


Hi Folks,
I wrote the this solution for this Tree Constructing but i kept getting runtime error during the contest. Though i managed to get my solution accepted by changing few things but still did not understand why i was getting runtime error. Can anybody help here ?









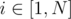 if it exists where
if it exists where 