


Hi everyone! I think many of you know about such data type as set. It must support such operations like:
- Insert an element into set;
- Check if the set contain some element;
- Delete element from set.
If we talk about ordered set, then elements (what a surprise!) must be kept in some order. As I think, there is also very important next operations:
- Find the k-th element in a set;
- Find the order of element in a set.
Most of all, for the implementation of such functional some may use binary balanced trees (AVL- tree , red-black tree , cartesian tree , etc). However, in this article I would like to talk about some of the features in the implementation of an ordered set with other structures. In particular, I'll show the implementation with the segment tree and with the Binary Indexed Tree (Fenwick tree). But I just want to note that it only allows you to build the set of natural numbers. For all other types of elements such methods will not work :(
The basic idea:
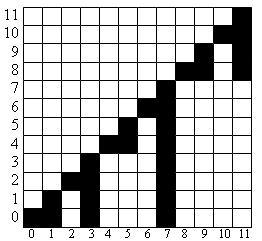 Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element x in the set is the same as increment of arr[x]. Deleting of element is the same as decrement of arr[x]. To check if the set contains element we should check if arr[x]>0, i.e. sum(x, x) > 0. We should also mention the operation of finding K-th element. To do this we will have to use the technique of binary expansion. In the segment tree we should store the sizes of the subtrees, like in BST, and in binary indexed tree we can watch to the following image showing the distribution of elements in tree and derive an algorithm:
Let the index of cell in the array be the value of element in the set and let the value in the cell be the amount of element in cell. Then we can easily do all required operations in the logarithmic time. Really, the insertion of element x in the set is the same as increment of arr[x]. Deleting of element is the same as decrement of arr[x]. To check if the set contains element we should check if arr[x]>0, i.e. sum(x, x) > 0. We should also mention the operation of finding K-th element. To do this we will have to use the technique of binary expansion. In the segment tree we should store the sizes of the subtrees, like in BST, and in binary indexed tree we can watch to the following image showing the distribution of elements in tree and derive an algorithm:
int get(int x)
{
int sum=0;
int ret=0; // Number of element in array, for which the sum is equal to sum
for(int i=1<<MPOW;i && ret+(i-1)<N;i>>=1) // Loop through the powers of two, starting with the highest possible
{
if(sum+arr[ret+(i-1)]<x) // Trying to expand the current prefix
sum+=arr[ret+(i-1)],
ret+=i;
}
return ret;
}
Easy to see that while using this approach ret always has a value such that the next time a number from the interval [0; ret] will be met not earlier than at ret + i, however, due to decreasing of i, we will never reach this point, and therefore, none of the elements in the prefix will be counted twice. This gives us the right to believe that the algorithm is correct. And the check on some problems confirms it :)
The basic idea is presented, for now let's talk about the advantages and disadvantages of this approach.
Pros:
- We can write it really fast;
- Intuintive (especially in the case of the segment tree);
- Works fast (in practice often overtakes BST);
Contras:
- Limited functionality (supports only integers in the set);
- In its simplest form takes O(C) memory, where C — the maximum possible number in the set;
The second drawback is VERY essential. Fortunately, it can be eliminated. You can do this in two ways.
- Compression of coordinates. If we can solve the problem in an offline, we read all queries and learn all possible numbers, which we will have to handle. Then we sort them, and associate smallest element with one, the second smallest — with two, etc. This reduces memory complexity to O(M), where M is the number of queries. However, unfortunately, it does not always work.
- Dynamic growth of the tree. The method is not to store int the tree the vertices, which we do not need. There are at least three ways to do this. Unfortunately, for binary indexed tree there is only one of them is suitable. The first option — to use a hash map. Bad, very bad option. More precisely, with the asymptotic point of view it is good, but the hash map have very large constant, so I do not recommend this method. Unfortunately, it is that only way that we can use in BIT :) . The second option — extension with pointers. When we need a new tree vertex, we simply create it. Cheap and cheerful. However , it is still not the fastest option. The third option — statically allocate a block of MlogC vertices, and then for each vertex store the indexes of its children (as in trie). In practice, it is the fastest way. Memory complexity is the same in all three methods and is reduced to O(MlogC), which are generally acceptable.
I hope that I was interesting/useful to someone. Good luck and have fun! :)
P.S. Sorry for my poor English. Again ;)







Интересным фактом является то, что размер такого множества и скорость работы с ним, вообще говоря, не зависит от количества элементов в нём. Таким образом, в принципе мы можем за логарифм творить такие безобразия, как, например, добавление в множество по миллиарду каждого из чисел, находящихся в диапазоне [123;1234567890].
Я плохо знаком с BST, однако интересно, как к таким вещам относятся они? Это вообще реализуемо?
=============================================================
An interesting fact is that time and memory complexity of work with such set, generally speaking, does not depend on the number of items in it. Thus, we can do such outrages like the addition in a set a billion of each number in range [123; 1234567890].
I'm new to the BST, but it's interesting, can them do something like this? Is it achievable?
Create some problem, which is easy to solve using this structure and see how many people will solve it with BSTs ;)
Thanks, I read your blogs about Policy Based DS and this one , they are really helpful.
Sorry, I couldn't understand this part "statically allocate a block of MlogC vertices, and then for each vertex store the indexes of its children (as in trie). In practice, it is the fastest way. Memory complexity is the same in all three methods and is reduced to O(MlogC), which are generally acceptable."
can you elaborate it more ?
also maybe it is good to add a node under picture that it is covered numbers for each indexes when fenwick tree base is 0 ( it took me time to figure it out )