


Tomorrow at 19:00 MSK will be held Topcoder SRM 694.
Let's discuss problems after contest!
Thanks to dened for pointing out the mistake.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 151 |
Tomorrow at 19:00 MSK will be held Topcoder SRM 694.
Let's discuss problems after contest!
Thanks to dened for pointing out the mistake.







Did you mean tomorrow?Now fixed, thanks!Starting in about 30 minutes.
Looks like chrome quitted when he got what he wanted (top 10 contributors) ;)
What is wrong with the Meet-In-The-Middle approach in 500? i tried it but got WA on example 4(my code returns 940008).
Also i have seen some coders in 250 were not care about condition "groups should't be empty". Is there countertest?
If some group is empty — you can move any element from other group to this one and it will not decrease your score (because a^b<=a+b).
How can you meet in the middle? I guess on masks? Mask halves are not independent, e.g. 10|00 and 00|10 may be bad masks, but 10|10 is good.
Opps. Thank you!
How to solve Div1-900? I saw people used MaxFlow, but didn't figure out how.
Move from
A[i]toA[i+1]-A[i]; there's flowV[i]fromL[i]toR[i]+1. The condition for equality of all elements is now a flow condition (what flows in flows out).Can someone please shortly describe the solutions for first two Div. 1 problems? Failed both of them on systests :)
250 hint: achievable xors are small (up to 256).
500 uses a well-known algorithm for computing something for supersets (or subsets) if we know it for given sets, in O(N·2N).
Could you please elaborate on the well known algorithm for the 500? Where does one learn such algorithm?
Idk, I figured it out myself.
You start with something for each set of numbers from 1..n. You want the sums over all supersets of each set s, so you compute the sums over all sets s' where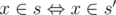 if x ≤ k and
if x ≤ k and 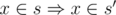 otherwise. For k = n, it corresponds to what you started with; for k = 0, it's what you want; for k < n, it can be computed using at most 2 values for k + 1. Think how.
otherwise. For k = n, it corresponds to what you started with; for k = 0, it's what you want; for k < n, it can be computed using at most 2 values for k + 1. Think how.
Looks like your solution is harder than mine.
Let's fix two strings. They make some masks bad. All such masks are submask of mask constisting of all positions where these two strings have equal chars. We can find such bad supermasks for all pairs of strings in O(n2m). Now we should mark all the submasks of bad supermasks. It can be easily done in O(m2m).
I was asked to describe in detail, and described in detail/formally/generally, the part
which I initially described as
Our solutions are the same.
No way. Your approach is hard-to-come-up-with dp, mine is something like DFS or even easier.
I noticed that many codes for 250 are incredibly similar. I mean that the algorithm is absolutely identical, most differences are variable names (the rest: order of two conditions, initialisation to 0 or -inf, omitting a redundant bitmask, making N global — all trivialities). This... can't be even cheating, it's too obvious. Could so many people be learning it by heart from the same resource?
Has cloning advanced so much?
Maybe they googled the same solution to some similar problem.
It's all reds / high yellows.
The problem is too simple to have different approaches, isn't it?
The simplicity necessary for this to be a coincidence is at the level of div2 50pt. Something like "add N numbers". The differences are cosmetic, most of them are just variable names. I initially thought I opened the same person's code several times in a row by mistake.
My code looks completely different and uses a somewhat different way to count the same thing (no recursion, two less array dimensions). There are other codes somewhat similar to mine, although none as similar as this. There are a few outliers which look very similar to the template I'm talking about when I look better at what they're doing, but not first-glance identical, for example by using a loop instead of backtracking.
It looks really weird.
How to solve div2 1000?
This was my second TC contest.My solution failed in system test for case n=1. The problem can be solved using dynamic programming.
Basically we have to increment n from n-1..while making this change there are n positions possible for n.Suppose we add it in position i(starting from 0) , Then there will be i*(n-1-i) new triples.This causes the dp relation as I have mentioned in the code.(also remember that you have to store answers in dp table)
Nice solution, thanks :D
Thank you! :)
Why there are so strange limitations in 250div1? I was sure that O(nC3) will pass but wrote O(nC2) . I think that O(nC2) solution is nice but the problem is really bad because stupid solution passes.
My O(nC2) solution with memoization got TLE on one of the sample test cases; therefore, I had to rewrite it in a bottom-up approach. I was very surprised when I saw O(nC3) solutions could pass. Maybe this is the reason why they wanted to extend the time limit a bit (which ultimately caused asymptotically slow solutions to pass).