Two weeks ago I made a game where you have to guess the true ratings of New Year magic users. You can still play it here. Now, let's have a look at some results and interesting comments.
The most accurate responses are to comments that just straight up tell you their real rating:
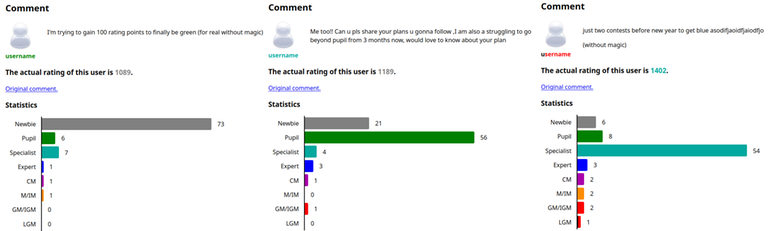
But this can backfire! The funniest comment, to me, is this:
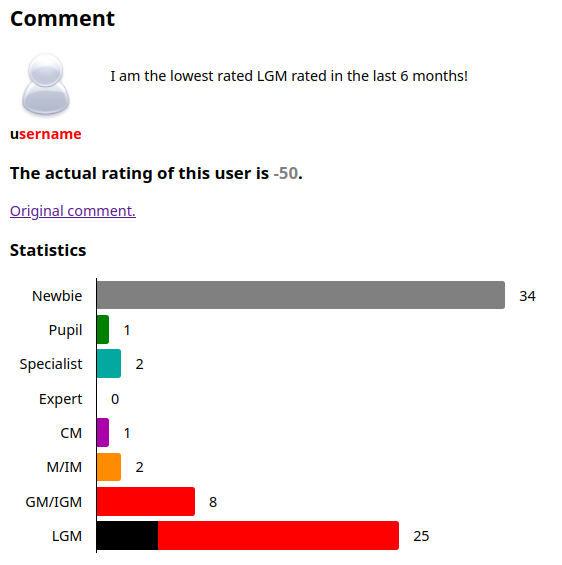
With this one, you actually know they're not really LGM. I think a lot of players missed this, but the database only includes comments where the author was a magic user. Since you see a black-and-red name, you know that this user is not really nutella.
The most inaccurate guesses went to this comment. I would not have guessed LGM either.
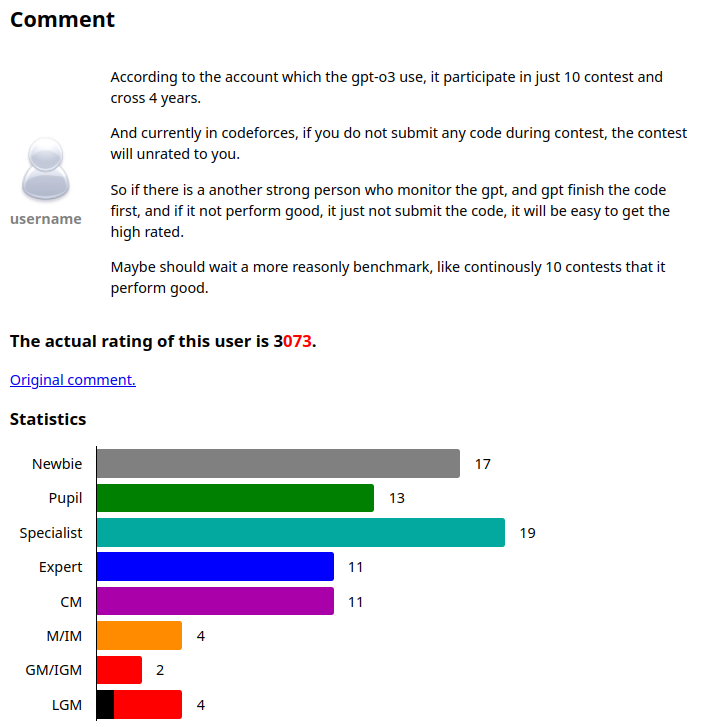
Any math is GM, apparently:

Plot
Finally, here's the comparison of "mean guessed rank" and the actual rating:
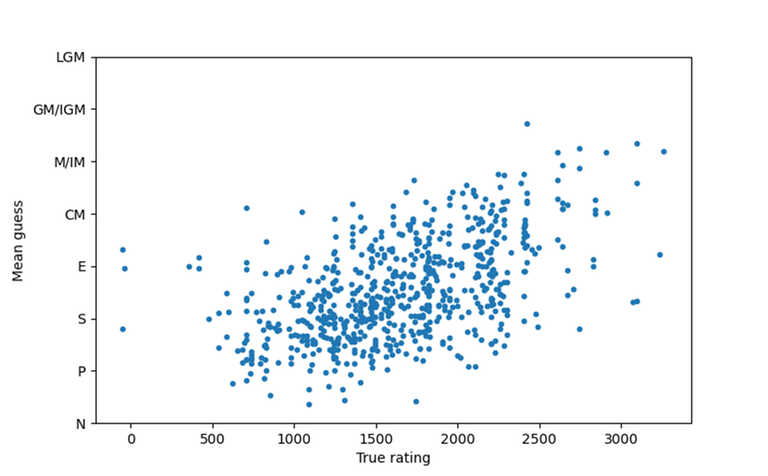
"Mean guessed rank" is calculated by assigning each rank a numeric value (Newbie = 0 to LGM = 7; M and IM count as one rank as do GM and IGM, just as in the game) and taking the mean of all guesses. This doesn't make perfect sense, but is good enough. There's definitely an upwards line in the scatter plot, I think on average you did pretty well.
I've added a new browse page to the game so you can search for comments with interesting statistics yourself. Also, if you want to poke around the statistics data, you can download the full dataset here.