


Думаю всем нам не нравится видеть в прямом эфире спам. Не смотря на то что от этого спама никакой пользы нет, спамеры будут продолжать спамить. Возможно это вообще боты создают новые аккаунты и пишут всякую бессмыслицу. Сегодня вот что увидел:
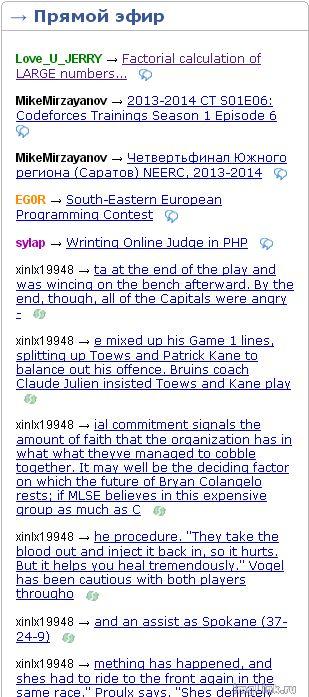
Мне кажется можно легко придумать и реализовать несколько простых мер, для того чтобы спамить стало сложнее, и спам быстро уходил из эфира.
Для того чтобы усложнить создание аккаунтов из которых постится спам можно сделать так, чтобы новые аккаунты не могли писать в блог и комментировать до того как не решена первая задача на реальном соревновании. Также этими правами могут наделить чужой аккаунт участники первого дивизиона.
Для того чтобы убирать спам оперативно можно завести кнопку "спам" видимую некоторым участникам-"дружинникам". Если у нас будет хотя бы 20 "дружинников" регулярно заходящих на сайт спам не будет висеть сутками в прямом эфире. За отправление дружинником в спам записей которые не являются спамом дружинников надо наказывать и лишать должности.
Не думаю что эти меры сложны в реализации. Нужно уделить этому моменту некоторое внимание, спам уже достал.
PS: еще неплохо бы сделать свой хостинг изображений, ибо записи создаваемые пользователями будут постепенно терять свои изображенияиз-за недобросовестных хостингов.






