


This years last USACO contest is running!
You can participate in the contest by starting your 4-hour time block any time between April 3 and April 6.
You need to register for the http://usaco.org to be able to participate in the contest.
Contest link: http://usaco.org/index.php?page=viewcontest
Duration: 4 hours
For most problems resource limitations are as follows:
Time Limit: 2s (C/C++/Pascal), 4s (Java/Python)
Memory Limit: 256MB

P.S. I know that the title sucks, so does the grader of the interactive problem :/







great pic :D
Is it true that judges will choose the best attempt for each each problem? It'll be sad for me otherwise(
It's sad for me too :(
For Java coders: don't use threads in your solutions (you will receive strange errors).
What is the solution of "Trapped in the Haybales (Silver)" ?
When does contest officially end?
Didn't it end already?
UPD: http://www.timeanddate.com/worldclock/timezone/utc-12
The contest is still running. I will explain the solution after it ends.
BTW, when does it end?
Ok, but shouldn't it have ended by now?
I can still enter contest site.
But it doesn't let user to enter the contest.
https://www.dropbox.com/s/cayf7u8uuhpn0q6/Untitled.tiff?dl=0
How did you solve silver 3? Although I am not in silver, my friend told me it.
Are we sure that it is over?
On second thought, there may still be people in the contest, so don't answer my question.
cadenza I suppose that you are gold,right?
Is it over now because it is showing "Contest is Running!" but it should be over?
It's over.
My solutions for the silver division:
Problem 1 — Bessie Goes Moo
Problem statement: http://pastebin.com/D6yGGkT8
We want (B+E+S+S+I+E) * (G+O+E+S) * (M+O+O) to be divisible by 7. We can say that 7 will divide at lease one of the three multiples since 7 is prime. Then let's assign to each letter a remainder when we divide it by 7 and check if at least one of the three multiples is divisible by 7. If yes, then add to the answer the number of different possible values for each letter giving the assigned remainder.
Implementation: http://ideone.com/WjQx5X
Problem 2 — Trapped in the Haybales
Problem statement: http://pastebin.com/nkNB9RCP
In my opinion this was the hardest and the most interesting problem. The first thing that we should observe is that if after adding K units of size it is impossible for Bessie to escape, then after adding L (L>=K) units of size it will be impossible for Bessie to escape too. And if it is impossible to hold Bessie trapped in the haybales after adding K units of size, then it will be impossible to hold Bessie trapped in the haybales after adding L (L<=k) units of size too.
That means that the answer is monotonic so we can use binary search to fix the answer. How do we check whether K is possible answer? A naive method is to add K to every single haybale and check if Bessie can escape. The complexity of the solution is O(N * N * log(MAXIMUM_SIZE_TO_ADD)) which is not fast enough and works for 6 out of 14 test cases.
Let's divide the bales in two groups — left (those which are on Bessie's left) and right (those which are on Bessie's right). Now, let's represent each haybale in the left group as a segment (Position; Position + Size) and let's represent each haybale in the right group as a segment (Position — Size; Position). Now we can say that Bessie can break through a bale if and only if she can reach a position which is outside the segment corresponding to the bale. That is, to hold Bessie trapped in tha haybales we need two segments l(a;b) from the left group and r(c;d) from the right group such that c<=a and a<=d<=b. Let's say that the current candidate from the binary search is K. Loop over the segments from the left group and let's say that the current segment is l(a;b). Adding K units of size means extending the segment to l'(a;b+K). If we have sorted the segments from the right group in increasing order of their second coordinate("right-end" coordinate) using binary search we can find an interval (i,j) such that i is minimum, j is maximum, a<=r[i].second and r[j].second<=b+K. Now from those interval we want to take the segment with the least first coordinate (We can use RMQ or a segment tree). Say that this coordinate is p. If p<=a, then Bessie cannot escape after adding K units of size. Now we should do the same but this time we will extend the segments from the right group from r(a;b) to r'(a-K;b) which can be done similarly. The total complexity is O(N * log(N) * log(MAXIMUM_SIZE_TO_ADD)) which should pass all tests.
Implementation: During the contest I came up with this solution. I implemented it and it resulted into 350 lines of code with a bug(or maybe more than one). It was 40 seconds to the end, I changed a single line in my code and it produced the correct answer for the sample. I submitted it and it turned out to have another bug and now I have 0 instead of 6 out of 14 on this problem. So I don't have a correct implementation of this algorithm.
Problem 3 — Bessie's Birthday Buffet
Problem statement: http://pastebin.com/EE1iz72Z
Let's precalculate the minimum distances for each pair of patches. "once she eats grass of a certain quality, she’ll never eat grass at or below that quality level again" means that the sequence of the qualities of the eaten grass forms a strictly increasing sequence. Let dp[i] be the maximum energy that Bessie can gain if the last grass she has eaten is from the i-th patch. To calculate a state, loop over the next patch to be eaten and if its quality is better than the current's you can choose it as the next patch and go to it following the minimum path between them.
Implementation: http://ideone.com/6pMXeh
I believe number 3 can also be easily solved using SCC condensation and LIS dp.
Doesn't the graph have no cycles? Therefore we don't need SCC condensation.
Can you explain such solution, please?
It is the same solution as yours. We create a directed graph such that an edge exists from node u to node v if the value of v is greater than the value of u, and the weight of that edge is the weight of the minimum path from u to v in the original graph. After that, it is just dp on Directed Acyclic Graph. My friend and I couldn't solve this problem because we thought you could pick up two of the same value in a row lol.
Yeah, it's the same. But that SCC makes me think that there is another solution.
I think my algorithms on the second and third tasks a little easier. At least for me.
Problem 2 — Trapped in the Haybales
Let L be the rightmost hay bale left Bessie and R be the leftmost hay bale right Bessie. Let's start to break hay bale one-by-one. At start Bessie can move inside interval p[L]..p[R]. If we can break L's or R's hay bale then we do it and move on to the next iteration. At every step we reduce the number of unbroken hay bale per unit so total complexity will be O(N).
Problem 3 — Bessie's Birthday Buffet
Firstable we can calculate d[i][j]-minimum distance from i to j. Now iterate lawns in order in increasing order of grass quality and just count simple dynamic : dp[to]=max(dp[to],dp[v]+q[to]-d[v][to]*e) for q[v]<q[to].
About the second problem — when will we add the extra hay?
I thought about a greedy algorithm exactly like this, I wrote it and it turned out to be wrong even for the sample. Since we can break through the hay bales at coordinates 4 and 8 — let's do it. Now, we can break through the hay bale at coordinate 15 so let's do it. Now we can't break through the rightmost hay bale but we can break through the leftmost one. So we need to add 10 units of size to it which is not the optimal answer.
Did you submit this? Did I understand exactly what you mean, what do you think?
Oh, sorry, I explain another task or rather just a part of the problem...
My solution was divided into two parts :
1. we add extra hay left of Bessie
2. we add extra hay right of Bessie
These parts are symmetric, so answer will be minimum answer for them.
Key observation : if we can reach hay bale X>Bessie without breaking a pack Y<Bessie, then we can reach X without breaking Y-1 pack.
Let's check hay where we will add weight from left to right and maintain rghtmost hay that we can reach without breaking i'th pack(let it be RM). When we move from i to i-1 we have to count rightmost unbroken pack. Our goal is to Bessie could not knock down or i'th and RM'th packs at the same time and this is done in the case of w[i]+extra_weight>p[RM]-p[i].
Yes, I submit my solution and I have the perfect score in siver division and two task in gold(that's why the thought in my head about the problems mixed, in gold, too, was a problem about Bessie and haystacks, only slightly different).
If you have some extra questions-write in a personal.
And sorry for my super-bad english:D
Did anyone else feel that the gold problems were arranged in decreasing order of difficulty?
Can you share them with us, please?
I don't have problem statements.
Problem 1: This one is probably easier than I think. In every test case there is a binary tree of N nodes numbered from 1 to N in a random order, except that node 1 is always the root (1 <= N <= 10^100). For every node, the size of its left subtree is either equal to or 1 greater than the size of its right subtree. You are allowed to output an integer i, where the grader will then provide the numbers of the left child and the right child of i as input. Find the value of N with up to 70000 queries.
After drawing trees for increasing values of N, I made some observations as N increases: - every value of N corresponds with an unique tree structure - A level in the tree has to be completely filled in order to start a new level - the nodes in a level are added in a certain pattern that is hard to describe First keep querying left to find the height of the tree. Every level except the last is guaranteed to be filled, so all we need to do is figure out how many nodes are in the last level. Since the nodes are always added in a certain pattern as N increases, we can use around log(N) queries to figure out which step of the pattern we are currently in. Each of these queries will require you to query log(N) times all the way down the tree, for a total of log(N)log(N) queries.
I didn't finish implementing this during contest. I have problems with printing out numbers as big as 10^100 alone :(
Problem 2: Given a N by N grid of characters, find the number of paths from the top left cell to the bottom right cell only moving down or right such that the characters traveled on the path combine to form a palindrome.
define dp(a, b) to be the number of paths from cell a to cell b that are a palindrome (a is above and to the left of b). There are four transitions: cell a can move down or right while cell b can move up or left, and add these up. Our answer is dp(top left cell, bottom right cell). There is a better way to do this problem, because I only got 9/12 test cases.
Problem 3: Similar to silver 2, but you are given the haystacks and you need to output the combined length of all possible starting positions where you cannot escape.
I got full points on this one, but my algorithm will probably time out on a worst case scenario, so there is probably a better solution than mine.
As regards solution to the 1.
You are doing dp on tree -> you process the vertices on the path from the most left node in the tree to the root. When you are processing node x, you have the size of the left subtree and the path to the uniquely defined node which can be removed to keep balance (there is exactly one such node for each tree), let's call it y.
Then you check the right subtree — if the path to y is present, it means that the right subtree is the same as the left and you set the path to y in the right subtree as y' — the node that can be removed for the tree rooted in x.
Otherwise the right subtree is smaller (without y) and y' for the whole tree remains the same (in the left subtree).
Edit: This solution works in O((logN)^2) and O(logN) memory.
For problem 1, suppose level k is the last level. The last level could potentially have up to 2^k nodes, so label them from 0 to 2^k-1, where 0 would be the first node inserted, 1 is the second node, and so on. To find the position of node i, take the binary representation of i (padded with zeroes so that its length is k) and reverse it. Follow it down the tree, where 0 is left and 1 is right. This way we can test whether a node exists, so then we can use binary search to determine the size of the last level. log^2(N) queries is actually too many, so we also have to store the tree as we query.
For problem 3, I didn't get it during the contest but I thought it was pretty nice. I'm pretty sure it can be done with divide and conquer. Label the bales 1 to n from left to right, and label the sections between consecutive bales 1 to n-1 so that section i has bale i to the left and bale i+1 to the right. For each section, we will maintain whether it is possible to break out to the left and to the right.
Split the set of sections in half, into a left half and right half. Recursively solve each half. For each section in the left half, we now know whether it can break out the left side and whether it can break out the right side of the left half (the midpoint of our combined halves), and similarly for the right half.
Consider the left half. Assume that all sections can break through the midpoint, the wall separating the left and right half. For each section, calculate how far right Bessie can go only going right. This will be non-increasing because of our assumption, so we can calculate it in linear time. If section i can break out the right side of the right half only going right, then update it. Otherwise, see if bale i can be broken with the additional space. If it cannot, then section i is dead. If it can, then section i can break out to the right or to the left if section i-1 can. Finally, for each section we check the assumption that it can break through the midpoint, and update accordingly. Do the same thing for sections in the right half going left.
This takes O(NlogN) time. To get the answer, add up the lengths of all the sections that can't break out to the left or right.
Here's my solution to problem 3 that I found in contest. I remember someone telling me there is an O(N) solution after sorting, but I don't remember it.
First sort the points by increasing position. Relabel them 1, 2, ..., N. Define an "unbreakable range" to be a range [i, j] such that Bessie cannot break out of it, i.e. pj - pi ≤ min(si, sj). Now clearly if we union all the unbreakable ranges, we get the set of ranges such Bessie cannot escape from. We don't need to find all unbreakable ranges though, only ones not contained inside others.
So for each i, we'll find the largest f(i) such that the range [i, f(i)] is unbreakable. First binary search to find the largest f such that pf - pi ≤ i. So now the only positions we care about are [i + 1, f]. Now, consider all points g such that pg - pi ≤ sg. This rearranges to pi ≥ pg - sg. This motivates us to construct another array of points sorted in increasing order by pi - si. So to find the largest f(i) we essentially are intersecting a prefix of the array of pi - si with the range [i + 1, f]. You do this by processing these intersections offline by doing a left to right sweep of the pi - si array (and segment tree). Most of the finding largest is done by binary search. I can attach code if people are interested later.
Alternate finish for desert97's solution to 3:
We can store the values pi - si at index i in a sparse table RMQ, and do binary search to find the last bale. Start with low = i, high = f + 1. Then, to check if a value mid works, meaning there is a bale in the range [mid, f] that when paired with bale i "traps" Bessie, check if RMQ.query(mid, f) ≤ pi.
Won't this take longer complexity-wise? As in something like O(nlog2n)?
If you make the RMQ O(1) per query, it's still . (Actually I was lazy in the contest and did the
. (Actually I was lazy in the contest and did the 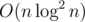 with my RMQ but it passed so didn't bother)
with my RMQ but it passed so didn't bother)
@yzyz That's basically what I tried to implement for problem 1. How did you store the big integers?
For problem 3 I realized that to not be able to escape, you eventually have to be stuck between a pair of haystacks. Therefore, you can test all pairs of haystacks, and then the answer will be the union of the segments that work. I added some optimizations, and got a 20 line solution that passed all test cases. :)
lol I switched to Java and used BigInteger
Just for people's interest, here's a solution to #1 without binary searching. You maintain 2 functions: I'll just call them f1, f2 since I'm lazy.
f1(v) finds the size of the subtree of vertex v. f2(v, x) finds the size of the subtree of vertex v minus x (so it returns either 0 or 1) given that it is either size x or x + 1.
Let's first see how to do f2 efficiently. If x is even, then how does a tree of size x differ from one of size x + 1? The difference is that in the x case, the right subtree is size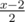 , but in the x + 1 case, the right subtree is size
, but in the x + 1 case, the right subtree is size  . In this case then, f2(v, x) = f2( right child of
. In this case then, f2(v, x) = f2( right child of 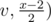 .
.
Similarly, if x is odd, f2(v, x) = f2( left child of . Therefore, f2 runs in logn queries.
. Therefore, f2 runs in logn queries.
Now back to f1(v). Given f2, this is easy. First just compute the right child of v's size recursively using f1, then call f2 on the left child. Runtime analysis is T(N) = T(N / 2) + logN. This will query at most around 50, 000 times without needing to store previous queries.
Is the tree in the first problem a binary search tree or just a binary tree?
Just binary with mentioned property about the size of the subtrees.
if you meant "increasing" then i would have to agree with you
Here are my solutions and submissions for the Gold problems:
Problem 1 (googol): Same as yzyz's. Caching queries and bignum are required to solve this. (Code: https://www.dropbox.com/s/h04srp7vgq9dt9q/googol.cpp?dl=0)
Problem 2 (palpath): My solution was O(N3) dynamic programming: split the palindrome about the diagonal of the square, and build towards the corner. Each state is defined as a pair of diagonals symmetric about the lower-left to upper-right diagonal and a pair of squares, one on each of the chosen diagonals. There are O(N) diagonals and O(N2) pairs of squares for a given pair of diagonals, giving us O(N3) states. Since transitions can be done in O(1), we have an O(N3) algorithm. To score full points, one has to compress the DP to O(N2) memory by storing the DP values for only two pairs of diagonals at a time. (Code: https://www.dropbox.com/s/brqsgbfdiej1ymf/palpath.cpp?dl=0)
Problem 3 (trapped): Without loss of generality, assume that P1 < P2 < ... PN. Observe that for Bessie to be stuck between the haybales indexed i and j (i > j), we must have min(Si, Sj) ≥ Pi - Pj. Thus for each i, we want compute the smallest j that satisfies the above condition. As we loop over i, we can maintain the set of haybales j that satisfy Sj + Pj ≥ Pi sorted by Pj. Then we use binary search to find the smallest j such that Pi - Si ≤ Pj. To implement this, we can use two STL sets, one to store the relevant haybales and the other to keep track of when haybales should be removed from the first set. The final step is to sweep over these segments and find the total length of their union. Overall, this runs in . (Code: https://www.dropbox.com/s/ajror0g1dzqt11e/trapped.cpp?dl=0)
. (Code: https://www.dropbox.com/s/ajror0g1dzqt11e/trapped.cpp?dl=0)
@Edvard: Thanks for pointing that out!
In second problem you could have O(N3) memory, to squeeze it in you just need not to waste memory on the DP states which you will never visit, for example if you start from (y1, x1) and try to build palindrome to (y2, x2) then you'll never need a DP state for y1 > y2 or x1 > x2 or if (y1, x1) goes beyond the diagonal. In total this allowed me to have around N3 / 4 DP states which takes less than 256 MB of memory.
Gold division interactive problem doesn't need a caching, it can be done without querying same node multiple times. Mine solution consisted of just two functions:
check_size(V, maxSize)— calculate the size of V's subtree given that this size is either maxSize or maxSize - 1. This can be easily done with one recursion to only one leaf because for each maxSize you know which son (left or right) you need to check next. So if maxSize is even you callcheck_size(V_left_child, maxSize / 2), otherwise you callcheck_size(V_right_child, maxSize / 2).get_size(V)— calculates the full size of V's subtree. First of all you check if V has both children. If it doesn't then you know the result immediately. If it has both children, then you recursively calculate the size of the left child, let's denote it as leftChildSize. Then you already have an estimate for the right child's subtree so you callcheck_size(V_right_child, leftChildSize). In total these two results give the size of V's subtree.Each of this function queries the children of V, but for any V you will always call at most one function so the caching is not needed.
I was disappointed in how I did on this contest-it should have been a pretty easy 1000, but I got stuck debugging #1 for several hours. One issue I had was writing BigInteger("10") and BigInteger("11"), which were supposed to correspond to 2 and 3, but I was still thinking in binary...
I solved 2 completely, found the approach for 3 but didn't have time to start it, and didn't submit anything for 1 but (hopefully) finished after the contest. I haven't tested it against the official graders so it might still be bugged, but it worked on the test case I put in.
1: http://pastebin.com/S38fZFmE Basically, if the indices of your nodes at the bottom layer are
Then the nodes that are actually contained in the tree are some prefix of the sequence
So we can do a kind of pseudo-binary search to find the last nonzero term in this sequence. Start with 100..00; if you can add 1 while keeping the node nonzero, do this. Repeat for 10, 100, ... 100..00, totaling log(n) steps. Each time you need to find if a new node would work, you have to backtrack in log(n) to go from the top numbers that are known to this specific node log(n) layers down. In order to get a good enough constant for <=70,000 queries, it is also necessary to memoize information that is already known.
2: http://pastebin.com/EpjWdx7c Pretty standard dp. Note that a prefix of length k can only end in k spots, and similarly for a suffix of length k. So for each k from 1 to n, we store the k^2 values corresponding to the number of pairs of prefixes to i and suffixes from j which are reverses of each other for each 1<=i,j<=k. In total, this runs in O(n^3) with a good constant and uses O(n^2) memory.
3 Didn't code it, but my solution is the same as waterfalls' here: http://codeforces.net/blog/entry/17291#comment-221281
What do you think about the problems? Weren't they a bit easier than usual?