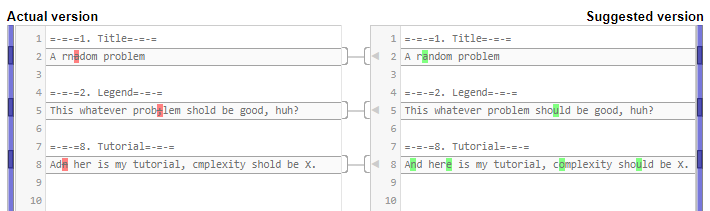
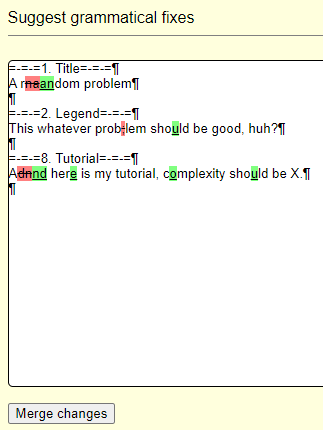
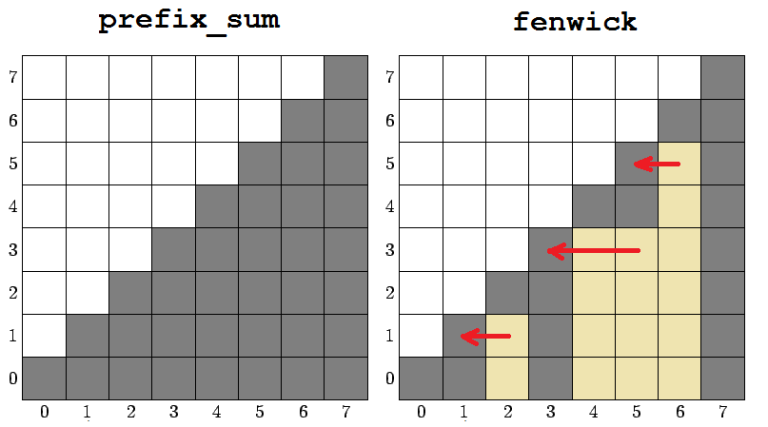
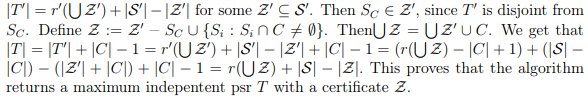Codeforces allows users to choose their locations and organizations in "Social" tab in profile settings.

If configured, this information is shown in user profile to everyone and also includes user into filtered rating list of selected country, city and organization.
This is a nice functionality, but I've always felt that this is incomplete. People tend to change locations and organizations over time, but currently there can be only one location and only one organizaton. But which one to choose? There are multiple options that seem reasonable
- Your current location/organization
- Location/organization/team where you had peak performance
- Your alma mater
- Your origin/place of birth
From what I've seen different people resolve this ambiguity in different ways. This has it's impact on filtered rating lists. You will see a person in organization in these cases:
- Active user who is currently in this organization
- Active user who decided to keep this organization in his profile
- Inactive user who was in this organization at the moment he was active
- A user who does not bother to update profile
For me this leads to a strange feeling that filtered rating lists of smaller organizations and cities tend to "dry out" with active and strong participants switching away from them.
Porposal. In addition to one current location and one current organization add a list of past locations and past organizations.
This will be great for users (including me) who want
- to keep their history in their CF profile
- to represent more than one location/organization
Adding "Include past locations" and "Include past organizations" checkboxes to filtered rating lists will make them way more interesting to explore. It will be possible to more reliably compare your and your friends' ratings against alumni of your school/university, entries in rating lists of small cities/organizations will persist. It will be possible to more reliably find and compare yourself against ex-collagues and people with the same origin.
Of course these lists should be editable and only keep information if the user wants it.
Profile can include links or options to expand past locations and organizations. Something like this

MikeMirzayanov and Codeforces community, what do you think about it?