n — 1) + n
Казалось бы, честно поюзать уменьшение мы можем только текущим типом скобок (иначе цена поменяется). А что, если все оставшиеся скобки такого типа открывающие?
Не очень понял вопроса. Попробую объяснить сначала.
Будет работать только блоками по n. Ясно, что с точки зрения неизменности цены блоки между собой можно переставлять местами(все зависит только от позиции в блоке).
Ну теперь пусть после какого-то блока баланс >=n переставим оставшиеся блоки так, чтобы прямо сейчас шло уменьшение (например подвинем ближайшее уменьшение ближе к началу). Это ничему не помешает, т.к за раз мы уменьшаем не более чем на n. Значит если мы сейчас увеличваем можно считать что баланс был <= n — 1, а значит и получился он не более 2 * n — 1
Примерно понял. Спасибо.
Разобъем всю строку на подстроки длины n. Каждая такая подстрока изменяет баланс максимум на n. Пусть мы уже построили оптимальный ответ. Пусть некоторая подстрока делает баланс больше 2n (назовем ее А), тогда существует подстрока, которая находится дальше и уменьшает баланс — поставим ее сразу перед А. Если подстрока А все еще делает баланс больше 2n, то сделаем опять тоже самое, и.т.д. Поскольку в конце баланс равен нулю, то мы всегда можем найти подстроку, которая уменьшает баланс. Ну и у нас не будет проблем с тем, что баланс может стать меньше 0, т.е. условие (после А баланс больше 2n) предполагает, что перед А баланс >= n.
Круто. Спасибо.
Please explain "351C — Jeff and Brackets" in more detail. Thanks!
First note that there is always an optimal bracket sequence such that none of its prefixes has a balance larger than 2N (there's a proof sketch somewhere below).
Now make a (2N+1)*(2N+1) matrix. In cell (i, j) write the cost of the optimal n-block that changes the total balance from i to j, such that at no point it goes below 0 or above 2N (this second thing is not necessary actually).
Now we raise this matrix to the m-th power in Max-Plus algebra. This is basically an algebra where you replace addition with max and multiplication with addition. So when you do matrix "multiplication", the inner assignment is C[i][j] = max(C[i][j], A[i][k] + B[k][j]), and you initialize C[i][j] to some large number ("infinity") beforehand. The interpretation of this is pretty straightforward. Let A and B represent the optimal costs of moving from some i to some j total balance using a and b n-blocks, respectively. Then C will represent the same thing using (a+b) n-blocks.
See my code in the practice room for details, or ask for clarifications if I messed something up in my explanation :)
Hi,
Thanks for the reply :)
It took me a while to understand the matrix exponentiation part. It is a very neat method. Can you provide some literature for this? Theory or other problems?
Thanks. PS: You meant min() in the expression for C[i][j].
[removed]
В задаче C (div 2), меня жестко сбил формат строго 3 знака после точки. Зачем он??? Я долго искал какой-нибудь бин поиск)) а потом еще и не правильно вывел ответ из-за чего завалил задачу на контесте((
Ясно, что для целых задача была бы не интересна. А ровно сколько-то знаков очень удобно. Это позволяет просто работать в целых без проблем с парсом.
Can anyone share idea how to solve C(div. 1) without matrix multiplication?
I used doubling algorithm to do this problem.
A bracket sequence can be simplify to the form like
)))(((( = [')' * x + '(' * y]
So we can let f[k][i][j] denote, when we build (2^k * n) brackets, and they will simplify to [')' * i + '(' * j], we can assume that the balance will never exceed N(like sereja's solution).
We can get f[0] by iterator all possible bracket sequencen, and f[k] by merge two f[k — 1] when k > 0.Assume m = 2 ^ k1 + 2 ^ k2 + .. + 2 ^ kx, we just need to merge f[k1]~f[kx] to get the answer f[...][0][0].
I've got it. Thanks)
Can someone explain Jeff and rounding in more details ??
i see there are greedy solutions solving the problem, and also appreciated based on time complexity, but this is a straightforward dp solution which fits in the given constraints pretty well.
considering dp[n][f], where array[n] : n'th element of given array[], f : number of elements rounded down so far. integer portions of the input array elements are unnecessary, as they remain same in output sequence of rounded numbers. recursion is halted when n>2N [end of array] or f>N [more than N numbers are rounded down already]. notice that, we need N numbers to round down and the rest N to round up, so f needs to be N exactly.
then while processing dp(n,f), we can either round down the n'th number or otherwise. we attempt both of them and take the minimum based on their absolute difference of course.
My code goes here, http://codeforces.net/contest/351/submission/4674608
Any proof/explanation why absolute difference value can be found by this kind of recursion? I thought the recursion is only applied on searching max/min value. That's why I got stuck on this problem, I thought I needed another state (dp[index][rounded down value][the difference target]).
let's assume, input array is A, array to be made after rounding is B.
in this problem i have considered that the summation of the A array elements is always greater than the summation of the B array elements. so rounding-UP can only decrease the difference, hence deducted.
now from any state you need to calculate the minimum absolute difference to finish the job. recursion returns signed values, positive means input array has greater sum, and negative means otherwise.
notice, the ultimate difference is the summation of all the little differences we made on the way, i.e, increasing sum if a number is rounded down, and decreasing sum if a number is rounded up
now we need to minimize the "absolute" difference, not the signed differences, so we compare by the absolute value, and return the signed value, as we need to make a simple summation of the little differences for each array entry to find the output.
i tried to explain as simply as possible, apologies if it still seems confusing.
I am still confusing about the DP mythod. For example, the input data is as follows 3 0.000 0.200 0.600 0.600 0.200 0.000
Then when considering about dp[5][3], if the 5'th number rounding down, then the minimum abosolute value can get from dp[4][2]+(0.2). Right?
But dp[4][2] should be 0.4, but actually we can also rounding down 1'th and 2'th number to get -0.6, and |-0.6+(0.2)| < |0.4+(0.2)| . So we cannot get the right answer from the optimal subproblem, which is not like DP... we get the right answer for dp[5][3] is from the condition when the 5'th number is rounding up.
if you start recursion at (1,0) and head towards (2N,N), dp(n,f) means, you're processing the n'th element while f of the previous (n-1) elements are already rounded down. if dp(5,3) is called from dp(4,2), then it means 4th element was the 3rd number from the beginning which was rounded down, 5th element is yet to be processed . likewise, recursion is halted when n>2N, which is after processing of the 2N'th element in rec(2N,something).
very nice explanation, thank you :)
+1 for Rev.1! :) Very nice explanation indeed..;) Monmoy
thanks, i like the top-down aproach, is more easy to understand dp states and transitions
You can try some simple inputs and use different ways to choose which numbers are rounded up and which are rounded down. You will find that if the options we take on integers don't change, the result will be the same. Assume that we round down as many integers as possible, then simply calculate the result. Then if we reduce the number of integers rounded up by 1, the result will incrrease by 1. (Note:Here the result is signed, that means if the sum of new numbers is less than the original sum, the result is negative). If you notice these two points, finding the best answer will be very easy. Also the proof is simple too. So we just iterate on the number of integers we take rounded down, and in each step increase the result by 1, and update the best answer, until there aren't any integers are rounded down, or all round up numbers are integers. So in the program we just need to count the number of integers and calculate the initial answer(that can be done by sorting the numbers with the fractional parts), then the following work is easy. You can check my solution 4664512 for details.
Yours is the only method amongst others that I can understand and prove.
http://codeforces.net/blog/entry/9070?locale=en#comment-147569
i think this is a easy one for me to understand http://codeforces.net/contest/351/submission/4677352
Took me a while to understand the Greedy Approach. Lets say the input array is A[2n]. In this array, we have to ceil n numbers and floor n numbers. We modify the input array to store only the decimal portion of the numbers. The decimal portion of the numbers also represents the amount needed to Floor the Number. We take the sum of all numbers in A as S.
If the amount to floor a number is x, then the amount to ceil the same number is (1-x).
From the given array, if we choose two indexes i & j, where we choose to floor index i and ceil index j, then the total deviation from the S due to the rounding off of the given pair would be :
Amount required to Ceil index j - Amount required to floor index i= (1-A[j]) - A[i], where A[i] and A[j] is the amount required to floor the number at index i & j respectively.Now
(1-A[j]) - A[i] = 1 - A[j] - A[i] = (1-A[i]) - A[j]Which implies that it doesnt matter which number you choose to ceil or floor in the given pair.Now the TOTAL deviation from S due to all such pairs would be given by :
where (j_1, i_1), (j_2, i_2), ....., (j_n, i_n) are the indexes that form a pair.
The answer would have been this, but since some numbers in the array can be integers to begin with, the amount required to round them off (whether ceil or floor) is equal to 0. But in the above equation we have ceiled some of these numbers and added '1' to the total. Hence run a loop :
We are running the loop till Min( Count(Integers in A),n ) , since we can ceil at max n numbers.
4679640
A more simpler approach (for me) but O(N*2001) was to use DP. DP(i,j) = the minimum deviation from S by using the first i numbers in A and ceiling exactly j of those numbers.
The recurrence relation would be :
The final answer would be in DP(2n,n) since we need the minimum deviation by using the entire array of size 2n and ceiling exactly n numbers.
4675561
Thank you, this was a fantastic explanation.
For 351A — Jeff and Rounding, my solution is: First, we count the integer numbers, and suppose all the real numbers round up. Then, we count the total difference. For not integer numbers, we change it to round down, the total difference will down by 1. So, we just need to enumerate the number of real numbers which should round down, and find the best solution.
Можете пожалуйста сказать, почему это решение к задаче Div1 A неправильное?
Или лучше дать тест, на котором оно провалится.
Посылка: 4677131
Размер массива должен быть в 2 раза больше, т.к. n <= 2000, а размер входных данных = 2*n
ОЙ, ёёёёё. Блин, из-за такой невнимательности завалить задачу, а вследствие этого и контест...
Спасибо, буду больше обращать внимание.
I think your "352A" are wrong. Eighteen fives are not divisible by 9.https://www.google.co.th/search?q=555555555555555555%2F9&oq=555555555555555555%2F9&aqs=chrome.0.69i59l2j0.7908j0&sourceid=chrome&ie=UTF-8
Next time use a better tool before making such a claim: https://www.wolframalpha.com/input/?i=555555555555555555%2F9
A number is divisible by 9 iff the sum of its digits is divisible by 9, and 18·5 is divisible by 9.
Could you please explain me why all 0 are placed after digit 5?
Because we have to choose the largest such number. For a number to divisible by 9, its sum has to be divisible by 9. Thus, the largest such number divisible by 90 would be having all 5s in the higher ordered digits. Eg 505 is smaller than 550 while both have same sum of digits.
Can someone please explain the correlation between problem Jeff And Rounding with 2SAT and flows. I found the problem tagged with these.
Okay the tags have now been updated and I look like a fool. :P
Не разбор, а сплошные домашние задания.
Но контест вышел, на мой взгляд, лучше, чем обычно :)
Ну всего то 2 задания :)
Спасибо.
Sorry, but can someone tell me, what's wrong with my code for Div.2 C? I read a lot of different submission and solutions and found out thet my idea was true! But i can't find my mistake:( Thank you! My code here:4670052 Maybe something is wrong with K or with double numbers, but i don't think so... Please, help me!
Please explain why balance never exceed N — div1 C. I tried to understand that with Pigeon hole principle but failed..
I'll prove that there is always an optimal (i.e. cheapest) bracket sequence where the prefix balance never exceeds 2N. This differs from what you said only slightly in that it is possible that a prefix balance exceeds 2N in many optimal solutions (I know you're probably aware of this, just trying to be precise), and also that I'm using 2N instead of N (2N is what is suggested by the editorial).
Anyway, this is the proof. Take any optimal bracket sequence. If no prefix balance is above 2N, then we are done. Otherwise, find the leftmost n-block inside which the prefix balance exceeds 2N (let's call this n-block block X). At the end of this block, the current balance is surely larger than N, so that must mean that there are some n-blocks to the right that have a negative total balance (because we must end on balance 0).
On the other hand, just before block X the prefix balance is strictly larger than N (block X could only have added N). That means that we can safely add any n-block from the right with a negative balance (because even if its balance is -N, the prefix balance will still not go negative). Now, the prefix balance inside X decreases, but it still might be larger than 2N (also note that it is surely >0 because it was >N before the move). If it is, you repeat the procedure (all the preconditions are the same as just before we made this one move).
You can repeat this until the claim is met.
Now, it might be possible to adjust this to just N, but proving that doesn't seem as easy if it is even true to begin with.
Edit: I forgot to address the issue that when you decrease this prefix balance, somewhere in the optimal solution you might get a negative prefix balance (i.e. an invalid sequence). You can fix this in a very similar manner.
maybe I don't understand the problem statement... could someone tell me what's wrong with this:
N=1, M=6 and consider the sequence "((()))"
so at the third position, i.e. "(((", the balance is 3 > 2*1 = 2*N
The point is that your example is allowed, but it is never necessary to go above 2N. For example if N=1 then "()()()" is identical to "((()))".
Basically the imbalance of a string of length N is at maximum N. If you have one of the substrings of length N taking the imbalance above 2N, you could equally put that after a later substring that decreases the imbalance, and the result would be the same.
Key point of your proof is, when 2n exceed-balance occurs, get the right position of n-unit blocks then add some n-unit blocks to decrease balance. I hope I got your idea correctly. But it is difficult to me to understand some detail parts.
In paragraph 2, I cannot get the exact position of block X. Would you mind if you explain it with a simple example?
In your idea, to decrease the exceeded balance, we have to add some n-unit blocks. I think in that way, the length of optimal solution becomes longer and longer. Does that point have any problems at all?
Say N=3 and M=6 and this is one optimal solution (I will use + to denote the left brace, and — to denote the right brace)
+++ +++ ++- --+ — --- 1 2 3 4 5 6
Under the n-blocks I wrote their number. So, block X is the leftmost n-block where the prefix balance exceeds 2N=6. In this case, that will be block 3.
Now, for your question 2, perhaps I didn't write that as clearly, but you never add any new n-blocks or change them. You just reorder them.
So here, you would take block 4 and put it before block X
+++ +++ --+ ++- — --- 1 2 4 3 5 6
Now that we've done that, we can see that the highest prefix balance inside block X decreased (it was 8 before, now it is 7) but it is still higher than 2N, so we repeat the procedure.
+++ +++ --+ — ++- --- 1 2 4 5 3 6
And now we're done.
Btw, I'm not entirely sure how to fix the problem that somewhere on the right your prefix balance might become negative (what I wrote in the edit). I think you should always pick the leftmost negative n-block to the right of block X when fixing block X, and that ensures that any remaining negative n-blocks to the right will be correct (because their whole prefix is the same, just reshuffled). However, there is a sequence of non-negative n-blocks between block X (after it has been fixed) and that first negative n-block (if any), and some of these non-negative n-blocks could contain negative prefixes which might get the whole prefix balance negative which is a problem. In the few minute I've been now thinking about this problem, I haven't been able to figure it out so hopefully someone else can or can show that this "proof" is in fact invalid and provide a correct one :)
Meh, I'm sorry, I just can't format this, the editor is pretty bad :(
Oh, you mean "reordering", not "add". I understood wrong about that. So much thanks for the example that I can get your idea clearly. Of course either I cannot sure about negative balance problem what you worry about, but it is hard to come up with counter-example of your proof for me.. It seems that it is always possible to reorder the n-unit sequence without occurring negative balance.. Anyway so much thanks for your help. Thanks very much.
Actually, I think I've found a proof (sketch) for N that is fairly simple, except some hairiness at the end. Here it is, please let me know if it's wrong :) (my code that uses it is here 4708757, it passes systests but that obviously doesn't mean it's right :)
Theorem: There is always an optimal sequence such that no prefix balance exceeds N.
Definition: We call an N-block positive if it has strictly more than N div 2 opening braces. We call an N-block negative if it has strictly more than N div 2 closing braces.
Now, let's take any optimal sequence. Let's call the first N-block in which the prefix balance exceeds N block X (as before).
Lemma 1: There must be at least one positive N-block to the left of block X. Proof of Lemma 1: Block X can't be the first block in the sequence because then the largest prefix balance could only be N. Furthermore, before block X, the prefix balance must be at least 1. Therefore, we must have had at least one positive N-block.
Lemma 2: There must be at least one negative N-block to the right of block X. Proof of Lemma 2: Block X can't be the last block because at its end, the balance will be at least 2 [the case where N is the balance at the start of block X, then X is ())))...))]. Furthermore, the balance after block X must be strictly positive so we must have at least one negative N-block to get to balance 0 at the end.
Proof of Theorem: Due to Lemmas 1 and 2, we can find at least one positive N-block to the left of block X and at least one negative N-block to the right of block X. Let's call them A (positive) and B (negative). Now, by the definitions of positive and negative N-blocks, in at least one of the N positions, A has an opening brace and B has a closing brace. Therefore, we can reduce the prefix balance inside block X by one by swapping these two braces in blocks A and B.
Now, there's again the problem that bothered me in the other "proof", i.e. when we do that, some prefix that had balance 0 before we made this change now might have balance -1. I have an idea how to fix that that I think will work but it's pretty complicated and I can't really write it all down. The rough idea is to pick A and B as close as possible to block X. Furthermore, you can do some swaps very similar to what I described so that all the blocks between A and X and between X and B are balance neutral (i.e. their total balance is 0). Then you pick the leftmost of these balance neutral blocks (i.e. that one closest to A) instead of B and make the swap between it and A (you can still do it because A has strictly more than (N div 2) opening braces and the balance neutral block has exactly (N div 2) closing braces so they must overlap in at least one position).
Btw, I think the other proof can easily be made to work for 3N (which is plenty sufficient for this problem). When you fix block X, the balance after X will still be larger than N. Therefore, the 0-balance N-blocks that remain after X will not be able to make the prefix balance negative because their "negative peaks" can only be -(N div 2) "high".
When you swap an opening brace with a closing brace,the answer of the sequence will change(that is to say,the new sequence is not optimal).Unless the index of the opening brace has the same remainder with the closing one`s.
But when you exchange two blocks, the answer will not change.
I have studied your proof for hours.But I think both of them are not completely right,as you said above.And this problem confuses me.
If you have any idea,please share with me,thank you :)
ps:forgive my poor english
In this "second proof", you always swap an opening and a closing brace that are at the same position within an N-block (i.e. their positions in the sequence are the same modulo N), so the cost of the sequence never changes.
I'm pretty sure the "first proof" is correct for a bound of 3N, and the "second proof" can be made to work for a bound of 2N.
In "second proof", how can you prove that we can find two braces with their index have same modulo N?
It's in the paragraph that starts with "Proof of Theorem". Basically, you can find a block that has open braces on more than half of the N slots and one block that has closed braces on more than half of the N slots. Therefore, at at least one slot, one has an opening brace and the other a closing brace.
I`ve got it. Thank you :)
I solved Div.1 C during the competition using the algorithm below:
4686935 is the solution which uses the above algorithm. The time complexity is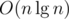 .
.
I made this by observation, not proof. How can I prove this algorithm is correct?
could you provide more details :)
Take a look at 3D - Least Cost Bracket Sequence.
.o. i have figured something while thinking about your equation. let's take always by block of size 2*n.
It is obvious that we are considering our options to change when we are at odd positions and we are changing the optimal positions before or equal to the current index which is yet unchanged.
now, let n=5. so, for first 10 positions the considering points would be: 1 2 3 4 5 6 7 8 9 10.
at position 1 we have no option but to change the 1st position. so, for the first block of 2n we have to consider the optimal answer with compulsory changing of 1st position, which is stored in V(2n).
But for the 2n blocks which will we join later, it may not be optimal to change the 1st bracket of those blocks. let's take for position 11 to 20. changing the 11th position may not be optimal. So, for the rest of 2n block we take V(3n) — V(n) in which our optimal answer is stored regardless of the change in 1st position of that block. the number of block yet to consider is (m/2 — 1). which is the next part of the equation.
Thanks for mentioning the greedy approach. :)
I found a different greedy solution which can be done in $$$O(n \log m)$$$.
Let's first put opening brackets everywhere. We need to pick $$$nm/2$$$ positions and put closing brackets there, so the bracket sequence will be regular and the sum $$$b_{j \bmod n} - a_{j \bmod n}$$$ for all picked positions $$$j$$$ is the least possible.
Observation 1. Consider a set of positions with the same remainder modulo $$$n$$$. Obviously, it's best to move all picked positions in this set to the right, so brackets in this set will look like "((($$$\ldots$$$)))" (the cost will not change and the sequence will stay regular).
Now, the greedy idea: let's sort all remainders $$$i$$$ by $$$b_i - a_i$$$ and going through each $$$i$$$ in this order let's try to pick as many positions with the remainder $$$i$$$ as possible (by observation 1, we'll be picking these positions from the right). To do that optimally, let's binary search the number of picked positions. Now we need to check that the sequence is regular given the number of picked positions for each remainder.
Observation 2. It suffices to check only first $$$n$$$ and last $$$n$$$ prefix balances.
Proof. Let $$$0 \ldots i$$$ be a prefix with a negative balance. If there is a whole block to the left, there might be two cases. If that block's balance is positive, then blocks before it are also positive, and thus prefix $$$0 \ldots i \bmod n$$$ is negative. If that block's balance is not positive, the blocks after it are also not positive, so we can move to the right until we are in the last block. The prefix will still be negative.
This here 97872815 is $$$O(n^2 + n \log m)$$$, but it can be done in $$$O(n \log m)$$$ with data structures.
We'll use matroids (maybe overkill). Call a set of positions independent iff the sequence with closing brackets in these positions is regular. Obviously, empty set is independent, a subset of an independent set is independent. Now let $$$A$$$ and $$$B$$$ be independent sets, such that $$$| A | < | B |$$$. Let $$$i$$$ be the largest position in $$$B \setminus A$$$. It's easy to see that adding $$$i$$$ to $$$A$$$ will not make the set dependent. So, it's a bona fide matroid and the greedy works.
In fact you can solve problem E in O(n\log n) time by using simple data structure.
Problem D can also be solved in O(n\log n) time by using offline algorithm.
Actually, problem D can be solved in O(NlogN) by an online algorithm. Check 4673602 for details.
It took me 2 days just to understand your code. Got to learn a ton of things from it. Thanks!
I'm glad you found it useful. Persistent data structures is a very interesting topic, you can find some other implementations of them here.
Thank you very much! :)
351A — Jeff and Rounding, I'm now stuck by a VERY VERY weird situation. Can anyone help me?
My approach is greedy and the code was almost the same with Kyuubi's. You can search "Kyuubi" in this page to see his greedy algorithm, which is the same as mine. Thank you Kyuubi :)
The thing is, my codes 4722053 and 4722088 have the same code but one got Ac in 30ms while the other got TLE. The only difference is, I put the last two lines in the for loop in 4722088 outside the loop, and created a new loop for them. It's just the difference between
and
It's driving me mad. Who can help me figure out why it makes such huge difference?
All these weird problem are caused by some careless error, like visiting a[-1], or the array is not bit enough, or a variable has not been initialized. I had a too small array. Please ignore my previous post.
I've found a simpler solution to '351E — Jeff and Permutation': First, substitute each number with its absolute value, then iterate through the numbers in the same order they were given and for each of them (lets call the currently processed number 'i'), count numbers with less absolute value than i that go before i, and numbers with less (absolute) value than i that go after i. If there are more numbers of the first kind, multiply i by -1.
Finally, count the inversions and print the number.
The solution can be implemented in O(n log n) with range trees, but the brutal approach passes the tests with O(n^2).
Can you please explain why this is correct ?
A number j that has higher or equal absolute value to i will form an inversion with i iff one of the following is true:
j goes before i in the input sequence and j is positive,
j goes after i in the input sequence and j is negative.
The above means that the sign of i doesn't change the number of inversions that it forms with numbers of higher or equal absolute values. (*) We can forget about them as far as choosing sign for i is concerned.
(**) A number j that has lower absolute value than i will form an inversion with i iff one of the following is true:
j goes before i in the input sequence and i is negative,
j goes after i in the input sequence and i is positive.
Analogically, yet a little bit different. ;) This means that signs of numbers of less absolute value than i doesn't change the number of inversions that they form with i. (***) We can choose a sign for i without worrying about what sign will these numbers be.
(*) and (***), brought together, let us come to the conclusion that the sign for i can be determined regardless of other numbers' signs. E.g. greedily, why not. ;)
The condition that lets us decide what sign to give to i is a straightforward implication of (*) and (**). (*) tells us that there's no need to worry about numbers with higher/equal absolute value to i. We know from (**) that to minimize the number of inversions that i forms, i should be negative iff there are more numbers of less absolute value that go before i than those that go after i.
Feel free to see my submission: http://codeforces.net/contest/351/submission/4958417
Jeff and Periods —
I am getting correct output on my computer but a wrong output in the codeforces. What could possibly go wrong? This has happened with be already for a different problem. Any solutions for this?
Are you sure you get right answer for test #5 on your computer? On my machine and on CF your code outputs sth wrong.
You don't check if(count >= 0) in one place. Check out this change
Sorry, My bad. I checked it wrong. I might have checked it wrong for that other problem too. Thanks a lot for understanding my entire code and helping me out :D
In C, Jeff and Rounding — I am getting a compilation error for stof(). I used #include<bits/stdc++.h> and GNU C++11 Why doesn't it compile?
Почему в задаче D div.1 ответом на запрос является кол-во различных чисел +1, в случае отсутствия элемента, формирующего арифметическую последовательность? Если это правда, то на каждом ходе мы должны полностью удалять какое-то число из массива(возможно еще одно действие когда-то потратим в случае отсутствия элемента...). Разве это так очевидно, что никто не писал об этом в комментарии? :)
Чтобы удалить все вхождения какого-то числа достаточно, например, записать его в начало перемешанного массива и выбрать v = 1, t = 1. Ну и как вроде пишут выше, можно довольно просто решать за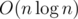 .
.
Спасибо! Я как-то третий пункт вообще упустил, даже когда перечитывал условие :)
IN PROBLEM 351B , could not understand . we have the formula for an answer ansI = 1 + 1 + ansI - 1 - 1 × 0.5 + ansI - 1 + 1 × 0.5 how we are calculating expectation using this formula
Suppose we have 'i' inversions at this time. Then during Jeff's turn i -> i-1 as he will always try to make the array sorted. But during Furik's turn 50% times i -> i-1 and 50% times i ->i+1.
So let the current state be dp[i];
Jeff's Turn : dp[i] = 1 + dp[i-1].
Now Furik's Turn : dp[i-1] = 1 + 0.5*dp[i-2] + 0.5*dp[i].
So, dp[i] = 1 + 1 + 0.5*dp[i-2] + 0.5*dp[i].
dp[i] = 4 + dp[i-2] (required recurrence)
Can someone Explain Jeff and Furik?
EV(n) = 1 + 0.5*(EV(n-2)) + 0.5*(2+EV(n))
EV(n) represent expected value for n inversions required. As Jeff starts the game so EV(n) should be equal to 1 + g where g is 0.5*(EV(n-2)) + 0.5*(2+EV(n)) (and now it's Furik's turn). If heads appears inversions reduces by 1 and if tails appears inversions increases by 1. so g = p(head)*EV(n-2) + p(tails)*(EV(n) + 2(as 2 turns are wasted))
Suppose we have 'i' inversions at this time. Then during Jeff's turn i -> i-1 as he will always try to make the array sorted. But during Furik's turn 50% times i -> i-1 and 50% times i ->i+1.
So let the current state be dp[i];
Jeff's Turn : dp[i] = 1 + dp[i-1].
Now Furik's Turn : dp[i-1] = 1 + 0.5*dp[i-2] + 0.5*dp[i].
So, dp[i] = 1 + 1 + 0.5*dp[i-2] + 0.5*dp[i].
dp[i] = 4 + dp[i-2] (required recurrence)
In 351B — Jeff and Furik, could you please explain why we can transform from
2 * ansI -ans(I-2)-4 = ansI
to ansI = 4 + ans(I - 2) ?
my question might sound a little stupid but, really,...
for example when we recursively call x = x + 1, we cannot transform to x-x = 1 <=> 0 = 1
Can anynyone clearly explain the recurrence of Div1 B jeff and furik??
Suppose we have 'i' inversions at this time. Then during Jeff's turn i -> i-1 as he will always try to make the array sorted. But during Furik's turn 50% times i -> i-1 and 50% times i ->i+1.
So let the current state be dp[i];
Jeff's Turn : dp[i] = 1 + dp[i-1].
Now Furik's Turn : dp[i-1] = 1 + 0.5*dp[i-2] + 0.5*dp[i].
So, dp[i] = 1 + 1 + 0.5*dp[i-2] + 0.5*dp[i].
dp[i] = 4 + dp[i-2] (required recurrence)
351D — Jeff and Removing Periods submission matching the editorial description.
For 351D — Jeff and Removing Periods, I wrote a blog. It's heavily based on rlac's submission.