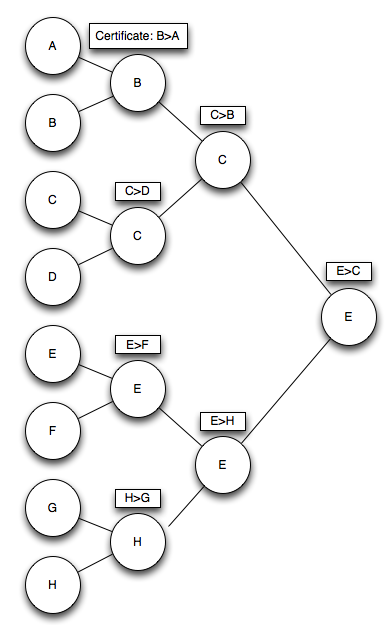
Hi everyone, my team participated in ICPC World Finals yesterday and had a lot of fun. However, we noticed that Problem N did not have many solves (only 1 in-contest and none on Kattis), even though our team thought the problem was very fun and doable. Probably, the reason was because numerical algorithms are harder to write in competitive programming languages like C++ and Java.
To help explain the solution better, I made a very concise, annotated Julia notebook that solves the problem in only 16 lines of code. Hopefully you find it conceptually interesting and helpful.
Here is the link to the notebook as a PDF. Alternatively, if you have Julia and Pluto.jl installed, you can run the notebook directly from the source .jl file at this GitHub Gist.
Here's also the Julia code as a standalone program, if you would like to run it on AtCoder or another place. I compressed this program slightly more, so it is only 13 lines of code, including imports and code to read input: