


![]() Привет, Codeforces!
Привет, Codeforces!
Я рад анонсировать, что компания Rocket Fuel Inc. снова будет проводить соревнование Rockethon! Контест подготовили сотрудники компании Эльдар Богданов, Антон Ломонос, Лаша Лакирбая, Александр Рафф, Никил Гоял и я, Евгений Соболев. Мы надеемся, что каждый из вас найдет для себя интересные задачи на контесте и от решения этих задач вы получите не меньше удовольствия, чем получили мы от их подготовки. Как и в прошлом году, лучшие участники получат ценные призы и футболки. Помимо этого, Rocket Fuel заинтересован в рекрутинге людей после соревнования, поэтому, пожалуйста, заполните простую форму при регистрации.
О Rocket Fuel
Rocket Fuel is building technology platform to do automatic targeting and optimization of ads across all channels — display, video, mobile and social. Our pitch to advertisers is very simple "If you can measure metrics of success of your campaign, we can optimize". We run campaigns for many large advertisers and our clients include many top companies within the following industries: autos, airlines, commercial banks, telecom, food services, insurance, etc. Examples include BMW, Pizza Hut, Brooks Running Shoes and many more!
We buy all our inventory through real time bidding on ad exchanges like Google and Yahoo. Ad exchanges are similar to stock exchanges except the commodity being traded is ad slots on web pages. Our serving systems currently process over 60B bid requests/ day with a response time requirement of 100ms. Our data platform has 64 PBs data that is used for analytics as well as modeling.
Our engineering team is still small (~150) enough for any one person like yourself to make a huge impact. The team represents many top schools in US and outside — Stanford, Carnegie Mellon, MIT, Wisconsin-Madison, IIT (India), Tsinghua (China).
Rocket Fuel has been named #4 on Forbes Most Promising Companies in America List in 2013 and #1 Fastest Growing Company in North America on Deloitte’s 2013 Tech Fast 500 and our CEO George John was recently named “Most Admired CEO” by the SF Business Times in 2014.
Мои впечатления
Около года назад я зашел на Codeforces и увидел объявление о Rockethon 2014. Моей первой мыслью было: "Круто! Еще одно соревнование от крупной компании!" Я поучаствовал, выступил достаточно неплохо, после чего со мной связались рекрутеры Rocket Fuel и назначили несколько собеседований. Я прошел собеседования и теперь я здесь, в Rocket Fuel.
Работа в Rocket Fuel — это отличная возможность изучить продвинутые вещи в software engineering, так как вокруг работают много умных людей, которые всегда готовы делиться своими знаниями. Конечно, наша деятельность не ограничивается только лишь написанием кода — мы играем в баскетбол, футбол, настольный теннис. Я приглашаю каждого из вас принять участие в соревновании и буду рад услышать если вы задумываетесь о трудоустройстве в Rocket Fuel.
Обзор соревнования
Контест начнется 7-го февраля в 20:00 МСК.
Продолжительность контеста — 3 часа.
Тестирование посылок будет производиться сразу же после их отправления и вердикты тестирования будут немедленно показаны авторам посылок.
В контесте будет 7 задач, каждая из которых может иметь от одной до трех подзадач. Каждая подзадача будет стоить некоторое фиксированное число баллов. Если несколько участников наберут одинаковое число баллов, выше будет стоять тот участник у которого будет меньше штрафное время, вычисляемое аналогично ACM-системе.
Призы
Три лучших участника получат следующие призы:
1) IPhone 6 (16 Gb)
2) Участник может выбрать Apple Watch или Samsung Gear S
3) Участник может выбрать Apple Watch или Samsung Gear S
Лучшие 150 участников получат футбоолки Rockethon с оригинальным дизайном соревнования.
Если вы не можете принять участие в соревновании, но заинтересованы в трудоустройстве в Rocket Fuel, мы будем обрабатывать резюме отправленные через специальную форму.






 , следующая —
, следующая — 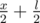 , следующая —
, следующая — 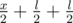 и так далее.
и так далее.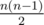 , то за
, то за 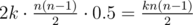 .
.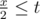 , или
, или 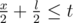 , или
, или 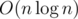 . Ее можно улучшить, если вместо двоичного поиска использовать метод двух указателей.
. Ее можно улучшить, если вместо двоичного поиска использовать метод двух указателей.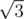 ) и
) и 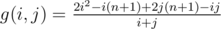 возрастает, поэтому можем использовать метод двигающегося указателя для перебора
возрастает, поэтому можем использовать метод двигающегося указателя для перебора 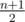 , затем
, затем 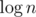 итераций с фиксированным
итераций с фиксированным  и идти по всем делителям
и идти по всем делителям 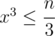 ? далее будем идти по делителям
? далее будем идти по делителям 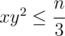 и в конце будем вычислять
и в конце будем вычислять 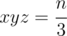 .
.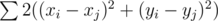 для всех целых точек внутри многоугольника (или на его границе). Можно заметить, что мы можем обрабатывать иксы и игреки независимо.
для всех целых точек внутри многоугольника (или на его границе). Можно заметить, что мы можем обрабатывать иксы и игреки независимо.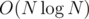 запросов и операций добавления.
запросов и операций добавления.

