


^_^
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
37:31:58
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
37:31:58
Зарегистрироваться »
*есть доп. регистрация
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир





We invite you to participate in CodeChef’s Starters 93, this Wednesday, 7th June, rated for all coders.
Time: 8:00 PM — 10:00 PM IST
Note that the duration is 2 hours. Read about the recent CodeChef changes here.
Joining us on the problem setting panel are:
Setters: Kanhaiya notsoloud1 Mohan, Likhon5, Saksham sakshamm123 Mahajan, Shivansh ShivanshJ Jaiswal, Andrei Sho Alexandru, Divyesh divyesh_11 Jivani, Mostafa Beevo Alaa, Tushar CODE_LOVER4655 Singhal
Testers: Nishank IceKnight1093 Suresh
Video Editorialists: Madhav jhamadhav Jha, Suraj jhasuraj01 Jha, Jwala jwalapc, Adhish ak2006 Kancharla, Pravin pravin_as Shankhapal
Text Editorialists: Nishank IceKnight1093 Suresh
Statement Verifier: Kanhaiya notsoloud1 Mohan
Contest Admin: Jatin rivalq Garg
Written editorials will be available for all on discuss.codechef.com. Pro users can find the editorials directly on the problem pages after the contest.
The video editorials of the problems will be available for all users for 1 day as soon as the contest ends, after which they will be available only to Pro users.
We’re hiring! If you’d like to intern at CodeChef as a Learning Content Creator, click here.
Also, if you have some original and engaging problem ideas, and you’re interested in them being used in CodeChef's contests, you can share them here.
Are you ready to dance to the rhythm of Ariana Grande's songs while coding? We sure are! Join us for an unparalleled contest experience. And before you go, drop your favorite Ariana Grande song in the comments. Let's see which tune gets the most love!
I hope you all liked the round. Please share your feedback in the comments section.
1747A — Two Groups
Hint
Tutorial
Solution
1747B — BAN BAN
Hint 1
Hint 2
Hint 3
Tutorial
Solution
1747C — Swap Game
Hint 1
Hint 2
Tutorial
Solution
1747D — Yet another Problem
Hint 1
Hint 2
Hint 3
Tutorial
Solution
1747E — List Generation
Hint 1
Hint 2
Tutorial
Solution
Hi Codeforces!
I am pleased to invite you to Adhocforces, Mathforces Codeforces Round #832 (Div. 2), which will take place on Friday, Nov 4, 2022 at 14:35 UTC. You will be given 5 problems and 2 hours to solve them.
The round will be rated for participants of Division 2 with a rating lower than 2100. Division 1 participants can participate unofficially in the round.
All problems in this round were prepared by me and CoderAnshu.
I would like to thank:
- antontrygubO_o for coordination of the round.
- ffao, Everule, Andreasyan, koderkushy, nor, AlperenT, the_hyp0cr1t3, Runtime-Terr0r, sp005, 18o3, KingRayuga, Scythe and sus for testing this round and giving really valuable feedback.
- MikeMirzayanov for the amazing Codeforces and Polygon platforms!
- You for participating.
The score distribution will be announced shortly before the round (or earlier).
Good luck and have fun! See you in the standings.
UPD 1:
Scoring distribution: 500 — 1000 — 1250 — 1750 — 2500
UPD 2:
I am flying to dhaka so will post editorials later.
UPD 3:
Congratulations to our winners!
Overall:
Div 2:
UPD 4: Editorial for A to C has been posted, will post D,E soon.
UPD 5: Editorial for D is posted.
UPD 6: Finally editorial for E is posted.
I hope you all liked the round. Please share your feedback in the comments section.
1682A — Palindromic Indices
Hint
Tutorial
Solution
1682B — AND Sorting
Hints
Tutorial
Solution
1682C — LIS or Reverse LIS?
Hint
Tutorial
Solution
1682D — Circular Spanning Tree
Hints
Tutorial
Solution
1682E — Unordered Swaps
Tutorial
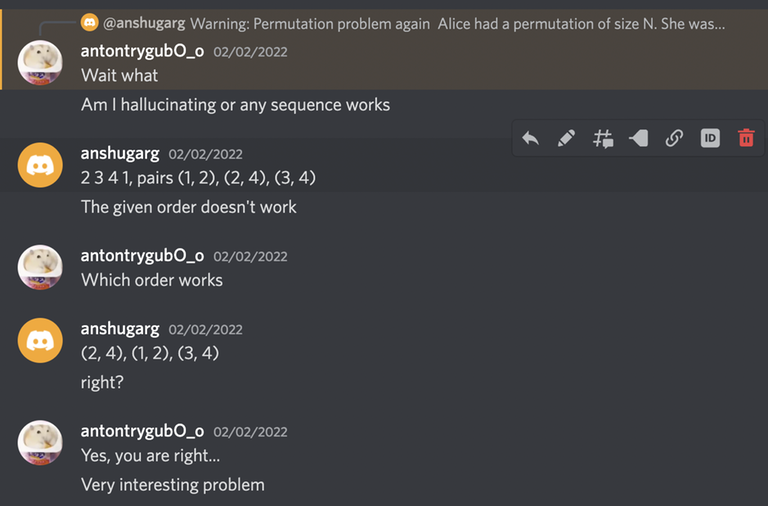
Solution
1682F — MCMF?
Tutorial
Solution
Hello Codeforces!
I'm Jatin, a member of COPS IIT(BHU). I attempted a screen-cast of Codeforces Round #747 (DIV. 2) followed by a short discussion of the solutions to problems. I managed to solve the first 6 problems (A — E2) and got 242 overall rank.
Video:Screencast
Do subscribe to our channel and share the content if you find it helpful. As always, feel free to comment below.
Thanks for reading and see you in the next contest!

Hi Everyone !! I am Jatin Garg from Competitive Programming Group IIT BHU. Today I attempted to make the screencast In Hindi for the Codeforces Round 697 (Div3). I was able to solve all problems during the contest and got 144th rank. I also shared my approach to solving the problems during the contest.
Do check it out:
— https://www.youtube.com/watch?v=Ha3Xw9Tq1Po
Do like and subscribe to the channel. We will be posting editorials for future contests, so stay tuned.
Hi Everyone !! I am Jatin Garg from Competitive Programming Group IIT BHU. Yesterday I attempted to make the screencast for the Codeforces Round 693 (Div3). I was able to solve problem A to E and G during the contest (got 330th rank) and later upsolved F in a separate video. I also shared my approach to solve the problems during the contest.
Do check it out:
— https://www.youtube.com/watch?v=Wzz5psk5PWs (Screencast)
— https://www.youtube.com/watch?v=x4oIUhKpsk8 (Problem F)
Do like and subscribe to the channel. We will be posting editorials for future contests, so stay tuned.
Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 22.11.2024 04:03:04 (k2).
Десктопная версия, переключиться на мобильную.
При поддержке
