


→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 151 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Dec/23/2024 07:51:50 (k2).
Desktop version, switch to mobile version.
Supported by

Are you sure? clist.by says that it will be day later.
EDIT: sorry for the mistake.. I am extremely sorry. I am changing it...Those who actually saw the message I apologize.
It is impossible for me to check every timezone and then get a lower bound of time upon crossing which this list is will be true for everyone. This solely serves the purpose of a reminder and also a blog for discussion of the competition problems as the editorial is published quite late over there. As far as I know the time is shown correctly. What else do you guys want?
So I set the alarm for 3:30 AM (the contest starts at 4 AM in my timezone). Turns out I woke up and shut down the alarm and returned to sleep. Then in the morning I was very upset that I missed it. Next thing I find out that the contest is tomorrow. Yay! :D
hey sorry for that... I will do it more carefully from now on. I have really a lots going on in my life ... well I know that doesn't mean I can put wrong time... I apologize to everyone.
Calm down, you're overreacting. Just because people downvote a post you make doesn't mean they hate you. And I'm pretty sure tweety's post was made to cheer you up because things worked out in the end.
^ He's right, of course
Yeah it is a day later. See here. Click on 'Click here to see when coding begins in other time zones.'
1.5 hours before the contest starts. Go register.
People are too lazy. Looks like one of the lowest participation recently :(
Starts in 10 minutes :)
what is the solution logic of div2(c)?
Use breadth first search and bit mask.
Use a map to index each undecided edge to a number from 0 to k - 1.
Consider all possible subsets of nodes [pow(2, 20) of them] and see if each of them forms a clique taking into consideration both the decided and undecided edges.
If a certain subset does indeed form a clique push it into a vector of pairs, the pair being the size of the clique and an integer whose ith bit is set to 1 if the ith index corresponds to an undecided edge found in the clique.
Sort this vector and then iterate through it from biggest to smallest clique size.
Run bfs on each secondary value — the one that contains information about what the undecided edges needed to form it are, if it has not been visited.
For each clique you know that forming it could also include other undecided edges unrelated to it. So iterate through i from 0 to k and OR the current integer with (1 << i). Therefore insert these values into the bfs queue if they haven't been visited by a larger clique size previously.
Every time you visit a value in the current BFS you would add the size of the current clique to the total.
Each subset of undecided edges gets visited once, so time complexity is pow(2, k) * k.
In Div2 500, what will be the answer for
3 5 7
3 5 7
2 3
AC code are giving 1 but according to me it should be 2?
EDIT --> Answer is 1 but this code passes system test but fails on above testcase
1 is the right answer. What happens is 3 is stickied on A[0] i.e on 3. So only 2 causes a conflict . Hence ans = 1 conflict
This is a new low for lack of discussion about the contest :( Maybe it is because all the Russians were asleep for the contest?
I hate to complain, but what is the point of samples? I know topcoder is notorious for its weak samples, but the samples on the div1 500 seemed especially weak. For the div1 500, I failed because I compared against 0 rather than '0'. None of the samples had a '0' that wasn't on the diagonal, and any such sample would have caught this mistake. I think this is an example of particularly weak samples because it explicitly doesn't cover one case of the problem (i.e. the case when an edge is not present). I thought samples should just be a quick sanity check on correctness, and should generally catch mistakes like this.
This is more of an open question, but what should be the general philosophy behind constructing sample cases?
For all tasks samples are designed to show the input/output format, and be a quick sanity check on the understanding of problem.
For some tasks, they are just not designed for checking correctness (for example, case analysis tasks).
Unlike pretest in codeforces, you could see what's in the examples. So in this task we are telling you "please check correctness by yourself." clearly.
Sometimes adding a seemingly strong test may cause experienced contestant to fail, for example: sadly tourist failed Medium in TCO15 semifinal while there is a very strong example.
"and should generally catch mistakes like this." : from my experience, there is always a way to fail even there are few strong examples. Bugs are very random so it is hard to predict what it could be before we see it. So please read your program again and make some testcases by yourself if you want to avoid bugs (If you watch Petr's video you could find he always do it, sometimes after submission).
Btw, if I were the writer I would like to include large random testcases in this particular task, but it is also acceptable for me to leave it weak if the writer wants. In Div1-Easy I suggested to add a strong example because there are lots of wrong algorithms.
We can find on TC website that in this round: Small one's Success rate is 37.12%, Medium is 24.14%, Large is 0%. Is it truly intended? Personally, I think keep success rate in a reasonable range seems reasonable. Spend lots of effort and have ~ 70% chance to get 0 point just doesn't seem that cool.
You have to wonder how many of those Easy submissions are actually solutions to the problem, and not just desperately submitting any algorithm that passes samples hoping that it's correct (I'm not blaming anyone; that's what I do when I can't solve a problem, too!). If you coded the correct algorithm it was really hard to get it wrong and all samples right.
Medium's success rate is indeed a tad smaller than I would expect, though.
How to solve Div.1 550? After the contest I googled and submitted 2k bruteforces (it even works for 1.9 s), but I certainly do not think that it was an expected solution.
I completely don't understand the difficulty of this task. It looks like "Hey, bruteforce 2^10 assignments of '?' to '0'/'1' and find maximal clique in graph with 38 vertices as you want". Even if we forget that most difficult part of this problem (finding clique) can be copypasted from... anywhere, coding from scratch clique finding doesn't worth 550 pts.
I get AC with simple bruteforce: let's find anticlique. Take vertice with maximal degree, and take it to anticlique (and not take all it's neighbours), or don't take it to anticlique. If there are only vertices with degree <= 2, it is set of paths and cycles and we can calculate answer in linear time. Complexity -- T(n) <= T(n-1) + T(n-4) <= 1.38n (multiplied by 210), which passes easily. Also, there are very weak tests, I had to resubmit because I find stupid bug, but even my first bugged solution get AC.
You can do it in O(2n / 2n) using meet-in-the-middle.
- Split vertices in two equal (almost equal) parts in such way that all ?-edges goes in the first part.
- For each subset of the second part find largest clique, contained in this subset. This can be done in O(2ss), where s is the size of the part. Probably even O(2ss2) would pass.
- For each subset of the first part that contains only ?-edges and 1-edges, we can find largest clique in the second part connected to this.
- So, we will have bunch of implications of the form "if subset S of ?-edges is taken, largest clique is at least x"
- Using this, we can find in O(2ss) (or O(3s)) for each subset of ?-edges size of larges clique.
- Sum up this.
P.S. I think it is a nice task. Sad that brute-force solution passed. Probably author didn't want to cause TL problems for intended solutions.
I agree it's a nice solution, but it's a questionable task because bruteforce has almost the same complexity, and I'm sure they wouldn't have used it if they had realized this.
It's not the first time this happens, for example most problems with n sqrt n log n solutions turn out to be unusable tasks because the n^2 bruteforce is almost always faster.
Really? What's complexity of bruteforce?
I think, in this case the problem doesn't fit for topcoder format. Like, huge multitest allow to separate solutions more accurately. Also one can change the statement and give more ?-edges.
But number of ?-edges needs to be at most n/4 for that solution to work.
Yeah, I know. I mean, came up with something like "all ?-edges will form a tree". Rather awkward, but bettern than brute-force passed.
The worst case of Bron-Kerbosch is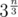 , but you can optimize it to something like
, but you can optimize it to something like 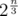 , getting a 20.58n algo, very close to the intended solution.
, getting a 20.58n algo, very close to the intended solution.
This isn't even the best complexity known for maximum clique, as wikipedia mentions one with 20.25n conplexity, and this is assuming all algorithms perform at the worst case in all runs, which unless a very specific case can be constructed means all versions are faster in practice, even vanilla Bron-Kerbosch.
How to solve div1 300?
Simulate the process backwards
Here is another simple solution (by the writer subscriber):
Lol, was there a rejudge of that contest? I submitted easy and hard, but my hard failed systests, so I ended up at 29th position. I searched for a bug in my hard for some time after contest, but couldn't find it. Now I entered that SRM stats and it shows me that my hard passed system tests and I ended up at 2nd position being the only one to solve hard o0 (there were 2 submissions).
Yes, we rejudged all solution to Div1-Hard and you passed system test. Congratulation! Somehow the reference output was wrong (it was generated by an old solution).
Btw, how to solve hard?
Bruteforcish dynamic programming. What information do we need from a subtree? Important information for us is whether we can obtain a prefix of our substring of length k if we go form some descendant up to root of subtree and whether we can obtain suffix of length k if we go from root to some descendant. For every mask of 2s bits (where s is length of our string) keep count how many subtrees correspond to that state. And then combine them (note how important here is assumption that our string doesn't have two consecutive equal letters). We should not keep states with count 0, which reduces number of states from 4s to 3s (I used unordered_map). We can combine states in bruteforce way which will result in (3c)s complexity which c is some weird constant with square roots between 2 and 3 resulting from unraveling recurrence, but it can be sped up to 22s if we use fast subset convolution (more precisely we need cover product). To combine substrees I used bruteforce way and was a little afraid of fitting into TL, but it seems it was enough.