


Всем привет! Может быть, эта тема уже обсуждалась, но по запросу "random" ничего похожего на Codeforces не нашел.
Предыстория. Хотели с Сашей (demon1999) изучить декартово дерево. Для инициализации приоритетов рекомендуется использовать случайные числа, чтобы высота дерева не была очень большой. Соответственно, надо эти числа как-то получить. Я совсем не разбираюсь в структурах данных, поэтому не задумывался, насколько плохо будет дереву (и будет ли), если приоритеты нескольких вершин будут одинаковыми. Поэтому на всякий случай хотелось сделать их попарно различными (чего не гарантирует простое использование rand() при создании очередной вершины). Предложил следующий, "надежный" и "проверенный" метод — создать массив из N чисел, инициализировать его числами от 0 до (N-1) соответственно, применить к нему random_shuffle — и мы получим N различных ключей в случайном порядке.
История. Саша стала сдавать задачи и на практике оказалось, что в нескольких задачах такой подход достаточно стабильно приводит к вердикту Time Limit Exceeded, в то время как простейшая инициализация pr=rand() получала Accepted. Стало очень интересно, почему так происходит, да и вообще STL не склонен быть причиной каких-либо ошибок. После несложных исследований оказалось, что (возможно, не это причина TLE, но тем не менее) random_shuffle перемешивает массив не совсем случайным образом.
Если попытаться найти реализацию алгоритма random_shuffle, то Eclipse во всплывающей подсказке предлагает следующее:
for (_RandomAccessIterator __i = __first + 1; __i != __last; ++__i) std::iter_swap(__i, __first + (std::rand() % ((__i — __first) + 1)));
То есть, каждый элемент меняется местом с другим элементом, находящимся на rand() правее него. Проблема в том, что в Windows, например, rand() возвращает число от 0 до RAND_MAX, т.е. до 32767. Получается, что при большом массиве (скажем, больше 200000, что при нынешних мощностях компьютеров обычно и бывает в задачах на деревья) элемент меняется с другим элементом, стоящим достаточно близко к нему. Далее будем считать, что у нас есть массив a[] и изначально a[i]=i. Тогда после такого random_shuffle в среднем значение элемента a[i] изменится не сильно (порядка RAND_MAX). Более того, теоретически на позиции i не будет элемента со значением больше, чем i+RAND_MAX (кроме некоторых эффектов на границах массива). Посмотрим, что получается на практике.
Пусть n=500000. Давайте посмотрим, какие числа будут в середине массива (от n/2 до n/2+10000). Числа, понятное дело, большие и различные. Для наглядности рассмотрим распределение первой цифры этих чисел. Хотелось бы, конечно, чтобы после перемешивания это распределение было близко к равномерному от 0 до 4. Например, shuffle из testlib.h работает вполне корректно:
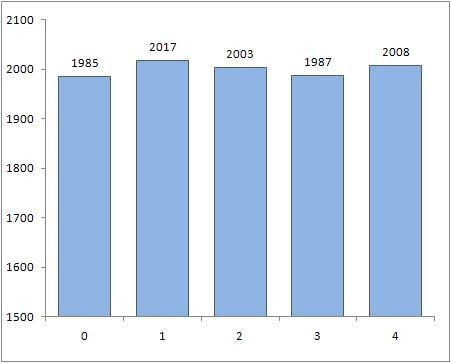
Если использовать random_shuffle, то, ожидаемо, получим совсем другое распределение:
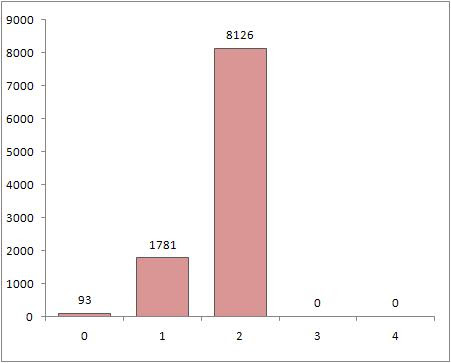
То есть у подавляющего большинства чисел, действительно, первая цифра не изменилась (осталась 2).
Как мы видим, с серединой массива уже большие проблемы. Давайте пройдемся по всему массиву и посмотрим на значение каждого тысячного элемента (все 500000 элементов тяжело на графике расположить). Опять-таки, нам хочется, чтобы значения элементов были случайно распределены от 0 до n. Вот, что дает shuffle из testlib:
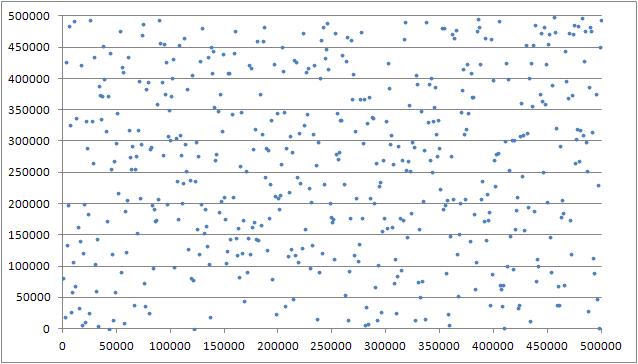
Вполне достойная случайная величина. Теперь посмотрим на аналог, созданный через random_shuffle:
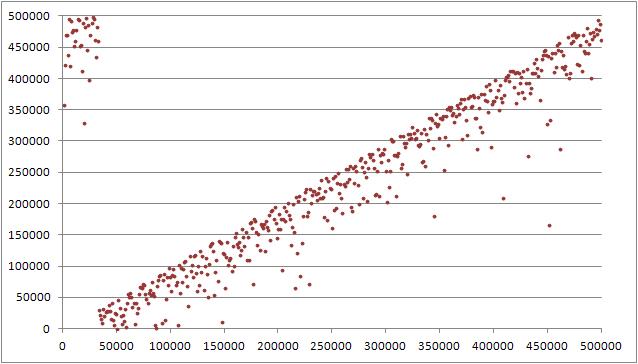
Даже при всем желании "качественным" перемешиванием это не назовешь. Ну и давайте еще найдем усредненные значения элементов (т.е мат. ожидание) на интервалах с a[i] по a[i]+10000 для всех i, делящихся на 10000. Конечно, хочется, чтобы эти значения были примерно равны n/2 (т.е. 250000) и примерно равны между собой. Вот результат для shuffle:
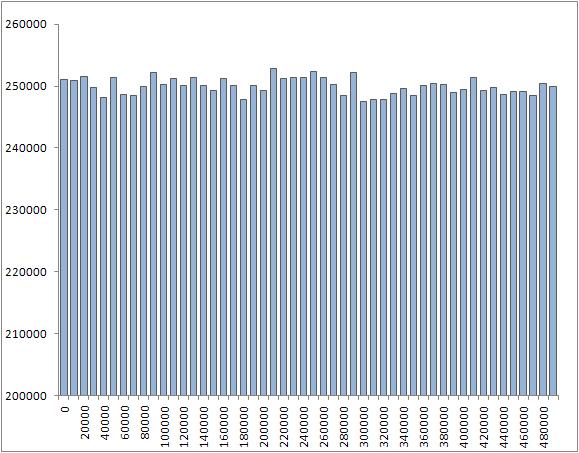
Грубо говоря, все мат. ожидания лежат в интервале 25000+-300. График для random_shuffle:

Практически линейная зависимость мат. ожидания от индекса. Соответственно, давайте, наконец, сделаем более математическое сравнение. Пусть у нас будут две случайные величины — индекс элемента массива (i) и значение элемента массива (a[i]). При случайном перемешивании эти величины должны быть независимы. Давайте посчитаем линейный коэффициент корреляции этих величин по нескольким выборкам для различных значений n (от 100000 до 2000000 с шагом 100000) — в идеале значение должно быть очень близко к 0. Вот табличка результатов для shuffle:
100000: -0.00157 0.00092 -0.00082 0.00244 -0.00089 200000: -0.00168 -0.00105 0.00036 0.00303 -0.00205 300000: 0.00082 0.00176 0.00111 0.00082 -0.00324 400000: 0.00045 0.00195 -0.00293 0.00027 -0.00001 500000: 0.00115 0.00122 -0.00129 0.00098 0.00089 600000: 0.00055 0.00100 0.00025 0.00067 0.00033 700000: -0.00009 0.00094 0.00069 0.00003 0.00061 800000: 0.00122 0.00160 0.00048 -0.00077 -0.00061 900000: -0.00052 -0.00040 0.00003 0.00027 -0.00023 1000000: -0.00049 0.00049 0.00001 0.00050 0.00126 1100000: 0.00100 -0.00129 0.00051 0.00114 0.00071 1200000: 0.00081 0.00147 -0.00026 0.00086 -0.00116 1300000: 0.00008 0.00122 -0.00045 0.00077 -0.00052 1400000: 0.00040 0.00132 -0.00048 0.00022 -0.00030 1500000: -0.00051 -0.00009 -0.00021 -0.00054 -0.00119 1600000: 0.00010 -0.00004 -0.00012 0.00028 0.00023 1700000: -0.00046 0.00024 -0.00109 0.00017 -0.00090 1800000: 0.00019 0.00052 0.00007 0.00082 -0.00039 1900000: -0.00018 -0.00122 0.00081 -0.00030 0.00008 2000000: 0.00099 0.00051 -0.00040 -0.00076 -0.00043
А вот — для random_shuffle:
100000: -0.13653 -0.13753 -0.13943 -0.13137 -0.13647 200000: 0.21258 0.21242 0.21115 0.21414 0.21200 300000: 0.42703 0.42686 0.42717 0.42612 0.42577 400000: 0.55270 0.55252 0.55290 0.55336 0.55311 500000: 0.63480 0.63479 0.63484 0.63503 0.63458 600000: 0.69161 0.69160 0.69173 0.69143 0.69172 700000: 0.73298 0.73307 0.73306 0.73300 0.73322 800000: 0.76480 0.76489 0.76484 0.76493 0.76477 900000: 0.78988 0.78995 0.78985 0.78993 0.78980 1000000: 0.81022 0.81009 0.81013 0.81010 0.81005 1100000: 0.82676 0.82678 0.82685 0.82680 0.82676 1200000: 0.84076 0.84077 0.84080 0.84076 0.84072 1300000: 0.85269 0.85272 0.85280 0.85268 0.85267 1400000: 0.86300 0.86300 0.86295 0.86293 0.86297 1500000: 0.87188 0.87186 0.87191 0.87189 0.87186 1600000: 0.87969 0.87970 0.87972 0.87971 0.87971 1700000: 0.88662 0.88664 0.88664 0.88662 0.88665 1800000: 0.89279 0.89282 0.89278 0.89282 0.89282 1900000: 0.89834 0.89835 0.89835 0.89834 0.89835 2000000: 0.90338 0.90335 0.90334 0.90335 0.90333
Как и ожидалось, у random_shuffle на большИх значениях n коэффициент корреляции приближается к 1, т.е. наблюдается практически линейная зависимость (что согласуется с графиками выше). При этом shuffle из testlib работает практически идеально, коэффициент по абсолютному значению почти всегда меньше 0.001.
Итог: при большИх значениях размера массива (или какой-либо коллекции) стандартный std::random_shuffle работает не совсем корректно. Перемешивание, близкое к "случайному", гарантируется на маленьких размерах (не больше RAND_MAX), при увеличении числа элементов, перемешивание носит локальный характер и меняет только близкие числа. Будьте внимательны и не получайте ненужных TLE!
UPD: Как предложили в комментариях ilyakor, slycelote и CountZero, в c++11 можно использовать, например, mt19937 и random_device для перемешивания функцией shuffle. На всякий случай проверил эту реализацию — "проходит" все тесты, предложенные выше, никаких проблем не наблюдается.







Good finding! As we see here, this overload of
std::random_shuffleis deprecated and this one (renamed tostd::shufflesince C++11) should be used instead:where
RandomFunccan be, for example, anstd::random_device. Have you tried it?upd: ninja'd by ilyakor