


When I was a little child I learned a lot (indirectly via the website which also have a community-driven english transation) from e-maxx.(Orz).
In particular, there is a post about Dijkstra on sparse graphs (English version. It is mentioned there that priority_queue is based on heaps, thus has smaller hidden constant then set which is based on RB-trees. Explanation makes perfect sense.
I got back from quite a long break from CP and checked the recent Educational Codeforces Round 102 (Rated for Div. 2) for a warm up. There was a nice problem 1473E - Minimum Path authored by Neon which required Dijkstra's algorithm. So I used the priority_queue based one from my template 105061903 and got TLE 61. I thought of several bad words and started to optimize. Eventually, I tried the set-based solution and got AC 105066945. For your convenience, there is a diff between the submissions:
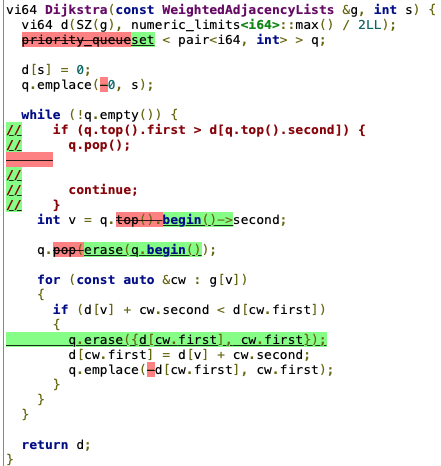
Is it some other hidden bug in my code, or is set-based Dijkstra works faster then priority_queue one? When and why?






