


Hello CodeForces Community!
I am glad to share that HackerRank's CounterCode (CodeSprint on Algorithmic Programming Challenges) is scheduled on 1st-August-2015 at 16:00 UTC.
Go ahead and register now at www.hackerrank.com/countercode to show off your coding chops, and win amazing prizes like Apple iPhone 6, Sony PS4, Bose Headphones, Fitbit Charge, WD 1 TB HardDisk and HackerRank t-shirts!.
All participants who completely solve one challenge (that’s just 1 out of 8 questions!) will get $100 of AWS credits.
Also, you'll get an opportunity to connect for a career opportunity with CounterCode contest sponsors — Asana, Blippar, LaunchCode, Marketo and Verizon.
Contest will be rated, scoring is 20 — 30 — 50 — 70 — 100 — 120 — 140 — 150. Tiebreaker is person to reach the score.
Editorials will be live soon after the contest ends, I invite everyone from experts to beginners to participate and solve challenges. This is going to be a really awesome contest :)
GL&HF







Start of CounterCode conflicts with SRM 664. 2 hours shift would be great.
Two hours sooner will be fine, but two hours later will be a problem for me because of timezone.
Date and time are decided by marketing team 1 month in advance, and specially when sponsors are involved this happens with their consent.
We follow the calendar https://www.hackerrank.com/calendar and when we listed SRM didn't so the time of contest will not change.
Anyways it's a 24h contest, you can possibly join later.
shashank21j will this contest be rated?
Yes , our plagiarism detector has choked :P fixing it, after that will rate. Wait for 24 hours :)
I phone6 *_*
property of tourist
August Easy, SRM 664 and CounterCode all begin on the same time! If you could shift this contest for about 2 hours or more, it'll be highly appreciated. We are humans after all:P
What does it mean? Google Code Jam-style: penalty is the time of last submission that changed score, is it correct? There is no penalty for incorrect submissions, is it true?
Will there be instant feedback, like in old challenges practice?
Yes codejam style, Time of last submission that increased score is taken into account.
No penalty for incorrect submission Full feedback for every submission (no hidden testcase and no rejudging later on hidden tests)
This rule-set makes the contest even more interesting :)
I'd say this ruleset makes duration of 24h pointless.
Not necessarily. HR doesn't have subtasks / batch tests — each input file is scored independently, so if there's a challenge-type problem (non-binary scoring of each test or just solvable using heuristics etc), then it could be a decent tiebreaker. It depends on the setters/testers.
Time should not be a tiebreaker in 24h contests, anyway.
UPD: It was done the exact opposite way, the last 2 problems had no partial scoring...
Unfortunately, "tiebreaker is first person to reach score"
I understood it as tiebreaker in case of getting equal points. Obviously, the main tiebreaker must be the scored points.
Last submission time or last submission time — open time, like weekly challenges?
Just submission time
May I have a list of problem setters in advance :)
What about time and memory limits? I've looked through old contests and found out that there are no information about them at all. There is 'environment' page with TLs specified, which are bullshit: I've tried one problem and my C++ submission got terminated in 1 second, not 2 seconds. I've asked support week ago and their answer was:
Old ACM-ICPC style? Your program should terminate in a reasonable amount of time and you can expect reasonable amount of test cases in a single input?
Looking at the scoreboard now, 24 hours definitely were too much for the top competitors. There are already several highscores and with small (20 minutes between the top 2 places) time differences.
The contest isn't just about the prizes, there's also the other 99% of the scoreboard. Also, everyone is asleep now, it looks like you might need to solve the 140 or 150 for a t-shirt, and people will solve it in the morning, so 24h makes sense. Now stop complaining and continue coding, you still have a chance to grab the HD before tourist wakes up.
Hard Disk claimed by yeputons :D congrats!
Lol I didn't say anything about prizes :D. It's that I tend to connect 24h contests with (me) actually needing those 24 hours (or 24- hours) of effort, but only the last problem needed non-negligible thinking time.
Oh well. Here's my solution of that last problem:
introductory tree classic: 2^k-th and K-th (for some K) ancestor of each vertex, depths, sums from the root (vertex 1) everywhere; we're able to find LCAs
in order to avoid doubles, we want to check if the sum from A to X — T*(the distance of A and X) > 0 somewhere
the limits allow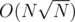 solutions comfortably and an additional log-factor with possible optimisation; we can split the path into O(N / K) pieces from A up to the L = LCA(A, B) and O(N / K) from B up to L and process each piece somehow, then bruteforce a small (O(K) vertices) path containing L
solutions comfortably and an additional log-factor with possible optimisation; we can split the path into O(N / K) pieces from A up to the L = LCA(A, B) and O(N / K) from B up to L and process each piece somehow, then bruteforce a small (O(K) vertices) path containing L
so we always have some vertex, take the paths up from it with length 0..K - 1 edges (if it's the part from A to L; if it's from B, we find its K-th ancestor and take paths down from that ancestor to that vertex of length 1..K) and want to know the maximum of (path sum)-T*(path length) for each T — more precisely, if we keep incrementing T, then we want the pair (sum,length) that gives the maximum for each T where this pair changes, which can be done by the "convex hull trick" in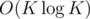
when we know those numbers, for given T, we just find the last smaller T where that pair changed and take the max. given by that pair for our given T, so we always move K edges up with cost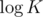
time complexity now: ; that's too slow, so we only do the convex hull trick thingy for vertices with depth divisible by K and always bruteforce O(K) vertices above A and B until the first vertex with this depth divisible by K; the part with
; that's too slow, so we only do the convex hull trick thingy for vertices with depth divisible by K and always bruteforce O(K) vertices above A and B until the first vertex with this depth divisible by K; the part with 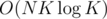 has a small constant now, so we can take K = 300 and add clever breaks and it works :D
has a small constant now, so we can take K = 300 and add clever breaks and it works :D
I wasted some time thinking if it's possible to solve it faster, got some good ideas, but they only worked for simpler variations of the problem. In the end, Method Lumberjack (cut till it falls) worked well... I wonder if there's a fast solution. And I used another sqrt-decomposition in Subset, too.
My solution is O(N * log2(N)). I used heavy-light and convex hull trick on segment tree.
Edit : Editorial uses the same idea.
Oh... of course. I didn't try to improve the idea with convex hull trick...
But my approach seems simpler! :D (one less HLD)
As I remember you said, "HLD is just a dfs" but SQRT-Decomposition is SQRT-Decomposition :D
http://codeforces.net/blog/entry/17401?#comment-222355
Yes, HLD is pretty simple as well and there isn't far from moving up sqrt-paths to moving up HLD-paths, but this sqrt-decomposition was really just "bruteforce, then a small loop where you pick the right subpath from a map, bruteforce again" — still a bit simpler. Convex hull trick is the whole bulk of the idea (about 90% of my effort went to it... why when I wrote it correctly easily a week+ ago?).
Don't dwell on my lulzpost that obviously exaggerates details :D
...but only the last problem needed non-negligible thinking time.
I can't somehow relate to that :D
I splitted tree in centroids and processed each subtree twice for up and down queries (like in convex hull). My solution is O(NlogN + QlogN). On each query I did binary search by value of T.
Can you give more details or post your code?
I tried to find a solution using Centroid Decomposition but couldn't.
I found that actually my solution is O(Nlog^2N + Qlog N). Actually it do the same as other solutions, but splittes the path from A to B in other way.
Can I report cheating requests somewhere, e.g. "send me the code/tests"? I've marked them as spam for now.
How to solve Subset?
I solved it using two tries. code
Your idea is correct , but you didn't really needed to use trie , arrays are enough
Can you explain little bit about your approach ? I actually used just one tries and got accepted but i feel in worst case i might have to traverse whole tries how did you optimize that using 2 tries ?
I solved it with sqrt-decomposition.
I solve it the using brute force algorithm with some optimization.
However the correct one used similar technique like http://codeforces.net/contest/348/problem/C.
what exactly the optimization you did?
for add or del
tot++ or tot--
for cnt:
if (s==((1<<16)-1)) cout<<tot<<endl;
If number of bits in S less or equals to 8, then add/del takes O(16) time at max, cnt takes O(28) time at max
If number of bits in S more than 8, then add/del takes O(28) time at max, cnt takes maybe O(214) time at max, maybe I made a mistake in time complexity for this case
Source
I used a trie: http://pasted.co/175145aa
The main idea is that you only need to store / remove values < 2^16, this can be easy mantaining a trie with depth of 16.
For query you need only the last 16 bits of the value, then traverse the trie and if in some level, all the remainding bits of the value to query are 1, you can only return a precalculated value in that node (sum of all nodes down). See the code for more detaills, I guess my implementation was straightforward.
I really liked solving this one.
But isn't then the worst case complexity of each query= 2^16?
Yes, it is.
add/remove works in O(N) where N is the number of bits (16).
Query has worts case complexity when the value has every bit turned on but the most significant bit off, this only if there are all 2^16 possible values, in average is much faster, there are some tricks to optimize the worst case but this got accepted.
I split the problem for first and second byte of s.
code
Nice problem sets.
However, it is really hard to get a T-shirt.
Can't find any information about T-shirts. :( How many top participants will get T-shirts?
Top 25 link
BTW, editorial of "Long Narrow City" is really awesome.
Thanks, I'm glad you enjoy it ;)
Indeed. One of the best written editorials I've read. Nice problem for a long contest. Keep up the good work :). I figured out the solution but was too lazy to code it ;-)
Shouldn't the editorial be unlocked even if you solve the problem after the contest?
Nope, you don't need to buy it if you've solved it.
The question "Poisonous Plants" is the same as : http://codeforces.net/problemset/problem/319/B
Where is the editorial?
Or can someone explain the solution for problem 5 (Best Photo)? I think is dp but couldn't solve it.
For all i, make an edge i to a[i]. You need to find circles, components, etc. Than you have to do some math on it.
I tried some like that while the contest was running but the math was not obvious for me, can you give more details?
Thanks.
You can start by calculating the maximum number of groups you can be from these graphs.
LOL, we can solve Subset with O(215 * Q) time complexity, http://ideone.com/E1itZd
Could you tell what is meaning of osob array? And how it helps to avoid TLE? Thanks.
O(215 * Q) = 215 * 200000 > 109 How is it not TLE?
Because the test set didn't have all queries as worst case, that's how.
Subset. Could someone explain this moment 'then count the numbers X that have at least one common 1-bit with S by inclusion — exclusion principle'. I don't quite understand how to use inclusion-exclusion principle there. Thanks.
There is a mistake in the last letter: w4yneb0t (3rd place) has 680 points, not 550