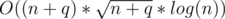Problem A: Ebony Ivory
The problem is to find if there exists a solution to the equation: ax + by = c where x and y are both positive integers. The limits are small enough to try all values of x and correspondingly try if such a y exists. The question can also be solved more efficiently using the fact that an integral solution to this problem exists iff gcd(a, b)|c. We just have to make one more check to ensure a positive integral solution.
Complexity: O(log(min(a, b))
Problem B: A Trivial Problem
We know how to calculate number of zeros in the factorial of a number. For finding the range of numbers having number of zeros equal to a constant, we can use binary search. Though, the limits are small enough to try and find the number of zeros in factorial of all numbers of the given range.
Complexity: O(log(n)2)
Problem C: Spy Syndrome 2
The given encrypted string can be reversed initially. Then dp[i] can be defined as the index at which the next word should start such that the given string can be formed using the given dictionary. Rabin Karp hashing can be used to compute dp[i] efficiently.
Also, care must be taken that in the answer the words have to be printed in the correct casing as they appear in the dictionary.
Complexity: O(n * w) where n is the length of the encrypted string, w is the maximum length of any word in the dictionary.
Problem D: Fibonacci-ish
The key to the solution is that the complete Fibonacci-ish sequence is determined by the first two terms. Another thing to note is that for the given constraints on a[i], the length of the Fibonacci-ish sequence is of logarithmic order (the longest sequence possible under current constraints was of length~90) except for the case where a[i] = a[j] = 0, where the length can become as long as the length of the given sequence. Thus, the case for 0 has to be handled separately.
Complexity: O(n * n * l) where n is the length of the given sequence and l is the length of the longest Fibonacci-ish subsequence.
Problem E: Startup funding
Let us denote the number of visitors in the ith week by v[i] and the revenue in the ith week by r[i].
Let us define z[i] = max(min( 100 * max(v[i...j]), min(c[i...j]))) for all (j > = i). Note that max(v[i...j]) is an increasing function in j and min(r[i...j]) is a decreasing function in j. Thus, for all i, z[i] can be computed using RMQ sparse table in combination with binary search.
Thus the question reduces to selecting k values randomly from the array z. Let us suppose we select these k values and call the minimum of these values x. Now, x is the random variable whose expected value we need to find. If we sort z in non-decreasing order:
E(X) = (z[1] * C(n - 1, k - 1) + z[2] * C(n - 2, k - 1) + z[3] * C(n - 3, k - 1)....) / (C(n, k))
where C(n, k) is the number of ways of selecting k objects out of n. Since C(n, k) will be big values, we should not compute C(n, k) explicitly and just write them as ratios of the previous terms. Example: C(n - 1, k - 1) / C(n, k) = k / n and so on.
Complexity: O(n * lgn)
Problem F: The Chocolate Spree
The problem boils down to computing the maximum sum of two disjoint weighted paths in a tree (weight is on the nodes not edges). It can be solved applying DP in the following manner:
First, for every node, for every edge connected to it, let's calculate the two paths starting from u which do not include edge i, and have the largest possible number of chocolates. Note that the two paths thus calculated should not contain any common node except u.
Again, let's compute for every node (say u), for every edge connected to it (say i), the path with most chocolates in the subtree of node u formed by excluding the edge i.
Thus, we can now iterate for all edges (say (u,v)) and compute the maximum sum of subtree of u and subtree of v when the current edge is removed. Refer implementation for details: http://pastebin.com/N2gsnqJg
Complexity: O(n) where n is the number of nodes in the tree.
Problem G: Yash and Trees
Perform an euler tour (basically a post/pre order traversal) of the tree and store it as an array. Now, the nodes of the subtree are stored are part of the array as a subarray (contiguous subsequence). Query Type 2 requires you to essentially answer the number of nodes in the subtree such that their value modulo m is a prime. Since, m ≤ 1000, we can build a segment tree(with lazy propagation) where each node has a bitset, say b where b[i] is on iff a value x exists in the segment represented by that node, such that 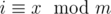 . The addition operations then are simply reduced to bit-rotation within the bitset of the node.
. The addition operations then are simply reduced to bit-rotation within the bitset of the node.
Complexity: O(n * lgn * f), where n is the cardinality of the vertices of the tree, f is a small factor denoting the time required for conducting bit rotations on a bitset of size 1000.
Problem H: Fibonacci-ish II
The problem can be solved by taking the queries offline and using a square-root decomposition trick popularly called as “Mo’s algorithm”. Apart from that, segment tree(with lazy propagation) has to be maintained for the Fibonacci-ish potential of the elements in the current [l,r] range. The fact used in the segment tree for lazy propagation is:
F(k + 1) * (a1 * F(i) + a2 * F(i + 1)...) + F(k) * (a1 * F(i - 1) + a2 * F(i) + ....) = (a1 * F(i + k) + a2 * F(i + k + 1)....)
Example: Suppose currently the array is [100,400,500,100,300]. Using Mo's algorithm, currently the segment tree is configured for the answer of the segment [3,5]. The segment tree' node [4,5] will store answer=500*F(2)=1000. In general, the node [l1, r1] of segment tree will contain answer for the values in the current range of [l2, r2] of Mo's for the values that have rank in sorted array [l1, r1]. The answer will thus be of the form a1 * F(i) + a2 * F(i + 1).... We maintain an invariant that apart from the answer, it will also store answer for one step back in Fibonacci, i.e., a1 * F(i - 1) + a2 * F(i).... Now, when values are added (or removed) in the segment tree, the segments after the point after which the value is added have to be updated. For this we maintain a lazy count parameter (say k). Thus, when we remove the laziness of the node, we use the above stated formula to remove the laziness in O(1) time. Refer our implementation for details: http://pastebin.com/MbQYtReX
Complexity: