


As usual, content here: https://nor-blog.codeberg.page/posts/2024-07-28-thoughts-on-the-present-and-future-of-ai-and-problem-solving/. Consider subscribing to the RSS feeds for more posts!
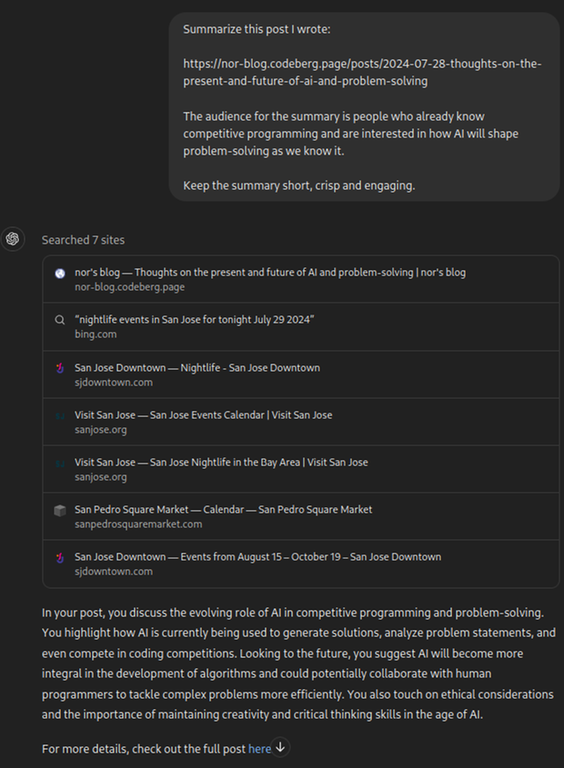
Bloopers: while I was trying to make the point that AI is good for basic things like coming up with a TL;DR by asking ChatGPT to summarize my post, AI disappointed me yet again with the clearly wrong and generic summary (and its references, of course).
Or is it secretly sentient with a sense of humour? Read more to find out I guess...






NEAR AI is future!!!!
NEAR AI is future!
NEAR AI is future!!
I wonder if there're anyone REALLY read your blogs / essays with that long
Yes
yes
but not me
I get pretty insightful conversations (quite unlike most comments on this comments section) out of comments over email, mostly from people outside the competitive programming community. Initially I was planning to not post this on CF, but talking to some of my competitive programmer friends made me decide to write about AlphaCode in my post too, and post it here since CF has had quite a few discussions on this topic (and lots of people who misunderstand AI).
Main points from my comment in a group discord:
does lack of thinking in axiomatic logic imply lack of intelligence? i think cats for example have some level of intelligence, no where near human level, but they also cannot perform similar abstract axiom-based reasoning
from skimming, i def agree with deepmind has been elusive and overembellishing stuff lately at least but i think a big part of his cynisism is a fundamentally different believe in what qualifies as logic, and therefore what counts as a good step in simulating logic
there are a lot of statements throughout like
but more and more i believe generally human problem solving is closer to a kind of brute force than not, just with some good heuristics baked in and u hope after long enough u mash together and tweak things into something slightly new and call it original. what does nor exactly want to be satisfied a program is also performing "human-like original discovery"
i think the impressive part of alphageometry and alphaproof if it has any advantage over purely mechanical like wu's method is that we're now able to integrate small parts of non-sequential heuristics just like human problem solving. to me that means we're making big step towards human solving, but to nor it seems by itself that is non-factor
Intelligence is definitely something that can be debated upon to no end, and you might have noticed that I left off that discussion by saying that one of the major aspects of intelligence consists of being able to incorporate logic rigorously into what the model says, and being careful about adversarial/out-of-sample inputs (the latter is especially important, and animals have this part too). I did not call this constraint "human-like reasoning" here because, well, that's easily misinterpretable to be saying that the AI does reasoning like a human in its methods.
I don't say that AI must reason like a human in the sense of a Turing test. I am saying that its reasoning should hold up to the high standards we have set for it. People involved in the IMO Grand Challenge understand this, and I think it is a very reasonable constraint on a machine that claims to be AGI. At the very least, reasoning must be able to encompass all the math we have, including reasoning with different axioms and systems of logic. Of course, I don't see AI becoming the next Grothendieck yet, but there is some value in having an AI that can "understand" math in some sense, and to be able to do that, it must have a system for logic that never produces a wrong conclusion (but can produce conjectures and mark them as such).
Coming up with a new language (abstractions, logic systems and such) in math is something I hope AI is able to achieve in the future though it does not seem anywhere close now — which is a part of the reason why I suggested, as a first step, a language (something like Cur) for a proof assistant that allows you to build smaller domain specific languages for the task, because it will help the model learn better meta strategies on a higher level of abstraction (the success of abstraction is clear from stuff like category theory, software engineering and so on).
As far as the methods are concerned, one of my main suggestions was that the methods are already at their limits, and we need more directed search, somehow, to be able to deal with the super large branching factor. Considering how the attention mechanism was derived from a high-level understanding of how words fit together in a context, in a manner that was arguably human-motivated, why not use the lowest high-level heuristics to solve problems?
It might seem like patchwork — we are trying to patch the inability of proof engines to "generate" transient theorems that will help the final proof. However, my claim is that learning this is in fact half of the remaining part of reasoning that we can't capture using current methods. There are, somewhere out there, some building blocks (in the sense of fundamental nodes of a graph) — explicit or encoded in an architecture, that will allow us to construct generalized policies for traversal in order to discover more of said non-sequential heuristics better in the first place.
Purely mechanical Wu's method has been adapted with things like deductive engines (DD+AR approaches) that use databases and algebraic rules to give very human readable proofs — so it is not really the AI that brings the human heuristics. I think it's more an issue of flawed accounting on their part, that I wanted to set straight while talking about AlphaGeometry.
Guess I should point out that the chatgpt browsing function is off (fortunately I never used it). If you simply copy paste your article the summary turns out fine.
Another funny thing is that ChatGPT does support sending additional word files, but it doesn't seem to be that competent either. I told it the other day to summarize the History material that my teacher gave me (the file contains no image, no additional symbols, just pure text, mind you, so it probably doesn't require that much computation power to process), and it just spit out pure gibberish.
You mention LLMs are bad at counting and arithmetics, and you say
What kind of axioms do you mean here? It seems to me it's more of a problem of the tokenization; 'cause I have the feeling that the structure of composed attention is ideal for some arithmetics (at least with a fixed number of digits). For instance, for multiplication, let's say you have two numbers A = a0 + a1*x^1 + a2*x^2 and B = b0 + b1*x^1 + b2*x^2 (I'm assuming the coefficients of the polynomials are the tokens produced by the tokenizer).
Then, a single layer of cross attention should be able to learn the product of all pairs {a_i * b_j * x^{i+ j}} of digits, just because it naturally correlates each pair of tokens. Perhaps you'd need another layer to permute the pairs in the right positions and then the model then should be able to learn addition on the corresponding powers of x. Addition in particular has been partially studied in mechanistic interpretability (https://www.youtube.com/watch?v=OI1we2bUseI)
Obviously, even if we can simulate permutations through standard DL operations, it doesn't mean a NN can learn that with the standard training methods on lots of data. But intuitively, it seems to me they are possible to do.
Probably something on the realm of neural algorithmic reasoning (https://arxiv.org/pdf/2105.02761) is needed there.
The same for combinatorics. Many problems in combinatorics are easily modelled through some recurrence which competitive programmers call Dynamic Programming (ignoring hard GF problems or stuff with Symmetry Groups, ...). Papers like this one tackle learning classical algorithms like Bellman-Ford's (https://arxiv.org/pdf/2203.15544). This algorithm is applying arithmetics over a graph in the tropical semi-ring. It seems to me that similar ideas could be applied to other "arithmetics", moving us from optimisation problems to counting problems.
Lastly, I wonder what are your takes on the fields of Geometric Deep Learning and the more recent Categorical Deep Learning.
Thanks for the greatly detailed response! I'll try to address your concerns as much as possible.
I mean basic math axioms, like those for arithmetic. You can extend this to rules that you can derive for different operations (as in, base 10 addition for example).
This is correct. And GPTs seem to have some support for addition — with the correct embeddings that is (for example, this paper talks about these).
There are a few issues with such arguments when generalizing this to multipurpose models that claim emergent behaviour, though:
I agree. Back in 2021 when there was only GPT2, I was wondering — what if we make an LLM that emulates a Turing machine? Then in 2023, there came this paper which proved that LLMs, if given memory storage, can emulate Turing machines (the language models are admittedly brittle, by design though, and I still think this is a good direction). There are of course things here that can be improved, but that's a discussion for a later time.
That is quite similar to (but is a specialization of) my suggestions for different solver nodes for different reasoning "types" and it does seem promising. From my understanding, there is already a decent amount of headway in this direction (for instance, here, here, here and here). However, using this for doing basic arithmetic seems like an overkill, though I acknowledge that if we want that can do non-trivial arithmetic and reasoning, something more general is needed.
I think there is a clarification in order here — when I was referring to combinatorics, I was referring to it in the IMO sense, and not the CF sense. The combinatorics section in the IMO shortlist is basically a place for all the ad hocs and research problems to get dumped, and as a result, that part of the shortlist is notoriously hard for automated theorem provers.
I did not quite understand this part, can you elaborate?
Well, I was convinced in uni that graph ML will be the future, simply because it has such cool and general properties. Geometric DL uses the fact that graphs are just discretized manifolds as well as discrete structures with an absurd amount of expressive power, and ends up doing some really cool stuff with all that power, so I think it will do a lot of non-trivial things in the future. In fact, my recommendation in the blogpost was partly inspired from graph learning and partly from my blog post on learning (and later turned out to be some sort of meta RL).
As far as categorical deep learning is concerned, theoretically it looks really cool and sensible, and should greatly help in motivating high level architectures based on what properties we want them to have. However I feel that we tend to overestimate what we know about data, and it might not be the most practical for us at the moment (just as theoretical ML is lagging behind practical ML). And even though this is the approach I would like the community to take, I don't think it is the approach that will be the easiest (albeit possibly being the one towards AGI with the least detours). As an aside, UMAP is a pretty concrete application of category theory to ML stuff, and I would recommend reading it to anyone who knows category theory and is curious about its applications in ML.