


Here you can find the solutions for the problems from the past round. You can ask questions in the comments below.
If ai divide aj than ai ≤ aj. So the number which will divide every other number should be less than or equal to every other number, so the only possible candidate — it's the minimum in the array. So just check whether all elements are divisible by the minimal one.
Easy to see, that Ksusha is unable to complete her journey if there is a sequence of consecutive # with length more than k.
The first observation — we don't care about the actual strings, all information we need — number of pairs {0,0}, {0,1}, {1,0}, {1,1}. Count that and then just follow the greedy algorithm, for the first player: try to get a index with {1,1} if there are some, than {1,0}, than {0,1} and than {0,0}.
For the second player similar strategy: first {1,1}, than {0,1}, than {1,0}, than {0,0}.
After that just compare who has more 1.
Every path from the topleft cell to the bottomright cell contain exactly n + m - 1 cells. And all of the should be of different color. So n + m - 1 ≤ k. Due to the small constraints for k we may assume that bruteforce might work. The only optimization to get the correct solution is some canonization of the colors. So let's go over all of the cells in some order and color them but with following condition. If i > j, than color i appeared later than color j. If we bruteforce in such way we will have about 1 million different patterns for max case. Than just match them with already painted cells and calculate for each pattern how many different permutations of color we can apply to it.
After reading the problem statement one can understand that all we need is to calculate the number of positive integer solutions of equation: (a + b + c)3 - a3 - b3 - c3 = n.
The key observation is: 3(a + b)(a + c)(b + c) = (a + b + c)3 - a3 - b3 - c3, after that simply calculate all divisors of  and then first go over all x = a + b, such that
and then first go over all x = a + b, such that 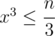 then go over all y = (a + c) ≥ x, such that
then go over all y = (a + c) ≥ x, such that 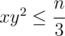 and then determine z = (b + c), such that
and then determine z = (b + c), such that 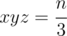 . After that we need to solve the system a + b = x, a + c = y, b + c = z and find out how many solutions it adds.
. After that we need to solve the system a + b = x, a + c = y, b + c = z and find out how many solutions it adds.
We can see that we asked to calculate 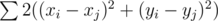 for all integer points inside the polygon or on its border. We can see that we can process Xs and Ys independently.
for all integer points inside the polygon or on its border. We can see that we can process Xs and Ys independently.
For each x determine yleft, yright, such that all points (x, y) where yleft ≤ y ≤ yright are inside the polygon and the range [yleft, yright] is as maximal as possible. Now let's assume that we have a1, a2, ..., ak different points with fixed x coordinate (a1 stands for x = - 106, a2 for x = - 106 + 1 and so on).
Now the required answer is a2a1 + a3(a2 + 22a1) + a4(a3 + 22a2 + 32a1) + ...
We can see that:
(a2 + 22a1) - a1 = a2 + 3a1,
(a3 + 22a2 + 32a1) - (a2 + 22a1) = a3 + 3a2 + 5a1,
and so on.
So we can precalculate partial sums like a2 + 3a1, a3 + 3a2 + 5a1, a4 + 3a3 + 5a2 + 7a1 (the difference between two consecutive sums is 2(ai + ... + a1), so we can do that in O(k) time).
After this precomputation we just need to sum the results.
Let's assume that we have a data structure which can perform such operations as: — add point (x,y) to the structure;
shift all points in the structure by vector (dx,dy);
answer how many point (x,y) are in the structure where x ≤ xbound, y ≤ ybound;
get all elements which are now in the structure;
For every vertex of the tree we will store the pointer to such structure.
How we update the structures. We will proceed all the vertices in dfs order, if we are in a leaf node, than we create structure which contains only one element (0,0).
Otherwise we will sort the children structures by it's size in decreasing order and assign the pointer of the biggest structure to the pointer of the current vertex (Don't forget to shift the structure by (1, weight of edge)).
After that we will go over all other children one by one and do the following thing:
Shift the structure by (1, weight of edge);
Get all elements from the structure;
For every element (x,y) answer the query xbound = L - x, ybound = W - y (we use parent's structure);
Add elements one by one into the structure;
After that answer the query xbound = L, ybound = W and add element (0,0).
The sum of the results of all the queries is our answer. It's easy to see that there will be no more than 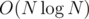 queries and add operations.
queries and add operations.
The remaining part is designing the structure.
It can be done in many ways. One of the ways:
We have small structures with sizes equals to powers of two;
Each structure — it's two-dimensional segments tree;
We can add one element in a following way: if there is no substructure with size 1, than add it; else get structures with sizes 1, 2, 4, ..., 2k and all its' elements and rebuild the structure with size 2k + 1;
Shifting — just remember shifting vector for every substructure;
Answering the query — go over all substructures and add the results.







anyone know how to solve Problem D,please help me , I've read the edutial again and again , but still can't understand
how to determine yleft and yright
Okay, I assume there are several approaches to do that. One of them — just go over every side of polygon and update y_left and y_right for every x it covers. For example, if we have side with vertices (x1, y1) — (x2, y2) than it covers range [x1,x2] and for every x you can determine corresponding y and two integer values which are the closest to it. But it requires careful implementation, because not both of those y are inside the polygon.
I mention E div 2. Can you explain how to get all these x,y,z quicker than look at all integer in the interval [1..n]?
Can you please fix the C problem since the god damn program asks for one thing, you guys in the tutorial show another thing and the people who have solved it used a whole different method. It's really frustrating to start a problem and then realise that the enunciation is not translated properly or does not properly tell you what you have to do. Thanks.
Does the solution for E have (nlogn)*(log2n) complexity? nlogn for the number of queries, and log2n for the complexity of each query. Or is there an easier way to solve it?
You can expend log(n) for each query if you use a persistent segment tree.
Cant the E problem be solved using centroid decomposition, I feel maintaining the data structures becomes easy, and we have the flexibility to calculate the number of good pairs passing through the centroid in $$$O(N)$$$ or even $$$O(NlogN)$$$ per centroid.
Here in this solution, it is not required to do shifting operations (as mentioned in the editorial) and the implementation would become relatively easier. It's just enough to count the number of pairs $$$(x,y)$$$ where $$$x <= x_i$$$ and $$$y <= y_i$$$, which can be solved by sorting + ordered_set. So it takes $$$O(NlogN)$$$ per centroid, and total complexity is $$$O(Nlog^2(N))$$$
Submission: 280804865
Ashwanth.K I am using centroid decomposition to solve this problem. When make dfs(centroid), I store data in map<pair<int, int>, int> data; // data[{len, weight}] = cnt; But I do not know how to calculate the number of paths that satisfy len <= l and weight <= w efficiently. Could you explain more details about your implementation?
Here is my TLE submission