


I've just turned International Grandmaster. Now you can ask me anything in the comments.
→ Pay attention
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 157 |
| 6 | Qingyu | 156 |
| 7 | djm03178 | 152 |
| 7 | adamant | 152 |
| 9 | luogu_official | 150 |
| 10 | awoo | 147 |
→ Find user
→ Recent actions






Author: TheScrasse
Preparation: TheScrasse
Hint 1
Solution
Official solution: 150288088
Author: emorgan
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Solution
Official solution: 150288210
Author: emorgan
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Official solution: 150288232
Author: emorgan
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Hint 4
Hint 5
Solution
Official solution: 150288255
1654E - Арифметические операции
Author: emorgan
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Solution
Official solution: 150288285
1654F - Минимальное XOR-ирование строки
Author: dario2994, emorgan
Preparation: dario2994, TheScrasse
Hint 1
Hint 2
Hint 3
Solution
Official solution: 150288326
Author: emorgan
Preparation: dario2994, emorgan, TheScrasse
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Official solution: 150288345
Author: dario2994, TheScrasse
Preparation: dario2994, TheScrasse
Hint 1
Hint 2
Hint 3
Hint 4
Hint 5
Solution
Official solution: 150306974
Hello everyone,
in this tutorial we will see a trick that can be useful in combinatorics and/or DP tasks. In particular, you can use it when the statement says something similar to "the score of an array is the product of its elements, find the sum of the scores over all the possible arrays".
Prerequisites: basic combinatorics and DP
The trick
The trick is very simple.
"The score of an array $$$a$$$ is $$$\prod_{i=1}^n a_i$$$" can be rephrased as "if there are $$$n$$$ boxes, and the $$$i$$$-th box contains $$$a_i$$$ distinguishable balls, the score of $$$a$$$ is equal to the number of ways to color a ball for each box".
This is quite obvious, but it can be extremely powerful. Let's see some problems that are trivialized by this trick.
Dwango Programming Contest 6th, problem C (rating: 2618)
Hint 1
Hint 2
Hint 3
Hint 4
Hint 5
Solution
abc231_g (rating: 2606)
Hint 1
Hint 2
Hint 3
Hint 4
Hint 5
Solution
Bonus
arc124_e (rating: 3031)
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Other problems
arc147_d - Sets Scores (rating: 2145)
abc214_g - Three Permutations (rating: 2893) (suggested by __hermit__)
agc013_e - Placing Squares (rating: 3455) (zscoder)
1842G - Tenzing and Random Operations
IOI 2022/4 - Digital Circuit
abc225_h - Social Distance 2 (rating: 3061) (__hermit__)
Conclusions
We've seen that "product trick" is very useful to find a DP that solves the problem. There exist similar counting tricks: for example, "The score of an array $$$a$$$ is $$$\sum_{i=1}^n a_i^2$$$" can be rephrased as "if there are $$$n$$$ boxes, and the $$$i$$$-th box contains $$$a_i$$$ distinguishable balls, the score of $$$a$$$ is equal to the number of ordered pairs of balls belonging to the same box" (you can try to use it in 1278F - Cards).
Of course, suggestions/corrections are welcome. In particular, please share in the comments other problems where you can use this trick.
I hope you enjoyed the blog!
UPD: I was wrong :(
UPD2: I was wrong, again.
Hello everyone,
I see that many people complain about copied problems. Their claim is that authors weren't able to come up with some problems, and decided to copy them from other sources instead.
Comments of last round
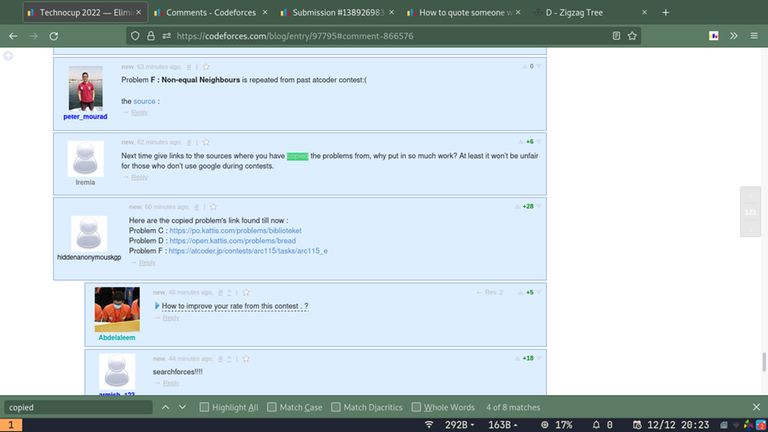
Although a contest shouldn't have already used problems, please convince yourself that no problemsetter would copy problems deliberately. The presence of some problems from the Internet is accidental. So, it's not correct to accuse the authors to "copy" the problems.
FAQ:
Q. The statement is completely the same, isn't it obvious that the problem was copied?
A. No. Proof: I invented 844C - Sorting by Subsequences and 1088D - Ehab and another another xor problem, with the same statement. Usually, if you want to write the statement formally, there is only one way that's much more convenient to use that the others.
Q. Maybe you remembered the statement because you had already read it without solving the problem?
A. No. Proof: I invented 1501C - Going Home and arc130_d before the contest.
Q. How is it possible that no author / tester was able to find the "copied" problem by googling?
A. Challenge: find arc115_e on Google, using only the statement of 1591F - Non-equal Neighbours.
Hello everyone,
this blog is similar to 90744, but it's specifically about implementation.
Although practicing for around 2 years, I'm still very slow in implementation. For example, during olympiads I usually spend ~ 70% of the time writing the code, so I don't have much time to think.
In fact,
- during CEOI 2021 Mirror (Day 2) I spent a lot of time writing ~ 220 lines of code for problem C (the logic of that solution was wrong, but that's another story)
- I've just solved CEOI 2016/1 (submission), but my solution is 239 lines long.
- I don't perform well on DMOJ (my contests: 1, 2, 3)
- I spent 1:30 hours implementing 101597A, although my final code is only 81 lines long.
How to improve? Should I learn new C++ features? Should I start implementing something significantly longer than competitive programming problems?
Hello everyone,
problems about swapping adjacent elements are quite frequent in CP, but they can be tedious. In this tutorial we will see some easy ideas and use them to solve some problems of increasing difficulty. I tried to put a lot of examples to make the understanding easier.
The first part of the tutorial is quite basic, so feel free to skip it and jump to the problems if you already know the concepts.
Target: rating $$$[1400, 2100]$$$ on CF
Prerequisites: greedy, Fenwick tree (or segment tree)
Counting inversions
Let's start from a simple problem.
You are given a permutation $$$a$$$ of length $$$n$$$. In one move, you can swap two elements in adjacent positions. What's the minimum number of moves required to sort the array?
Claim
The result $$$k$$$ is equal to the number of inversions, i.e. the pairs $$$(i, j)$$$ ($$$1 \leq i < j \leq n$$$) such that $$$a_i > a_j$$$.
Proof 1
Let $$$f(x)$$$ be the number of inversions after $$$x$$$ moves.
In one move, if you swap the values on positions $$$i, i + 1$$$, $$$f(x)$$$ either increases by $$$1$$$ or decreases by $$$1$$$. This is because the only pair $$$(a_i, a_j)$$$ whose relative order changed is $$$(a_i, a_{i+1})$$$. Since the sorted array has $$$0$$$ inversions, you need at least $$$k$$$ moves to sort the array.
For example, if you have the permutation $$$[2, 3, 7, 8, 6, 9, 1, 4, 5]$$$ ($$$16$$$ inversions) and you swap two adjacent elements such that $$$a_i > a_{i+1}$$$ (getting, for example, $$$[2, 3, 7, 6, 8, 9, 1, 4, 5]$$$), the resulting array has $$$15$$$ inversions, and if you swap two adjacent elements such that $$$a_i < a_{i+1}$$$ (getting, for example, $$$[3, 2, 7, 8, 6, 9, 1, 4, 5]$$$), the resulting array has $$$17$$$ inversions.
On the other hand, if the array is not sorted you can always find an $$$i$$$ such that $$$a_i > a_{i+1}$$$, so you can sort the array in $$$k$$$ moves.
Proof 2
For each $$$x$$$, let $$$f(x)$$$ be the number of inversions if you consider only the elements from $$$1$$$ to $$$x$$$ in the permutation.
First, let's put $$$x$$$ at the end of the permutation: this requires $$$x - \text{pos}(x)$$$ moves. That's optimal (the actual proof is similar to Proof 1; in an intuitive way, if you put the last element to the end of the array, it doesn't interfere anymore with the other swaps).
For example, if you have the permutation $$$[2, 3, 7, 8, 6, 9, 1, 4, 5]$$$ and you move the $$$9$$$ to the end, you get $$$[2, 3, 7, 8, 6, 1, 4, 5, 9]$$$ and now you need to sort $$$[2, 3, 7, 8, 6, 1, 4, 5]$$$. Hence, $$$f(x) = f(x-1) + x - \text{pos}(x)$$$. For each $$$x$$$, $$$x - \text{pos}(x)$$$ is actually the number of pairs $$$(i, j)$$$ ($$$1 \leq i < j \leq x$$$) such that $$$x = a_i > a_j$$$. So $$$f(x)$$$ is equal to the number of inversions.
Counting inversions in $$$O(n \log n)$$$
You can use a Fenwick tree (or a segment tree). There are other solutions (for example, using divide & conquer + merge sort), but they are usually harder to generalize.
For each $$$j$$$, calculate the number of $$$i < j$$$ such that $$$a_i > a_j$$$.
The Fenwick tree should contain the frequency of each value in $$$[1, n]$$$ in the prefix $$$[1, j - 1]$$$ of the array.
So, for each $$$j$$$, the queries look like
- $$$res := res + \text{range_sum}(a_j + 1, n)$$$
- add $$$1$$$ in the position $$$a_j$$$ of the Fenwick tree
Observations / slight variations of the problem
By using a Fenwick tree, you are actually calculating the number of inversions for each prefix of the array.
You can calculate the number of swaps required to sort an array (not necessarily a permutation, but for now let's assume that its elements are distinct) by compressing the values of the array. For example, the array $$$[13, 18, 34, 38, 28, 41, 5, 29, 30]$$$ becomes $$$[2, 3, 7, 8, 6, 9, 1, 4, 5]$$$.
You can also calculate the number of swaps required to get an array $$$b$$$ (for now let's assume that its elements are distinct) starting from $$$a$$$, by renaming the values. For example,
$$$a = [2, 3, 7, 8, 6, 9, 1, 4, 5], b = [9, 8, 5, 2, 1, 4, 7, 3, 6]$$$
is equivalent to
$$$a = [4, 8, 7, 2, 9, 1, 5, 6, 3], b = [1, 2, 3, 4, 5, 6, 7, 8, 9]$$$
$$$a^{-1}$$$ (a permutation such that $$$(a^{-1})_{a_x} = x$$$, i.e. $$$(a^{-1})_x$$$ is equal to the position of $$$x$$$ in $$$a$$$) has the same number of inversions as $$$a$$$. For example, $$$[2, 3, 7, 8, 6, 9, 1, 4, 5]$$$ and $$$[7, 1, 2, 8, 9, 5, 3, 4, 6]$$$ have both $$$16$$$ inversions. Sketch of a proof: note that, when you swap two elements in adjacent positions in $$$a$$$, you are swapping two adjacent values in $$$a^{-1}$$$, and the number of inversions in $$$a^{-1}$$$ also increases by $$$1$$$ or decreases by $$$1$$$ (like in Proof 1).
1430E - String Reversal (rating: 1900)
Hint 1
Hint 2
Hint 3
Solution
103148B - Luna Likes Love (EGOI 2021/2)
Hint 1
Hint 2
Hint 3
Hint 4
Solution
arc088_e (rating: 2231)
Hint 1
Hint 2
Hint 3
Hint 4
Solution
arc097_e (rating: 2247)
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Other problems
IOI 2019/1
arc120_c (suggested by Ghassane)
Hackerearth — Swapping numbers (Inferno03)
Hackerearth — Make the strings equal (Inferno03)
1526D - Kill Anton (somil_jain_120)
JOI 2021/3 (Final Round) (you can submit here)
Conclusions
We've seen that a lot of problems where you have to swap adjacent elements can be tackled with greedy observations, such as looking at the optimal relative positions of the values in the final array; then, a lot of these problems can be reduced to "find the number of inversions" or similar.
Of course, suggestions/corrections are welcome. In particular, please share in the comments other problems where you have to swap adjacent elements.
I hope you enjoyed the blog!
Hello everyone,
here is a very simple idea that can be useful for (cp) number theory problems, especially those concerning multiples, divisors, $$$\text{GCD}$$$ and $$$\text{LCM}$$$.
Prerequisites: basic knowledge of number theory (divisibility, $$$\text{GCD}$$$ and $$$\text{LCM}$$$ properties, prime sieve).
Idea
Let's start from a simple problem.
You are given $$$n$$$ pairs of positive integers $$$(a_i, b_i)$$$. Let $$$m$$$ be the maximum $$$a_i$$$. For each $$$k$$$, let $$$f(k)$$$ be the sum of the $$$b_i$$$ such that $$$k | a_i$$$. Output all pairs $$$(k, f(k))$$$ such that $$$f(k) > 0$$$.
An obvious preprocessing is to calculate, for each $$$k$$$, the sum of the $$$b_i$$$ such that $$$a_i = k$$$ (let's denote it as $$$g(k)$$$). Then, there are at least $$$3$$$ solutions to the problem.
Solution 1: $$$O(m\log m)$$$
For each $$$k$$$, $$$f(k) = \sum_{i=1}^{\lfloor m/k \rfloor} g(ik)$$$. The complexity is $$$O\left(m\left(\frac{1}{1} + \frac{1}{2} + \dots + \frac{1}{m}\right)\right) = O(m\log m)$$$.
Solution 2: $$$O(n\sqrt m)$$$
There are at most $$$n$$$ nonzero values of $$$g(k)$$$. For each one of them, find the divisors of $$$k$$$ in $$$O(\sqrt k)$$$ and, for each divisor $$$i$$$, let $$$f(i) := f(i) + g(k)$$$.
If $$$m$$$ is large, you may need to use a map to store the values of $$$f(k)$$$ but, as there are $$$O(n\sqrt[3] m)$$$ nonzero values of $$$f(k)$$$, the updates have a complexity of $$$O(n\sqrt[3] m \log(nm)) < O(n\sqrt m)$$$.
Solution 3: $$$O(m + n\sqrt[3] m)$$$
Build a linear prime sieve in $$$[1, m]$$$. For each nonzero value of $$$g(k)$$$, find the prime factors of $$$k$$$ using the sieve, then generate the divisors using a recursive function that finds the Cartesian product of the prime factors. Then, calculate the values of $$$f(k)$$$ like in solution 2.
Depending on the values of $$$n$$$ and $$$m$$$, one of these solutions can be more efficient than the others.
Even if the provided problem seems very specific, the ideas required to solve that task can be generalized to solve a lot of other problems.
1154G - Minimum Possible LCM
Hint 1
Hint 2
Hint 3
Solution
agc038_c - LCMs
Hint 1
Hint 2
Hint 3
Solution
abc191_f - GCD or MIN
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Other problems
1493D - GCD of an Array (suggested by nor)
1436F - Sum Over Subsets (nor)
Codechef — Chefsums (nor)
Conclusions
We've seen that this technique is very flexible. You can choose the complexity on the basis of the constraints, and $$$f(k)$$$ can be anything that can be updated fast.
Of course, suggestions/corrections are welcome. In particular, please share in the comments other problems that can be solved with this technique.
I hope you enjoyed the blog!
Author: TheScrasse
Preparation: MyK_00L
Hint 1
Hint 2
Hint 3
Solution
Official solution: 107232596
1485B - Replace and Keep Sorted
Author: TheScrasse
Preparation: Kaey
Hint 1
Hint 2
Hint 3
Hint 4
Solution
Official solution: 107232462
Authors: isaf27, TheScrasse
Preparation: Kaey
Hint 1
Hint 2
Solution
Official solution: 107232416
1485D - Multiples and Power Differences
Author: TheScrasse
Preparation: MyK_00L
Hint 1
Hint 2
Hint 3
Solution
Official solution: 107232359
Author: TheScrasse
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Solution
Official solution: 107232216
Author: TheScrasse
Preparation: TheScrasse
Hint 1
Hint 2
Hint 3
Solution
Official solution: 107232144
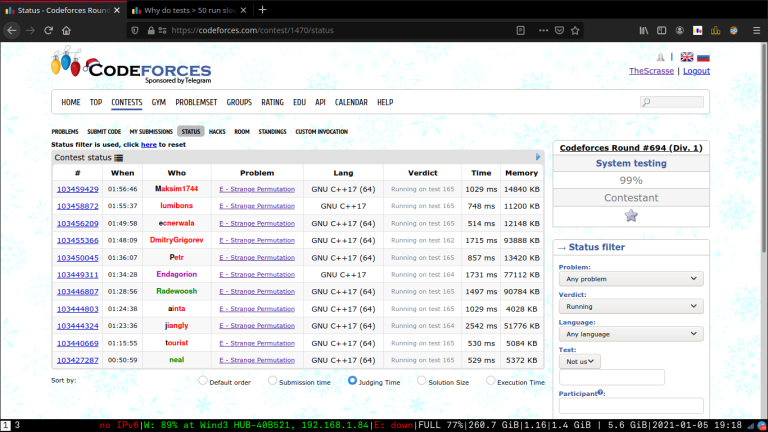
It's quite weird that $$$11$$$ submissions are still running from at least $$$20$$$ minutes, while hundreds of submissions (even with long execution times) are usually evaluated in a few seconds. It seems that the last tests run much more slowly than the other tests. Does anyone know why it happens?
Image
As promised, here are some (nested) hints for Codeforces Round #682 (Div. 2).
1438A - Specific Tastes of Andre
Hint 1
1438B - Valerii Against Everyone
Hint 1
Hint 1
Hint 1
I wasn't able to solve E and F. If you did, you may want to add your hints in the comments.
Also, please send a feedback if the hints are unclear or if they spoil the solution too much.
Hi everyone,
many people are a bit disappointed because, for example, while the most difficult problems of Div. 3 contests are still interesting for Div. 2, Div. 3 contests are unrated for higher divisions. The same argument is valid for Div. 2 and Div. 4 contests.
An idea could be make contests rated for everyone, but that's not the best solution because, to reach a $$$\geq 1900$$$ rating, solving Div. 3 and Div. 4 problems very fast would be enough.
An improvement could be make contests partially rated for higher divisions, that is, the rating variation is multiplied by a $$$k$$$ factor ($$$0 \leq k \leq 1$$$) that depends on the target division of the contest and on the initial rating of the contestant (i. e. the relevance of that contest for that contestant). An example: there's a Div. 2 contest, then $$$k$$$ could be $$$1$$$ for a $$$1900$$$ rated contestant, $$$0.8$$$ for a $$$2100$$$ rated contestant, $$$0.5$$$ for a $$$2200$$$ rated contestant, etc.
Hi everyone, I have just tried to solve the problem 161D.
If I use a matrix dp[50010][510], I get a tle verdict, even if the time complexity of the solution is $$$O(nk)$$$, $$$nk < 10^8$$$ and the constant factors are quite small. But if I use a matrix dp[510][50010] and I swap the indices, I get ac with a time of 498 ms (much less than the time limit).
Why does it happen?
Thanks
Submission with tle verdict: 73781168
Submission with ac verdict: 73781989
Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Feb/23/2025 00:15:19 (k2).
Desktop version, switch to mobile version.
Supported by
