


621A - Wet Shark and Odd and Even
First, if the sum of all the numbers is already even, then we do nothing. Otherwise, we remove the smallest odd number. Since, if the sum is odd, we need to remove a number with the same parity to make the sum even. Notice it's always bad to remove more odd numbers, and it does nothing to remove even numbers.
Let's start with two bishops (x1, y1) and (x2, y2). Notice that if (x1, y1) attacks (x2, y2), either x1 + y1 == x2 + y2 OR x1 — y1 == x2 — y2. So, for each bishop (x, y), we will store x + y in one map and x — y in another map.
Let f(x) be the probability that the product of the number of flowers of sharks x and 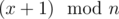 is divisible by p.
is divisible by p.
We want the expected value of the number of pairs of neighbouring sharks whose flower numbers are divisible by p. From linearity of expectation, this is equal to the probabilities that each pair multiplies to a number divisible by p, or f(0) + f(1) + ... + f(n). (Don't forget about the wrap-around at n)
Now, for each pair of neighbouring sharks, we need to figure out the probability that their product is divisible by p. Consider an interval [li, ri]. How many numbers in this interval are divisible by p? Well, it is easier if we break the interval [li, ri] up into [1, ri] - [1, li - 1]. Since 1, 2, ..., x contains 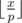 numbers divisible by p, the interval [li, ri] contains
numbers divisible by p, the interval [li, ri] contains 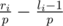 numbers divisible by p.
numbers divisible by p.
Now, consider two numbers 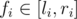 and
and 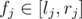 , with
, with 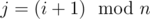 . Let ai be the number of integers divisible by p in the interval [li, ri], and define aj similarly. Now what's the probability that fi·fj is divisible by p? We can count the opposite: the probability that fi·fj is not divisible by p. Since p is a prime, this means neither fi nor fj is divisible by p. The number of integers in [li, ri] not divisible by p is ri - li + 1 - ai. Similar for j. Therefore, the probability fi·fj is not divisible by p is given by
. Let ai be the number of integers divisible by p in the interval [li, ri], and define aj similarly. Now what's the probability that fi·fj is divisible by p? We can count the opposite: the probability that fi·fj is not divisible by p. Since p is a prime, this means neither fi nor fj is divisible by p. The number of integers in [li, ri] not divisible by p is ri - li + 1 - ai. Similar for j. Therefore, the probability fi·fj is not divisible by p is given by 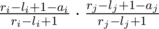 . Therefore, the probability it is can be given by
. Therefore, the probability it is can be given by 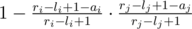 . Now, just sum over this for all i.
. Now, just sum over this for all i.
The tricky Rat Kwesh has finally made an appearance; it is time to prepare for some tricks. But truly, we didn't expect it to be so hard for competitors though. Especially the part about taking log of a negative number.
We need a way to deal with xyz and xyz. We cannot directly compare them, 200200200 is way too big. So what we do? Take log! 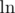 is an increasing function on positive numbers (we can see this by taking
is an increasing function on positive numbers (we can see this by taking 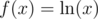 , then
, then 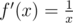 , which is positive when we are dealing with positive numbers). So if
, which is positive when we are dealing with positive numbers). So if 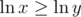 , then x ≥ y.
, then x ≥ y.
When we take log, 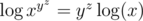 But yz can still be 200200, which is still far too big. So now what can we do? Another log! But is it legal? When x = 0.1 for example,
But yz can still be 200200, which is still far too big. So now what can we do? Another log! But is it legal? When x = 0.1 for example, 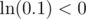 , so we cannot take another log. When can we take another log, however? We need
, so we cannot take another log. When can we take another log, however? We need 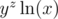 to be a positive number. yz will always be positive, so all we need is for
to be a positive number. yz will always be positive, so all we need is for 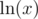 to be positive. This happens when x > 1. So if x, y, z > 1, everything will be ok.
to be positive. This happens when x > 1. So if x, y, z > 1, everything will be ok.
There is another good observation to make. If one of x, y, z is greater than 1, then we can always achieve some expression (out of those 12) whose value is greater than 1. But if x < 1, then xa will never be greater than 1. So if at least one of x, y, z is greater than 1, then we can discard those bases that are less than or equal to 1. In this case, 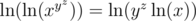 . Remember that
. Remember that 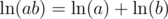 , so
, so 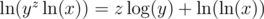 . Similarly,
. Similarly, 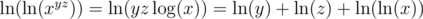 .
.
The last case is when x ≤ 1, y ≤ 1, z ≤ 1. Then, notice that for example, 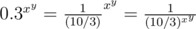 . But the denominator of this fraction is something we recognize, because 10 / 3 > 1. So if all x, y, z < 1, then it is the same as the original problem, except we are looking for the minimum this time.
. But the denominator of this fraction is something we recognize, because 10 / 3 > 1. So if all x, y, z < 1, then it is the same as the original problem, except we are looking for the minimum this time.
First, let us build an X by X matrix. We will be applying matrix exponentiation on this matrix. For each modulo value T from 0 to X — 1, and each value in the array with index i between 1 and n, we will do: matrix[T][(10 * T + arr[i]) % X]++. This is because, notice that for each block we allow one more way to go between a modulo value T, and (10 * T + arr[i]) % X. We are multiplying T by 10 because we are "left-shifting" the number in a way (i.e. changing 123 -> 1230), and then adding arr[i] to it. Notice that this basically simulates the concatenation that Wet Shark is conducting, without need of a brute force dp approach.






How foolish i am, i thought of the Problem C's Independence.at the end of the contest i finally figure out that if ppl_2 have a number can be divisible by p,we dont need to care about what number ppl_1 and ppl_3 take:(
They are not people. They're sharks :p
D is more difficult than E...
That's ridiculously common...
Probably it's just because DP/Matrix exp. are well-known and heavily trained topics, whereas D is somewhat non standard. I solved D in 12 minutes and E in more than 1 hour... Though I used python's decimal for D which is a bit hacky.
in Problem C why did you say x*(x+1) mod n divisible by p?
isin't x(x+1) divisible by p?
Sorry, I fixed it.
Problem E can be solved without matrix exponentiation. Denote by DP[b] the solution array (i.e. DP[b][k] is the actual solution, the others are needed for the computation). Now, if we compute DP[2 ^ i], for all i < 31, we can easily get DP[b] by making use of the binary representation of b. The whole solution hinges on a function Unite(a, b), which computes DP[a + b] from DP[a] and DP[b] in time O(x ^ 2).
same solution
There my solution (runtime somewhere, but guess idea is correct)
denote D1[d][k] count d-digit numbers with k-reminder. Easy to calcuate by:
D1[d][(10 * j1 + j2)] += cnt[j1] * D1[d — 1][j2]; 0 <= ji < x;
Now make blocks 1000, 1000, 1000,.... b % 1000 digits (b / 1000 + !!(b % 1000) blocks);
denote D2[d][k] count d-block numbers with k reminder. Calculate absolutely analogically.
Then ans is D2[blockCount — 1][k]. Complexity is O(1000*x^2).
If i'm thinking correct, complexity would be O(10^6 * x^2). You'll make D1 in O(1000*x^2) but then there can be 10^6 blocks of 10^3 length . If you again divide your 10^6 blocks into 10^3 "big" blocks , then it should work.
Thanks for correcting, I'm "the genius of Math":D
Can you elaborate slightly on your approach?
What exactly are we doing with matrix exponentiation in problem E? Can somone please explain. I am not able to understand the editorial solution!
Optimize dp.
Thank you. That was very informative :P
:)
To simplify the explanation, it is assumed that all computations are done modulo 1, 000, 000, 007.
First, note that the n given digits are not important -- what is important is the occurrences of each digit. Let occ[d] be the occurrences of digit d.
We will try solving this problem using DP. Let dp[i][j] = the number of ways we can pick i digits such that the final modulo is j.
The base case is obviously dp[0][0] = 1. For i > 0, the recurrence can be given as:
dp[i][j] = sum{occ[d] × dp[i - 1][a]}, for all 1 ≤ d ≤ 9, and for each d, a is an integer 0 ≤ a < X where (a × 10 + d)%X = j.
(Intuitively, given a number consisting i - 1 digits that is a modulo x, we can form a number consisting of i digits that is a × 10 + d modulo X = j, by appending the digit d.)
The final answer would be dp[B][K]. Unfortunately, this DP will get TLE as B can be up to 109. To speed it up, we will use matrix exponentiation trick on the recurrence.
Suppose we have a vector F0 consisting of X elements, where
Exercise 1: Compute the value of the elements F0!
Now, construct a X × X matrix T, in such a way that
F1 = TF0,
where
Exercise 2: Compute the value of the elements of T!
In a similar way, we can compute F2 = TF1 = T2F0. Now, we want to compute
FB = TBF0,
which is,
The answer will be... FB[K], which is dp[B][K]!
TB can be computed in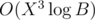 using exponentiation-by-squaring, which will fit the time limit.
using exponentiation-by-squaring, which will fit the time limit.
That was cool. Thank you very much.
I think it's possible to solve in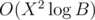 without matrix multiplication. Submission: [submission:15723291]
without matrix multiplication. Submission: [submission:15723291]
And it looks like with FFT it can be optimized to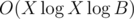
This is wonderful.
But how to construct the matrix T?
Initialize the matrix with all zeroes, then increase the cells in the way mentioned in the editorial.
You can check http://fusharblog.com/solving-linear-recurrence-for-programming-contest/ :)
Hey, equations in your blog are not visible properly. Can u please check it once.
thank you !
D can be solved with complex numbers, to avoid having to treat cases where some numbers are smaller than one, differently. Note that the real part of log(log(x)) is growing if log(log(x)) is real, and decreasing if it has an imaginary part. So you can just write a comparison function to find the maximum.
Awesome, now we can easily handle such cases that log(x) is less than zero. Thanks for your idea.
great idea!
Can you explain how to compare between complex numbers?
If x > 1, then log(log(x)) is an increasing function, and if x < 1, then real(log(log(x))) is a decreasing function, because taking a logarithm of a negative number results in something like this: log( - x) = log( - 1·x) = log( - 1) + logx = iπ + log(x). (Assuming log(x) is done in base e) Therefore, to compare two numbers by their loglog, you can do something like this:
"long double" is still required,because the result of y^z^x will exceed the range of "double" on (test 9: 185.9 9.6 163.4 ) when using "complex"
You shouldn't ever actually calculate the value of y^z^x, since log(log(yzx)) = log(zxlog(y)) = xlog(z) + log(log(y)). That's the whole point of using log log, you can compare those gigantic numbers without actually calculating them.
I made a mistake. :< I forgot to modify the calculation function.I just calculated log(y^z^x).
Is there a good matrix library in C++? Or you simply write an algo for matrix binpow each time you need it?
But yz can still be 200200, which is still far too big.
Apparently, one of the passed solution use that method.
Interesting. How it works? In C# we will just get Infinity value in such case, and Infinity is equals to another Infinity, so wrong result on case #9.
Codeforces compiler suggest that maximum range of long double is 1.18973 × 104932, which is greater than 200200 ≈ 1.6 × 10460
Ouch, nice. In C# max for double is just 10^308.
C# also has BigInteger type. Wouldn't be suitable for this particular problem, but very useful for others.
Can somebody help me with this [submission:15713106] submission for C? I cannot understand why it failed.
UPD: I fixed it by changing the printf call to cout [submission:15715786]
Is this issue known/documented somewhere? MikeMirzayanov
http://codeforces.net/blog/entry/23147?#comment-275981
E can be done in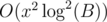 too- let vj be the array of size x such that vj[i] is the number of ways of getting a number that is i mod(x) after j steps; v2j and v2j + 1 can be computed from vj in
too- let vj be the array of size x such that vj[i] is the number of ways of getting a number that is i mod(x) after j steps; v2j and v2j + 1 can be computed from vj in 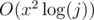 . The crucial fact here is that if the value of the first p blocks is i mod(x) and that of the last q blocks is j mod(x), then the whole number will be i + 10q·j mod(x).
. The crucial fact here is that if the value of the first p blocks is i mod(x) and that of the last q blocks is j mod(x), then the whole number will be i + 10q·j mod(x).
You mean the whole number is (i * 10 ^ q + j mod x) since i comes first .
can anyone explain C in easier way
The intuition is that if you can find out the probability of each person, then you can solve the whole problem. This is because the whole sum of money is the expectation of each cases(1-2, 2-3, etc..). The expectation of each pair is 1 — (1-p_i)(1-p_j) because the pair would not get paid only when both don't satisfy the condition. This is same for all the pairs, so now we just need to find out the probability(expectation) of each person. This is explained in the editorials
thank you so much but i want to ask if you can tell me about a good resource to learn about this kind of problems
I'm not sure if your "these kind of questions" meant algorithm questions is general, or this particular question, but assuming the latter I recommend studying basic discrete mathematics. This set especially had a lot of math questions, and understanding of discrete mathematics will make you have a better intuition of solving problems. The more you learn, the more you'll see.
thank you
Why this approach is wrong for B
iterate each diagonal of the grid and count the number of bishop x in that diagonal .
if the number of bishop is > 1 than we add x(x+1)/2 to the answer .
i get accepted with the same idea you may made a mistake in the code http://codeforces.net/contest/621/submission/15705229
This is my submission
It has to be x(x-1)/2 rather than x(x+1)/2. A.Magdy7's solution works because he decreases x by 1 before calculating with the x(x+1)/2 formula.
yeah you are right , silly mistake but even when i changed x by x-1 its still give WA .
Nope.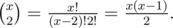
Consider there are x bishops in a diagonal. The first bishop has x-1 bishops to pair with, the second bishop has x-2 bishops to pair with, and so on. We can notice the number of pairs is (x-1)+(x-2)+...+1 which can also be expressed as (x-1+1)(x-1)/2 = x(x-1)/2.
i fix that but still got a WA
because you don't search in all the diagonals you always search above the main diagonal in both direction and don't search under it
You right , i got AC , thanks .
My solution of C : First we see how to find the expected money given to any two neighbouring sharks :
Here, is my code which i couldn't submit because of internet issues : Code
Can you explain something about linearity of expectation?
So Java's sorting does some sketchy things, but only some of the time...lol
http://codeforces.net/contest/621/submission/15716716 AC
vs
http://codeforces.net/contest/621/submission/15716729 TLE
with the only difference switching
with the unrelated
At least my rating is historic now!
I'm pretty sure this is because Arrays.sort calls quick sort for primitive data types and merge sort for objects. So there must have been an anti quick sort test case, in which quick sort is called for one solution but not the other.
Why can't I open problem D? it says : Can't read or parse problem descriptor. Is any one else getting this error?
Why my code although passing test-case 9 of 100000 numbers but getting TLE on test-case 15 of 500 numbers http://codeforces.net/problemset/problem/621/A http://ideone.com/OWI8Ba
i=n-1; in each iteration, cycle infinity, for example, in this test: 3 2 3 4
"But y^z can still be 200^200, which is still far too big" Can anybody help to find a test that breaks my solution [submission:15713937] ?
For D: Python's decimal for the win :) one logarithm is enough
[submission:15703568]
Could anyone help to understand what is wrong here with Problem D?
submission with EPS = 1e-14 gives wrong answer on test #134: 200.0 200.0 200.0: [submission:15719829],
the same code with EPS = 1e-13 gives AC: [submission:15719618].
I've logged the difference between two values of m * log(m) + log(log(m)) for m = 200.0 in first case and it appears to be ~5e-14, so this is the reason. But when I'm trying to reproduce this problem manually (see main at [submission:15719829]), it is giving zero difference. On my mac with clang 6.0 compiler case 200.0 200.0 200.0 gives proper answer: x^y^z.
It is OK that taking of two exactly the same arithmetic expressions with "equals" double numbers can give a different answer?
[submission:15735486] I change left + EPS < right to left — right < 0. Also you can use long double instead double.
Thank you! But another interesting thing is that solution with 1e-14 passed when I changed compiler on the MS Visual Studio 2010 on CF: [submission:15735359].
Calculating C the probability itself (and not the 1-p) gives WA because of error approximation.
I calculated the probability of every single position getting a multiple of the prime (multiplied by 4000) and, using inclusion-exclusion principle, removed the the cases where two consecutives where primes (multiplied by 2000).
If someone could explain me why this is incorrect or if the jury had a tighter error, I'd be very grateful.
I don't know how to post links, but the submission was: 15706251
Your submission link: To post a link, just hit ctrl+L and enter the link.
Thank you for the tip. I still don't think the maximum error in the problem C was correct since the direct was generated error almost 10^5
In test 69 of problem D x=0.2, y=0.7, z=0.6. My program output (y^z)^x on this test. But there is expected (y^x)^z. But (0.7^0.6)^0.2>(0.7^0.2)^0.6! I have checked this on the calculator. (0.7^0.6)^0.2-(0.7^0.2)^0.6=1.9535924907431949702433539286085e-38.
In fact, (0.7^0.6)^0.2=(0.7^0.2)^0.6 since (a^b)^c=a^(b*c). Thus you do the one with the smaller index.
I see, thank you.
I bet D is simpler, so left no time for E.....
Problem D can be coped with in this way: notice that log log x^y^z = z*logy + log log x, log log (x^y)^z = yz log log x; so the only problem to discuss is log log x. if log x is positive, that is easy, cuz f(x) = log log x is a strictly increasing function, so the larger the better. if log x is negative, we take log -log x for the log log x part. so the function became strictly decreasing, and since two cases use different functions, they can not be compared. And then the only problem is the order.
Isn't that what's written in the editorial?
In problem C : Aren't f(i) and f(i+1) dependent? Is linearity valid even if they are dependent?
Yes. That's called "linearity of expectation".
I am a bit confused. You mean to say that f(i) and f(i+1) are dependent?
They are dependent, but their expected sum is not -- E[f(i) + f(i+1)] = E[f(i)] + E[f(i+1)], so you can compute the values independently.
Thanks for clearing my head. :)
I failed main test C, just because I haven't changed the answer into double, and printed 6 decimal digits behind the point :(
How does this solution get accepted ?
Apparently, long double covers a large portion of the numbers if thats what you are wondering about. Even larger than 200200
Check this snippet Credit: S.Saqib
Hey, everyone?
I am still unable to fully understand the explanation for problem 3. I think that there must be some sort of relation between pair (i,i+1) and pair (i,i-1) (and/or pair (i+1,i+2)) as if s[i]*s[i+1] is divisible by p, then s[i+1]*s[i+2] and/or s[i-1]*s[i] will be divisible by p. How can we just sum them up independently like that?
Could someone please elaborate on this case for me? Thank you.
You can iterate through the array, calculating expectation for each element, thus you will get the relation you're looking for. You need to handle 2 cases: when the selected "shark" gets a number divisible by p, and when it does not, but one of it's 2 neighbours does. You can check out my code if needed
Oh, i see your point, you're asking why we can handle each pair separately. See,
E = x[1] * p[1] + x[2] * p[2] + .., where E — the expected value, p[i] — probability with which x[i] will be added to the answer. The thing is, the mathematical expectation can be easily divided into independent terms, because in fact, expectation is a linear polynomial, and it's distributive property allows us to calculate expectation for sub-problems, summing up the resulting values. I mean,if x[i] = x[i]' + x[i]'' -> p[i] * x[i] = p[i] * x[i]' + p[i] * x[i]''Therefore, we can divide the sum for the whole circle into sum of pairs' answersOh thank you so much, the trouble seems to come from my limited knowledge of mathematics. Your comment helps me figure out that it is linearity of expectation. I will do some googling on it.
"can be EASILY divided into independent terms, because in fact, expectation is a linear polynomial, and it's distributive"
I'd like to give one more level of intuition upon that, cause I saw exactly that in the wikipedia and for some reason it haven't satisfied me :)
But, before telling the whole story and laying out all of my thoughts, I'd like to test my metaphors. My metaphors work for me, but they might not work for you. If it seems appealing to you, I will continue to end the story. If not... well, at least I've tested my hypothesis :)
Let's try to establish the similarity of the problem to the sequence of 8 bits like that:
01110010.If we stretch our imagination we can see the relationship is as follows: when the pair of sharks grows good amount of flowers the Wet Shark gives away 1, when they grow the bad amount of flowers the Wet Shark gives away 0.
The total amount of money that the Wet Shark gives away in the case
01110010is 0 + 1 + 1 + 1 + 0 + 0 + 1 + 0 = 4. The maximum amount of money that the Wet Shark can possibly give away is 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 = 8 * 1 = 8.Imagine that the Wet Shark should prepare it's money beforehand in the bags for money. How many bags should the Wet Shark prepare? These are all the possible sums = {0, 1, 2, 3, 4, 5, 6, 7, 8}.
Now there are a lot of bags the Wet Shark prepared, but, to the time the flowers grow up, it would be nice to have the bag he needs to give away be right before him, so that the Wet Shark doesn't need to look for the right bag among all of those in the pile. = 8 ways to get it:
= 8 ways to get it:
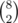 = 28 ways to get it (without details :) )
= 28 ways to get it (without details :) )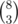 = 56 ways to get it.
= 56 ways to get it. = 70 ways to get it.
= 70 ways to get it. = 56 ways to get it.
= 56 ways to get it.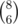 = 28 ways to get it.
= 28 ways to get it. = 8 ways to get it.
= 8 ways to get it.
So, what is the bag that the Wet Shark should expect to give away? To know this, we have to know how many of the possible events force the Wet Shark to give away the bag labeled with some number X.
Let's go through all these bags one by one and see how many ways there are to arrive at each amount.
For bag labeled X = 0 there is only one way to arrive at it, namely
00000000.For bag labeled X = 1 there are
10000000,01000000,00100000,00010000,00001000,00000100,00000010,00000001.For bag labeled X = 2 there are
For bag labeled X = 3 there are
For bag labeled X = 4 there are
For bag labeled X = 5 there are
For bag labeled X = 6 there are
For bag labeled X = 7 there are
For bag labeled X = 8 there is again only one way to get that result:
11111111.So, now we can make up the function P which has as an input the label on the bag X = {0, 1, 2, 3, 4, 5, 6, 7, 8} and returns the number of ways to force the Wet Shark to give that bag of money.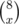 :
:
P(x) =
P(X = 0) = 1
P(X = 1) = 8
P(X = 2) = 28
P(X = 3) = 56
P(X = 4) = 70
P(X = 5) = 56
P(X = 6) = 28
P(X = 7) = 8
P(X = 8) = 1
The function P could be extended to all natural numbers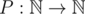 by returning 0 to all of the inputs except for the inputs in the range 0..8, e.g.:
by returning 0 to all of the inputs except for the inputs in the range 0..8, e.g.:
P(X = 115) = 0 <- There are zero ways to force the Wet Shark pay 115 dollars.
By the way, a good read about the linearity of the expected value: an intuitive explanation for the linearity of expectation.
It's a dumb mistake.