


Motivation problem
We aim to solve this problem: Path Queries 2.
Summary: Given a tree with weighted nodes, you are asked to answer the following type of queries: What is the maximum value on the path connecting nodes A and B ?
Definitions
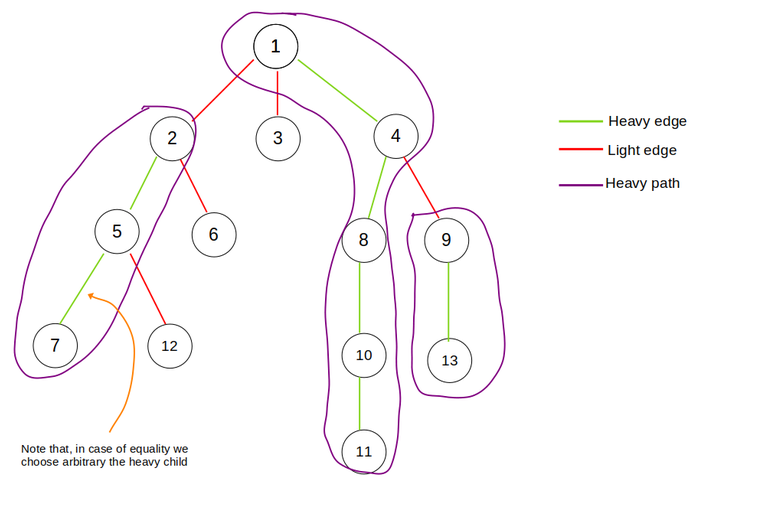
- A heavy child of a node is the child with the largest subtree size rooted at the child
- A heavy edge connects a node to its heavy child
- A light child of a node is a child that it's not heavy
- A light edge connects a node with a light child
- A heavy path is a path made of heavy edges
How it works
The main idea is to make use of the heavy paths in answering the queries, so we divide the path in heavy paths contained by it and then we add those heavy paths in a Segment Tree to support maximum-value query.
- Any path from node $$$u$$$ to node $$$v$$$ passes through at most $$$O(log N)$$$ light edges.
1. The first step is to compute every node's subtree size in order to find out the heavy edges.
2. Then we mark the heavy paths and add the nodes in the segment tree. Each heavy-path's nodes form a continuous sequence in the segment tree in order to support queries on a specific heavy-path. As you can see in the image below heavy path's nodes form a contiguous sequence of numbers:
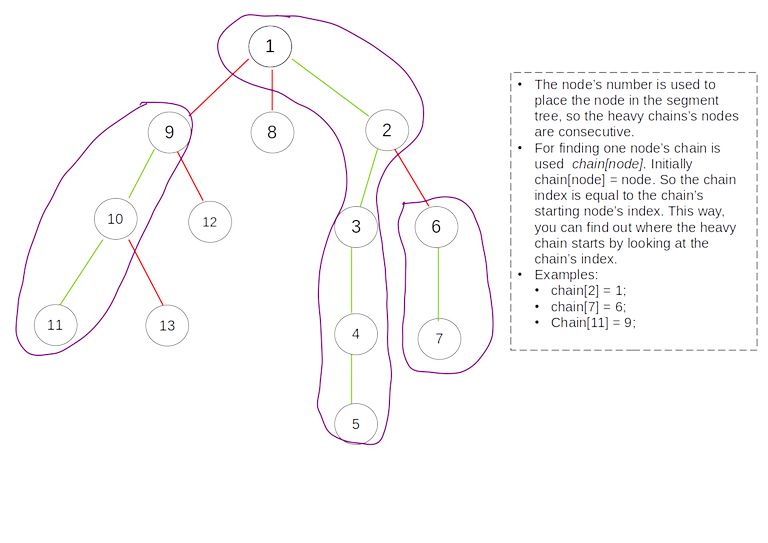
3. The final step is to build the segment tree.
Answering queries
Answering queries can become much easier by dividing the path from node $$$u$$$ to node $$$v$$$ into 2 vertical chains:
- the chain from $$$u$$$ to $$$LCA(u, v)$$$
- the chain from $$$v$$$ to $$$LCA(u, v)$$$
To get the answer for the path combine the 2 answers. Now, answering the query for a vertical chain is pretty much straight forward: Jump through each heavy path contained by the chain and query it using the segment tree. You can think it as binary jumping. Once in the heavy chain, query it, jump to parent of chain's starting node and repeat. 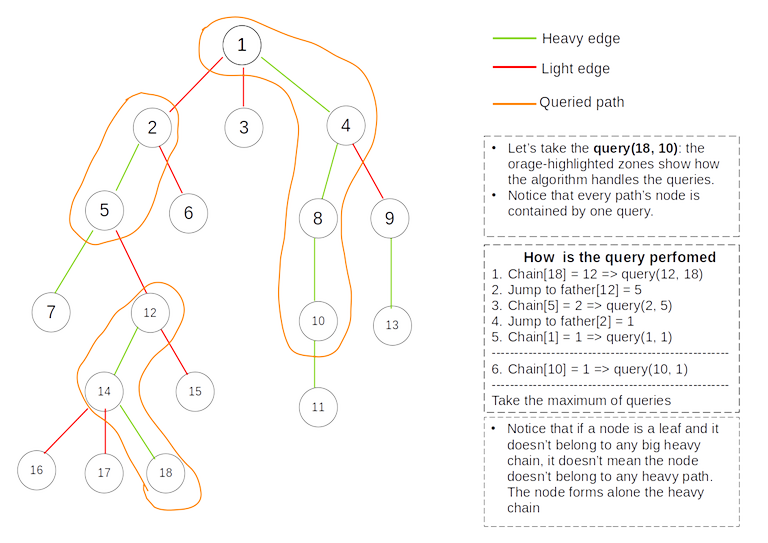
Source code
you can find the hole code here.







You can do it faster (in $$$O(n \log n)$$$ rather than $$$O(n \log^2 n)$$$) by using a sparse table rather than a segment tree. Binary lifting also suffices for this problem.
Can you please go into more details? I don't see how binary lifting would work using a sparse table since you cannot easily update a sparse table (note that the problem linked at the beginning of the article also has updates).
My bad, I didn't open the linked problem (and the post doesn't seem to explicitly talk about updates either).
The binary lifting and the sparse table ideas are separate. For the version without queries, both work. In the sparse table approach, you compute a sparse table instead of a segment tree. In the binary lifting approach, along with the $$$2^i$$$-th ancestor, you also maintain the max element along the path from the vertex to that ancestor.
However, you can still use a global BST to reduce the original problem's complexity down to $$$O((n + q) \log n)$$$, for instance, see this (shoutout to errorgorn for writing the first accessible non-Chinese introduction to the topic).
Even when I got purple, I didn't need to know what HLD was. Bro, you should learn how to use binary search.
Stop posting with alt accounts. Please.
Stop posting with alt accounts. Please.
Marinush
Stop posting with alt accounts. Please.
My next problem will be hld with seg tree beats on centroid decomposition of virtual trees from bridge tree.
Tread lightly, tibinyte
Dont take me wrong but as a newbie you should not touch complex data structures or techniques. You can atmax learn Greedy, DP, BinarySearch ,NumberTheory, Stack, Queue, Graph Theory, Segment Trees, Two Pointers These should be sufficient to get until Div2C.
Don't take me wrong, but I don't remember asking.
I stumbled across this problem when I was solving timus (as somebody very clever once proposed). At the time I knew nothing about HLD and solved it using sqrt-decomposition in $$$O(q \cdot sqrt(n \cdot log(n)))$$$.
We are going to use binary lifting in order to find $$$anc = LCA(u, v)$$$. When calculating the lifts we will also store maximum value of nodes on that lift. So, $$$lifts_{i,j} = (anc, max)$$$ — to what node $$$anc$$$ will we arrive and what maximum $$$max$$$ on this path is, if we lift $$$2^i$$$ edges up, starting from node $$$j$$$.
But what about the updates? Let's store information about the last $$$k$$$ updates and when their number exceeds $$$k$$$, we rebuild the lifts and update values in each vertex. When answering a query $$$maximum$$$ $$$on$$$ $$$path(u, v)$$$, for each stored update we will check if the updated node $$$m$$$ lies on either path $$$u$$$ -> $$$LCA(u, v)$$$ or $$$v$$$ -> $$$LCA(u, v)$$$. Each of those checks should take us only $$$O(1)$$$ if we precalculate times when we get in and out for each of the vertices traversing from the root. This results in $$$O(\frac{q}{k} \cdot n \cdot log(n))$$$ for lifts recalculation and in $$$O(q \cdot k)$$$ for query answering.
What group size $$$k$$$ should we use? Let's find minimum for this function of $$$k$$$:
$$$f(k) = \frac{q}{k} \cdot n \cdot log(n) + q \cdot k$$$ -> $$$min$$$
$$$f'(k) = q - \frac{q}{k^2} \cdot n \cdot log(n) = 0 $$$ (found the derivative $$$\frac{d(f(k))}{dk}$$$)
$$$k^2 = n \cdot log(n)$$$
$$$k = sqrt(n \cdot log(n))$$$
P.S. I calculated the lifts lazily and used memset for resetting them.
I agree that this problem is way above gray (and blue) level. That is why I stopped solving timus and moved to codeforces archive.
Bruh aren't you the guy who put two problems on the local OJ without tests so everyone can only read the misspelled statement but cannot submit lmfao