


Hello CodeForces Community!
I am glad to share that HackerRank's World Codesprint #4 is scheduled on 23-July-2016 at 4pm UTC. Contest duration is 24 hours.
You can win up to $2000 Amazon gift cards/bitcoins, medals and t-shirts. [Note: Winners from US and India will receive Amazon Gift Cards. Winners from other countries will receive equivalent USD amount in bitcoins.]
The problems were prepared by zemen, ma5termind, forthright48, allllekssssa, tunyash, shaka_shadows, and nabila_ahmed. Thanks to wanbo, malcolm for testing and pre-solving the challenges. Special thanks goes to allllekssssa who helped a lot to prepare the problem-set.
The contest will be rated. If two person gets the same score, the person who reached the score first will be ranked higher.
Update: Scoring 15-25-40-50-60-75-75-90
Update: The contest has ended, congratulation to the winners:
Update: We regenerated the leader-board as the updated score wasn't reflecting after rejudge. There is a slight change in top 10 as ecnerwala moved up, but luckily the set of people didn't change.
Let us your opinion about the contest!
Happy Coding!







Unfortunately coincides with TCO 3A (starts at 19-00 too)
Thanks for mentioning me twice :P
It is first round where I have my task after Game Theory contest. Also I was trying to help in selecting some problems and scoring, I believe at the end we made the best possible decision :)
I have full view about all problems except the last. For me, problemset is pretty interesting and solvable. I would put it in the top of CodeSprints, near April contest.
Enjoy in round !
Great problemset. I specially liked "Ticket to Ride".
I finished the first two easy problems in two minutes, and I was too stupid to do the rest! :P
That aside, really quality problemset; I thought long and hard about #3 and #4 and they were very challenging (but fun) for me to attempt.
Glad to know that you liked it. Don't forget to check the editorials of the problems you couldn't solve :).
Nice problems as always. But I'd like to highlight some issues.
Build a Palindrome was rejudged, probably because tests didn't satisfy the limitations from the statement. I know, because I wasted some time looking for a bug, then just doubled the constants and got AC. But the issue is that some people lost points after the rejudge. I woke up to find myself one place higher, this means some people lost their place and had to resubmit. This didn't change the top3, but what if it did?
Tests for the last 4 problems allowed me to get full points with suboptimal solutions. I believe it's not hard to create tests where they all would get TLE. But there was no reason to waste time on writing the correct solutions if slower ones pass anyway. I would be happy to see more tests designed against slow alternative solutions.
Thanks for your feedback. I am sorry that we had to rejudge the problem. But luckily very few contestant's rank got affected after the rejudge and top-5 didn't change.
Hope that you enjoyed the contest :).
Mine rank was affected by the first rejudge of Build a Palindrome. My accepted solution got RE verdict on last 4 tests. After you fixed tests second time, my first solution passed, but it still shows the wrong time in the leader board.
We are re-generating your rank, your first accepted solution will be counted.
Update: It's updated now, you moved up one rank. I am again sorry for the trouble, but your rank isn't affected anymore.
Thanks for feedback, honestly I like this longer comments more :P
I didn't test any task, and I can not talk a lot of about testcases — but I will do it in some next comment. I would ask you about problem with testdata in fifth task? I made solid effort to construct good testdata, also I didn't see some suboptimal solutions and I checked around 30.
My solution of Mining: O(KN2) DP that finds the minimum cost of splitting the first i mines into k intervals with the optimal pickup mine in each interval, plus another DP for the minimum cost if the pickup mine is the last mine (mine i). The values in each DP array can be calculated from the other one quite easily. Then, I made some optimisations like only considering k ≤ i and some breaks to avoid considering unnecessarily long intervals for large K. It's still O(KN2), but it passed easily. And an solution exists using Convex hull trick.
solution exists using Convex hull trick.
Initially, I found Build a Palindrome much harder — I saw the solution using suffix arrays right away, but didn't expect suffix arrays on 1 million characters to pass. I spent some time looking for a simple and faster solution, then decided to try my luck with suffix array and noticed that a constraint was added...
Nlog(n) or NKlog(n) ?
Yeah..I guess most passed submissions are O(kn^2) though..
There is solution for the task in complexity O(k N). I was talking with Shafaet and I wanted that only such solutions pass, but task has already tested and it would be bad to change something without tester and author — also I am not such expert to do it alone :P
Generally it is not too bad if solutions with such optimisations pass full testing system, it is not good but that ideas deserve more points then usual O(kN2) codes.
I hope you like problemset !
The solution with the convex hull trick can work in
O(N * K)for the Mining problem (that's exactly what I implemented during the contest).As it has the same complexity as the author's one, but seems to be easier to understand (in a sense that it requires only one non-standard idea), I will describe it briefly here.
Idea 1 (the only non-standard one, it is already described in a comment above):
1. Instead of computing one DP, we will compute two (one for the case when the last picked up mine is exactly in the i-th mine, and the other one for the case when the last mine is somewhere before it and all the mines up to i-th inclusively have been distributed).
The rest of solution is standard.
2. We can compute the cost of a
(l, r)segment in O(1) using prefix sums of weights and prefix sums of products of weights and coordinates. What is more important, the formulas we get (I will not write them here as they are rather long and only basic high school algebra is required to derive them, they are present in the code) show that for a fixedra transition from anylis a linear function (inx[r]for one DP andS[r]for another).3. We know how to support two operations: adding a new line and getting the optimal one for a fixed
xusing the convex hull trick. A pleasant part is that for both DPs, the coefficients are monotonically decreasing, andx's are monotonically increasing. Thus, we can just keep a deque of lines. It gives us a way to make a transition fromktok + 1in linear time.All the formulas are present in my code.
Really nice solution !
At first view it looks clear to me, but I must think about it more tomorrow, now I am really tired, despite I was only sitting and watching live stream :)
Well, my solution is something very close to O(N2) in most cases — the typical length of an interval in the optimal solution is around N / K, so there are O(NK) states and O(N / K) time for computations in each of them. Maybe something like N = 50000, K = 20 would break it. Otherwise, it should be very hard to find a countertest unless you're looking for a countertest to this specifically. (I hadn't even unrolled loops yet when it passed.)
In this case, if the polynomial part of the complexity is O(NK), it would have been better to only use a bound on NK and larger N. Partial scoring is good, but it should remain partial :D
The problems were okay, not very hard — I don't think I had serious trouble finding a solution for any problem this time, even the last one (unlike last time).
Yes, it is good optimisation for hacking testdata :) I like more system like this for receiving points then ACM and codeforces rules. In last time, always I had some little bug and my rating goes down :) Maybe good solution would be testing like Week of Code — having some pretests and having partial scoring, but final tests after round. Then many suboptimal solution will be hacked + nobody would know whether his 'hacking solution' will pass or not and must try to invent something better.
I have already said my opinon about problemset, I mentioned that for me tasks are solvable and interesting. Time of winner and amount of AC submissions show they had ok level. Maybe the last problem could be harder, but when I see top coders like it at most — I believe it is good too.
I would like to write one more comment about whole contest and after that I want bother you :)
I am pretty happy after this round. Final results, number of participants and things like it were perfect to me. I think you got harder problemset and time needed to solve all tasks is bigger. Also we had several interesting tasks for begginers and subtasks in other problems. I would like to write subtasks in third problem — they exist, but problemsetter didn't mention it in text.
First four problems are interesting to me, I spent around 1 hour to solve them. Maybe diffrence between third and second could be smaller, but I like third task and I think only possible postion for it is current.
I won't talk about my task, I hope at least you don't hate it :) I saw many other solutions for the task — someone found centroid, some guys used multiset etc. If your want to share your approache which is a little different then editorial I really wish to hear it!
Well I expected a little more good submissions for sixth task, I solved it till suffix arrays ( I done that part with KMP in complexity O(N2) ). And it looks standard to me... Normally it is very hard for coding, but also I expected that top coders have already finished codes for many parts of solution. There was some mistakes too in this task, but I think it didn't affect on final results a lot.
I like seventh task, I invented O(kN2) solution very fast and then it is Knuth optimisation. I said in previous comment more about the problem, it is really bad that testcases were a little weak, but every next optimisation deserves extra points — hacking testcases is also part of 1 day contest :P We are not talking about some brute force — it is not like sorting array from one of previous 101 Hacks.
Seems that people like the last task — I found it interesting, but I didn't spend a lot of time on thinking. It is really important to have quality last task — without it contest wouldn't be on this level.
Believe me, we chose the best possible problems for this round and also many good tasks stay for next contests ( so you can expect me at the top of list next time — I am sure I will win t-shirt :P ).
For me it was pleasure to help this awesome team and watch battle for the win on such important contest !
See you next time :)
Can you explain the uradi function, i mean what the if else are for and why just having two values for each value of sub tree coins just the max and min in-times are sufficient , why not more.(question :balanced forest)
I hope you are not the same guy from HR who asked me the same question after contest xD
I said to him, I will read and explane it in more details tomorrow ( I am very tired + I saw, done, test and invent a lot of tasks after it — I have no idea what I was doing before 1 month :D).
I think reason is the next :
long long p=(sum-c[x].s)/2 >= (sum — sum/3)/2 >= sum/3.
So we can not have more than two other nodes with sum p (otherwise total sum would be greater than it is). One node must have minimum visiting time and other must have maximum visiting time, so it is enough to check only these two values.
Thanks for your response, take your time i think the 50% score part is a bit obvious , at sometime( whenever you are free) just explain the ifs in a single sentence ( a one line explanation for all is highly welcomed) in your uradi and do_it functions.BTW nice editorial.
As I promised, I will explane in more details both functions. I hope other parts like basic dfs (where we are finding ma[$x$] and mi[$x$] — nodes with maximum and minimum visiting time where sum of all coins in subtree is equal to x) and separating cases and checking special case are clear to everybody — otherwise you should read editorial again.
Function uradi:
Si ≤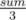
In this case we are adding new node in subtree of i. Thing which I mention in above comment is the most immportant.
Values p is denoting amount of coins in each of three trees after cuting. It must be eqaul p ≥ sum — where sum is denoting total amount of coins in initial tree.
sum — where sum is denoting total amount of coins in initial tree.
From that reason we can not have more than two nodes with values p and two nodes with value p+Si , so it is enough to check only maximum and minimum value of visiting time — there is no node with time between it.
Ifs after it checking all case carefully — first whether exists node with such sum and after it whether such node is different than current node(i) in first case and whether that node is parent of i in second case.
Function do_it:
In this case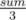 ≤ Si ≤
≤ Si ≤ 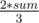 . Value add denotes value which we must add in tree so that cutting is maybe possible and we won't add that node in subtree of node i (subtree which we are checking).
. Value add denotes value which we must add in tree so that cutting is maybe possible and we won't add that node in subtree of node i (subtree which we are checking).
First if is checking whether they are one more node with value Si, then it is obivious we can cut our tree (all this parts would be much harder in case that is possible Ci = 0, now we can have only two such nodes in this part and part above with value p).
Second and third ifs are checking case whether exists some node j with sum Sj=Si — add which is not in subtree of current node i. In that case it is possible to cut our tree again. We can check only nodes with maximum and minimum time from next reason: in case both nodes are in subtree rooted in i then all other nodes with that value must be also in the same subtree.
And last if is for checking case when second edge which we are cutting is on the path from node 1 to node i — value of second 'important' node is bigger or equal than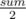 , so it is unique in tree.
, so it is unique in tree.
I hope now it is more clear what I was doing in my approache. As I said before this part can be done on some other way, it depends of programmer decison — but the most guys were using maps and multiset.
Can you explain the other approach you mentioned -we can sort that values and use binary search. What would we do in the case of ancestor (I thought of storing parents of 2^k, but that would get messy)?
It is totally same approache as approache above, only we don't have to use map for storing values. We can sort nodes first by sum of coins in subtree and after it by visiting time. Then we can apply binary search for finding ma[x] and mi[x]. All other parts are the same.
I really would like to hear some other approache, I saw many ideas (codes) which can be interesting :)
How to view other's solutions on hackerrank?
Still awaiting a reply.
What is the author solution for "Ticket to Ride"? I've solved it with centroid decomposition + lazy segment tree. Maybe there is another one more beatiful solution?
I solved it with only segment tree with lazy propagation. I only traversed the tree.
I was trying to solve the Short Palindrome question:
link: https://www.hackerrank.com/contests/world-codesprint-5/challenges/short-palindrome
What i basically did was that first i found the frequency of all charcaters of the string and those characters whose frequency is greater than 4(say x) i simply did xC4. This would take care of same characters case.Then for two different characters i maintained an array of pre[26][1000006] where pre[i][j] means in the string upto first j characters what is the frequency of i.I also maintained a vector of all positions of each character, then i fixed the first character as the end and then fixed the second character as the middle two.For calculating the number of valid string i simply queried the number of different string of second character between the positions of first character(let it be y) , also for the first character the number of words before and after the two positions including the positions.then set(a,b,c,d) can be found by (after*before)(for a and d) and (yC2)(for b,c)
This approach is passing some cases and failing some cases.Can someone suggest the flaw in my code.
xC4 value might be greater than range of long(in java). Did you take care of that?
Here is the link to my code..Please someone at least tell me the flaw as i am unable to get my mistake : https://ideone.com/E19cGY
When shall other's solutions shall be unlocked? :)
It's unlocked now.
Could you guys highlight more on how the elo ratings are going to be considered? As of now, some of us have a graph with one contest. Are the previous ones not going to be considered?