


Here is the editorial of Codeforces Beta Round #97. If you have any questions or suggestions --- feel free to post them in the comments.
136A - Presents (A Div 2)
In this problem one had to read a permutation and output the inverse permutation to it. It can be found with the following algorithm. When reading the i-th number, which is equal to a one can store i into the a-th element of the resulting array. The only thing left is to output this array.
The complexity is O(N).
136B - Ternary Logic (B Div 2)
It is easy to see that the answer is always unique. Let's consider an operation which is opposite to tor. From each ternary digit of c we will subtract a corresponding digit of a and take a result modulo 3. We'll obtain a number b which has the following property: a tor b = c.
The complexity is O(logC + logA).
136C - Replacement (C Div 2)
135A - Replacement (A Div 1)
If the largest number in our array is equal to 1 then let's replace it with 2, otherwise let's replace it with 1. After that let's sort the array and output it. It is easy to see that the array obtained in that way is the one we are looking for.
The complexity is O(NlogN).
136D - Rectangle and Square (D Div 2)
135B - Rectangle and Square (B Div 1)
Let's iterate over all partitions of our set of 8 points into two sets of 4 points. We want to check whether the first set forms a square and the second set forms a rectangle.
To check if 4 points lay at the vertexes of a rectangle one can iterate over all permutations of the last 3 points. Then one need to ensure that every two consecutive sides intersect at a 90 degrees angle. That can be done using the fact that the scalar product of two vectors is equal to 0 iff they intersect at a 90 degrees angle.
To check if 4 points lay at the vertexes of a square one can check whether they lay at the vertexes of a rectangle and ensure that two consecutive sides have equal length.
136E - Zero-One (E Div 2)
135C - Zero-One (C Div 1)
First, let's solve the problem when there are no spoiled cards. Let a be the number of ones and b be the number of zeroes. It is easy to see that if a < b then the outcome is 00, because the first player can always remove ones until they are over, which will happen before the end of the game regardless of the second player's moves. Similarly, if a > b + 1 then the outcome is 11.
If a = b or a = b + 1 then the outcome is either 01 or 10. That's because the first player will always remove ones, because otherwise the outcome will be 00 which is worse than any other outcome for him. Similarly, the second player will always remove zeroes. One may notice that the first player can always remove the first card to the left with 1 written on it, because it won't make the outcome worse for him. Similarly, the second player can always remove the first card to the left with 0 written on it. That means that the last card won't be removed by anyone. Thus is the last card is 1 then the outcome is 01, otherwise it is 10.
We've learned how to solve the problem is there are no '?' signs. Now, suppose that the number of ones is a, the number of zeroes is b and the number of question signs is c. To check if the outcome 00 is possible, one can simply replace all question signs with zeroes and use the previous result, i.e. check if a < b + c. Similarly, the outcome 11 is possible is a + c > b + 1.
Let's show how to check if the outcome 01 is possible. If the last character of the string is 0, then the string is not possible. If the last character is ? then we can replace it with 1, i.e. decrease c by 1 and increase a by 1. Suppose we want to replace x question signs with one and c - x question signs with zero. Then the following equality must hold: x + a = b + c - x + (a + b + c) mod 2. Thus, x = (b + c - a + (a + b + c) mod 2) / 2. If the resulting value of x is non-negative and is not greater than c, then the outcome 01 is possible, otherwise it is not possible.
We can check if the outcome 10 is possible in the similar way.
The complexity is O(N).
135D - Cycle (D Div 1)
One can notice that the only possible variant of a cool cycle which doesn't have zeroes inside it is a 2x2 square of ones. This case should be checked separately. From this point we'll assume that the cool cycle we are looking for contains at least one '0' inside it.
Let's take any zero from the table. If it is adjacent to another zero by a side or a corner then it can't lay inside a cool cycle which doesn't have any other zeroes inside it. Thus, this zero can lay inside a cool cycle only together with all zeroes adjacent to it. Generalizing this fact one can show that the zero can lay inside a cool cycle only together with all zeroes reachable from it. We'll assume that one zero is reachable from another zero if they can be connected with a path which consists only of zeroes and in which every two consecutive cells share either a side or a corner.
Let's find all the connected components of zeroes. Two zeroes are connected if they share either a side or a corner. If the component of zeroes has a cell adjacent to a border of the table, then it can't lay inside any cool cycle and thus it should be ignored. After that for each connected component of zeroes let's find all cells with 1, adjacent to it. By the statement all those cells should be connected. Also, each cell from this set should share a common side with exactly two other cells from the set. Note that if the set of cells with '1' satisfy those restrictions, then it forms a cycle which doesn't contain any other cells with '1' inside it.
The above algorithm has the complexity O(NM), if implemented carefully.
135E - Weak Subsequence (E Div 1)
Let cool substring be the substring which is also a weak subsequence.
The main observation is that the longest cool substring in any string is either its prefix or its suffix. Moreover, if, for example, it is a prefix then it can be found in the following way. Let's start moving from the end of the string towards the beginning and memorize all characters met on our way. We'll stop after some character appear in the second time. The prefix with the end in the position where we stopped is the one we are looking for.
Let's count the number of strings in which the longest cool substring is a suffix. First, we will iterate over the number of characters at the beginning of the string lying before the second appearance of some character. Let this number be t. Obviously, t is not greater than k, because all characters in the prefix of length t are distinct. We need to consider the following two cases:
1. If t ≤ w - 1. The first t characters of a resulting string are distinct, then there is a character which was present among the first t characters. After it there are w - 1 more characters. One should also consider that the last t characters are distinct, otherwise prefix of length greater than w will be also a weak subsequence. Thus, the corresponding summand is equal to 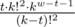 .
.
.2. If t > w - 1. The first t characters of a resulting string are distinct, then there is a character which was present among the first t characters. The last t characters should be distinct, but at this time the suffix of t characters overlaps with the prefix of t characters. The corresponding summand is equal to 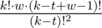 .
.
.After adding up everything for all t from 1 to k we will obtain the number of strings in which the longest cool substring is a suffix of length w.
Similarly, we can find the number of strings in which the longest cool substring is a prefix. The only difference is that we should make sure that the first t + 1 characters of those strings are distinct in order to avoid a double-counting of the strings in which the first and the last t characters are distinct. Considering this the formulas are:
1. If t + 1 ≤ w - 1, then the summand is equal to 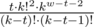 .
.
.2. If t + 1 > w - 1, then the summand is equal to 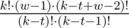 .
.
.The only thing left is to add up everything for all t from 1 to k - 1.
To calculate the above formula quickly one need to precompute factorials for all numbers from 1 to k and they inverse modulo 109+7.
The complexity is either O(K) or O(K· log(MOD)), depending on the way of computing inverse values to the factorials.
As a bonus for those who made it to the end of the editorial, I'll describe a simple linear time algorithm of finding inverse values for all integers between 1 and N modulo prime number P (P > N). I think it will be useful for those who didn't hear about this trick.
Let's consider an obvious equality (% means a remainder of division) and perform a few simple operations with it.
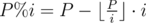
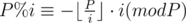
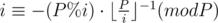
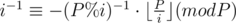
Thus, in order to compute i - 1 we only need to know (P%i) - 1, which is less than i. That means we can compute inverse values successively for all integers between 1 and N in O(N) time.







Heh. You sure are right about being careful on 135D Div 1 Cycle.
I *thought* I had a O(NM) solution, but I was keeping a vector< set<int> > with a total of something like (NM + some %age) entries, of the 1s and 0s. I finally realized, after reading your approach, which was basically the same as mine, that I was doing almost nothing with the sets once I loaded them up! When I dropped the sets, the submitted code finished within the time limit.
Also, isn't the complexity is more like O( (NM)^1.x ), because each '1' may bound more than one of each set of connected 0s?
What really amazes me is how someone implements this - successfully - during the 2-hour competition. I've been working on it on and off for almost a week and finally had something close this afternoon.
Thanks again,
"Then the following equality must hold: x + a = b + c - x + (a + b + c) mod 2"
Why is this so??
i am able to understand 136A..plz explain
(guess that you mean 'unable'...)
I think this problem means that the i-th person gives a present to the pi-th person, and thus the pi-th person receives a present from the i-th person. Therefore, we can adopt an array a[n] and set a[pi] = i (pi is just another positive integer j), and finally it suffices to output array a[n].
An easier way to solve Div1 B / Div2 D is to check the following conditions instead:
For a rectangle: Fix the 4 vertices as $$$A, B, C$$$ and $$$D$$$. Now, we have to check the following 3 conditions:
For a square: Fix the 4 vertices as $$$A, B, C$$$ and $$$D$$$. Now, we have to check the following 2 conditions:
To avoid precision issues, we can compare square of distances instead, which can be computed only using integers.
Code.
I don't Understand question A
SEE THIS EXAMPLE