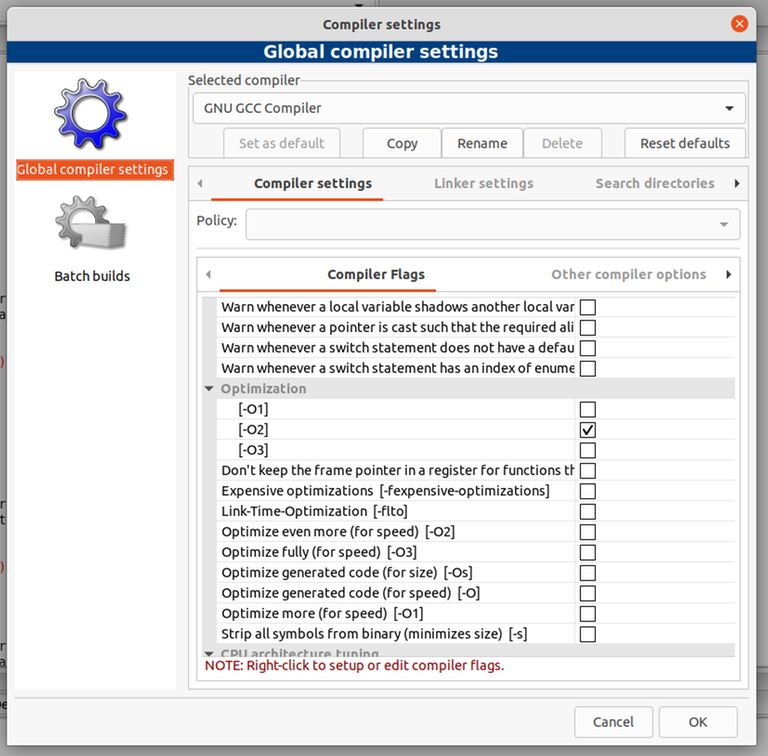
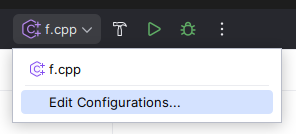
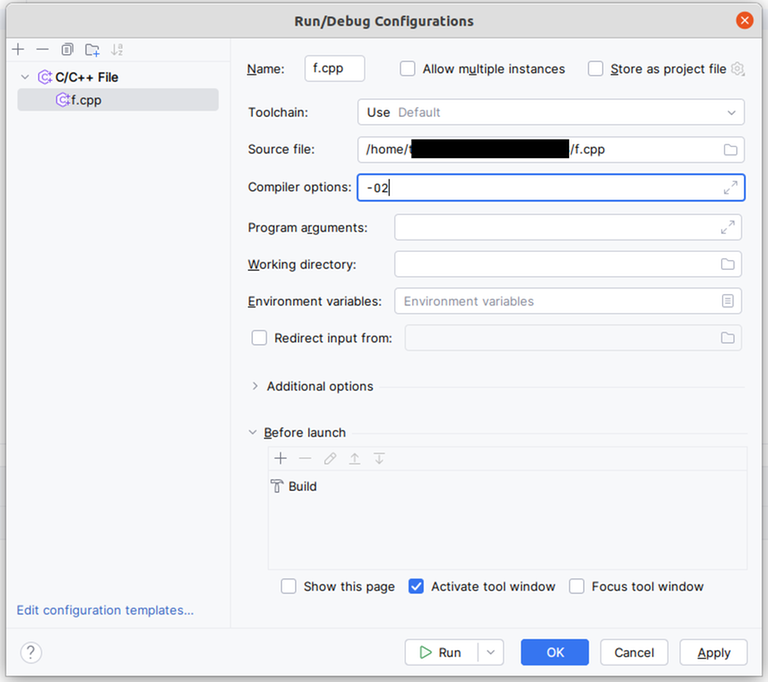
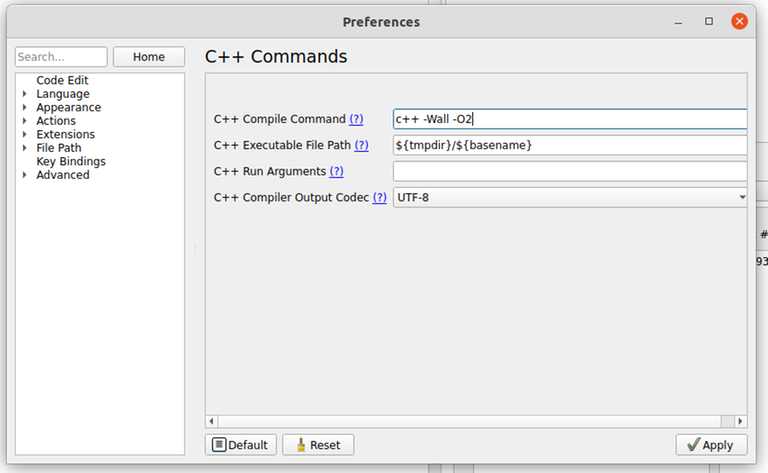
This is my in-contest submission for 2048F - Kevin and Math Class: 297343653. It got "runtime error on pretest 3", which I initially thought was some stupid bug. After the contest was over, I was surprised to see "exit code: -1073741571 (STATUS_STACK_OVERFLOW)". Stack overflow happens when the recursion goes too deep, but the stack limits on Codeforces are pretty generous, and recursion 2e5 calls deep is generally not an issue (imagine how annoying all DFS problems would be otherwise).
At first I thought that this must still be a bug that led to infinite recursion. But I verified locally that this is not the case, and I added an assertion to check that no more than 2e5 calls to solve(ll, ll) are performed in any one test case:
ll solve (ll l, ll r) {
cnt++;
assert(cnt < maxn);
// .. rest of the function ..
I also moved the references to tree and arr to global variables for good measure. Still a stack overflow: 297352244.
For what it's worth, both versions get accepted under C++20: 297353626, 297353915.