


Большое спасибо Seyaua за помощь с переводом разбора.
Div. 2 A — Витя в деревне
Идея: _XuMuk_.
Разработка: _XuMuk_.
Нужно аккуратно разобрать несколько случаев :
an = 15 — ответ всегда DOWN.
an = 0 — ответ всегда UP.
Если n = 1 — ответ -1.
Если n > 1, то если an–1 > an — ответ DOWN, иначе UP.
Итоговая асимптотика: 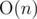 .
.
Div. 2 B — Анатолий и тараканы
Идея: _XuMuk_.
Разработка: _XuMuk_.
Заметим, что у нас может быть только две конечные раскраски, удовлетворяющие условию задачи: rbrbrb... или brbrbr...
Переберем раскраску, в которую мы хотим превратить нашу шеренгу.
Посчитаем количество рыжих и черных тараканов, стоящих не на своих местах. Пусть эти числа x и y. Тогда очевидно, что min(x, y) пар тараканов нужно поменять местами, а остальных — перекрасить.
Другими словами, результат для фиксированной раскраски — это min(x, y) + max(x, y) - min(x, y) = max(x, y). Ответ на задачу — это минимум среди результатов для первой и второй раскрасок.
Итоговая асимптотика: .
Div. 1 A — Ефим и странная оценка
Идея: BigBag.
Разработка: BigBag.
Заметим, что оценка будет тем выше, чем в более старшем разряде мы ее округлим. Используя это наблюдение, можно легко решить задачу методом динамического программирования.
Пусть dpi — минимальное время, необходимое для того, чтобы получить перенос в (i - 1)-й разряд.
Пусть наша оценка записана в массиве a, то есть ai — i-я цифра оценки.
Существует 3 случая:
Если ai ≥ 5, то dpi = 1.
Если ai < 4, то dpi = inf (мы никак не сможем получить перенос в следующий разряд).
Если ai = 4, то dpi = 1 + dpi + 1.
После того, как мы посчитали значения dp, нужно найти минимальное pos такое, что dppos ≤ t. Так мы узнаем, в какой позиции нужно округлять наше число.
После этого нужно аккуратно прибавить 1 к числу, образованному префиксом из pos элементов исходной оценки.
Итоговая асимптотика: .
Div. 1 B — Алена и ксероксы
Идея: _XuMuk_.
Разработка: BigBag.
Появится позже.
Div. 1 C — Саша и массив
Идея: BigBag.
Разработка: BigBag.
Вспомним, как можно быстро находить n-e число Фибоначчи.
Для этого нужно найти матричное произведение: 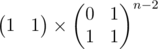
Чтобы решить нашу задачу, заведем следующее дерево отрезков: в каждом листе, соответствующему элементу i будет храниться вектор 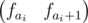 , а во всех остальных вершинах будет храниться сумма всех векторов, соответствующих данному отрезку.
, а во всех остальных вершинах будет храниться сумма всех векторов, соответствующих данному отрезку.
Тогда для выполнения первого запроса нужно домножить все векторы на отрезке от l до r на 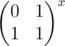 , а для ответа на запрос просто найти сумму всех векторов от l до r. Обе эти операции дерево отрезков умеет выполнять за
, а для ответа на запрос просто найти сумму всех векторов от l до r. Обе эти операции дерево отрезков умеет выполнять за 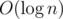 .
.
Итоговая асимптотика: 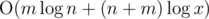 .
.
Div. 1 D — Андрей и задача по химии
Идея: _XuMuk_.
Разработка: BigBag.
Поймём как решать задачу за 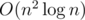 :
:
Выберем вершину, к которой мы будем добавлять еще одно ребро. Подвесим дерево за эту вершину. Проставим каждой вершине vi метку a[vi] (какое-то число) так, что вершинам с одинаковыми поддеревьями будут соответствовать одинаковые метки, а разным – разные.
Это можно сделать следующим образом: Заведем map<vector<int>, int> m (т.к. максимальная степень вершины 4 — длина вектора всегда будет равняться четырем). Теперь m[{x, y, z, w}] будет хранить метку для вершины, у которой сыновья имеют метки x, y, z, w. Отметим, что вектор нужно хранить в отсортированном виде, а также если сыновей меньше 4, то отсутствующим вершинам ставим метку - 1.
Давайте поймем, как можно посчитать метку для вершины v. Посчитаем рекурсивно метки для ее сыновей v1, v2, v3, v4. Тогда если m.count({a[v1], a[v2], a[v3], a[v4]}), то в вершину v нужно поставить соответствующую метку, иначе — первое еще не использованное число, т.е. m[{a[v1], a[v2], a[v3], a[v4]}]=cnt++.
Теперь выберем другую вершину, к которой будем добавлять еще одно ребро. Подвесим дерево за эту вершину и расставим метки, при этом не обнуляя счетчик (cnt). Затем проделаем эту операцию со всеми возможными корнями (n раз). Теперь поймем, что если корням соответствуют одинаковые метки, то деревья, полученные путем добавления дополнительного ребра к этим корням, одинаковые (изоморфные). Таким образом нам нужно подсчитать количество корней с различными метками. Так же нужно не забыть, что если у корня степень вершины уже 4, то новое ребро в этот корень добавит невозможно.
Описанное выше решение будет работать за , т.к. мы рассматриваем n подвешенных деревьев и в каждом дереве пробегаем по всем n вершинам, расставляя метки в map за  .
.
Теперь поймем, как ускорить это решение до  .
.
Заведем массив b, где b[vi] — это метка, которую необходимо поставить в вершину vi, если подвесить дерево за эту вершину. Тогда ответом на задачу будет кол-во различных чисел в массиве b.
Подвесим дерево за вершину root и подсчитаем значения a[vi]. Тогда b[root] = a[root], а остальные значения b[vi] можно подсчитать, проталкивая информацию сверху вниз.
Итоговая асимптотика: .
Div. 1 E — День рождения Матвея
Идея: BigBag.
Разработка: BigBag, GlebsHP.
Докажем, что расстояние между любыми двумя вершинами не превосходит MaxDist = 2·sigma - 1, где sigma — размер алфавита. Рассмотрим какой-нибудь кратчайший путь от позиции i до позиции j. Заметим, что в этом пути каждая буква ch будет встречаться не более двух раз (т.к. иначе можно было бы просто перепрыгнуть с первой буквы ch на последнюю и получить более короткий путь). Таким образом общее количество букв на пути не более 2·sigma, следовательно длина пути не превосходит 2·sigma - 1.
Пусть disti, c — расстояние от позиции i, до какой-нибудь позиции j, где sj = c. Эти значения можно получить с помощью моделирования bfs для каждой различной буквы c. Моделировать bfs довольно легко можно за 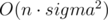 (над этим рекомендуется подумать самостоятельно).
(над этим рекомендуется подумать самостоятельно).
Пусть dist(i, j) — расстояние между позициями i и j. Поймем, как находить dist(i, j) с помощью заранее подсчитанных значений disti, c.
Рассмотрим два принципиальных случая:
- Оптимальный путь проходит только через ребра первого типа (между соседними позициями в строке). В этом случае расстояние равно
 .
. - В оптимальном пути есть хотя бы одно ребро второго типа. Пусть это был прыжок между двумя буквами типа c. Тогда в таком случае расстояние равно disti, c + 1 + distc, j.
Суммируя эти два случая получаем, что 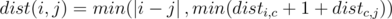 .
.
Исходя из этого, уже можно написать решение, работающее за 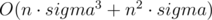 . То есть можно просто перебрать все пары позиций (i, j), и для каждой пары обновить ответ расстоянием, полученным по описанной выше формуле.
. То есть можно просто перебрать все пары позиций (i, j), и для каждой пары обновить ответ расстоянием, полученным по описанной выше формуле.
Поймем, как можно ускорить это решение.
Будем перебирать только первую позицию i = 1..n. Для всех j таких, что 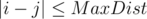 , посчитаем расстояние по выше описанной формуле.
, посчитаем расстояние по выше описанной формуле.
Теперь нам нужно для фиксированного i найти max(dist(i, j)) для 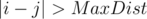 . В этом случае dist(i, j) = min(disti, c + 1 + distc, j).
. В этом случае dist(i, j) = min(disti, c + 1 + distc, j).
Для этого посчитаем еще одну вспомогательную величину distc1, c2 — минимальное расстояние между позициями i и j такими, что si = c1 и sj = c2. Это можно легко сделать, используя disti, c.
Нетрудно заметить, что distsj, c ≤ distj, c ≤ distsj, c + 1. То есть для каждой позиции j мы можем составить маску maskj из sigma бит, i-й бит которой равен distj, c - distsj, c. Теперь расстояние можно однозначно определить, зная только sj и maskj.
То есть сейчас distj, c = distsj, c + maskj, c.
Будем поддерживать массив cntc, mask — количество таких j, что , sj = c и maskj = mask. Теперь вместо того, чтобы для фиксированного i перебирать все возможные j, можно перебирать только пару (c, mask), и если cntc, mask ≠ 0, то обновлять ответ.
Итоговая асимптотика: 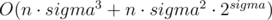 .
.






Небольшие советы по оформлению:
A \times B: A × B,A \cdot B: A·B,\relax A \times B:O(n \log n):Спасибо, еще бы узнать как матрицы нормально рисовать :)
Прямо скажем, следовало бы отметить, что в задаче Div2 E (Div1 C) не проходит просто дерево отрезков с умножением на отрезке (на соответствующую матрицу в степени) и подсчетом суммы.
Я взял отличную реализацию дерева отрезков от VEpifanov, совместил с быстрым возведением в степень для матрицы 2 на 2, делая умножение обычным всем известным способом за (2^3 * log2(DEGREE)) операций, и это получает TL на 16 тесте. Если поужимать код везде, кроме умножения матриц, то смог пробить до 18 теста, но там точно TL.
И вы не поверите, но чтобы запихнуть эту задачу приходится ужимать код по умножению матриц. И плюсом к этому вы ещё и баллы за нее уменьшенные сделали, типо простая задачка, даже TooDifficult получил TL на 17-м тесте. По-моему, жюри, вы неправы.
Вот моя посылка — TL 18. Скажите, что здесь можно улучшить КРОМЕ умножения матриц, чтобы решение получило AC?
Так у тебя же асимптотика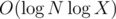 на запрос, а надо
на запрос, а надо 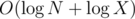 . Внутри дерева отрезков не должно быть никаких быстрых возведений в степень. Мы один раз, когда получили запрос, считаем матрицу Ax и дальше выполняем обычное домножение на эту матрицу на отрезке в ДО, и соответственно проталкивать нужно не x, как делаешь ты, а Ax. 20859980
. Внутри дерева отрезков не должно быть никаких быстрых возведений в степень. Мы один раз, когда получили запрос, считаем матрицу Ax и дальше выполняем обычное домножение на эту матрицу на отрезке в ДО, и соответственно проталкивать нужно не x, как делаешь ты, а Ax. 20859980
Аааа... ну понял. Так в разборе об этом не написано. Это такой очевидный факт? Почему задача идет как упрощенная ?
Та вроде как очевидный. Даже в твоем сообщении написано: "не проходит просто дерево отрезков с умножением на отрезке (на соответствующую матрицу в степени)". Зачем усложнять себе жизнь и проталкивать степень, а не готовую матрицу в степени? И в разборе написано, что домножать надо на Ax.
Да просто хотелось поменьше информации хранить в вершине дерева отрезков, а то немного перегруженная вершина получается :)
Спасибо за совет, попробую реализовать именно так, как Вы сказали.
Я проталкилвал степень, но для быстрого вычисления степени матрицы делал предвычисления.
Спасибо, Жень. Помогло)
Боюсь спросить по Div. 2 A Разве всегда при n=1 ответ будет -1? Например если ai = 0, и это единственный элемент, то разве ответ не будет UP?
Да, ответ будет UP. Но это не противоречит разбору задачи. Там случай, когда An == 0 разобран раньше проверки N == 1.
Написано, что если an = 0, то ответ всегда UP и если an = 15, то ответ всегда DOWN. В случае, когда n = 1 как раз получается, что an = 0.
Ну я и говорю, что сначала проверка An==0, а потом проверка про N == 1, что всё в порядке
Подскажите, а по задаче Div1 (C) не предполагалось прохождение по времени решения за O(M*log(N)*log(DEGREE)*8) ? Почему?
Например потому что это капец медленно? У меня и без лишнего логарифма работает секунды 3.
Да, это понятно, но получается, что задачу можно было решить ТОЛЬКО за O(M*(log + log)) и по-другому нельзя, т.е. ровно 1 способ решить задачу на структуры данных, обычно то ведь разбег дают какой-то, например, SQRT декомпозиция, ещё что-нибудь, асимптотики разные подходят, а тут нет, да еще и цену за задачу понизили, типо простая )))
ну почему ровно один. Можно то же самое делать декартовым деревом. Или еще каким-нибудь деревом.
У вас какие-то странные претензии. Ваше решение медленное и поэтому оно не заходит. Конец.
Никто не должен позволять заходить разным решениям. Это какие-то фантазии.
Да нет, ну просто у меня нормальный опыт по структурам данных (я участвовал в 2-х финалах ЧМ) и за полтора часа я так и не сдал эту задачу, и не считаю, что она должна расцениваться как упрощенная.
Ну а я математик, я писал ДО сам, а не копировал его, и я сдал эту задачу за 25 минут. Может, вы не так хороши?
Есть адекватный способ оценить сложность задачи. Посмотреть на кол-во AC. Задачу на контесте сдали 142 человека. Думаю, это сильно больше, чем на среднем раунде.
В конце концов, стоимость задачи важна только внутри контеста. Нет особого смысла сравнивать стоимости задач разных контестов.
Видимо, на вопрос по задаче D от -XraY- нет ответа в разборе. Как показать, что две новые вершины обязаны переходить друг в друга при любом изоморфизме?
Возможно, конечно, подразумевается, что этой вершинке соответствует единственный хлор. Но в формальной модели (которую, очевидно, использовали 99% участников) об этом ничего не сказано.
Да, конечно, использовалась формальная модель. Мы не включили этот момент в разбор, т.к. доказательство довольно громоздкое, но надеюсь оно хотя бы правильное в отличии от задачи div.1 B :) Сейчас постараюсь вкратце объяснить.
Выберем две вершины v1 и v2, к которым будем добавлять новое ребро. Очевидно, что если b[v1] = b[v2], то деревья будут изоморфны. Теперь докажем, что если b[v1] ≠ b[v2], то деревья — не изоморфны.
Предположим обратное, то есть что деревья все-таки изоморфны. Это значит, что можно подвесить второе дерево за какую-то вершину v3 степени 1 (пусть единственное ребро из нее ведет в вершину to) так, что деревья будут одинаковы относительно корня v1 и to. Удалим из первого дерева ребро (v1 - new), а из второго — (v3 - to) (после этой операции деревья по-прежнему останутся одинаковыми).
Заметим, что полученное первое дерево является исходным, а второе — исходным с заменой ребра (v3 - to) на (v2 - new). Обозначим исходный граф G. Получается, что G = G - (v3 - to) + (v2 - new). Преобразуем это равенство. G - (v3 - to) + (v3 - to) = G - (v3 - to) + (v2 - new). Пусть G' = G - (v3 - to). Тогда G' + (v3 - to) = G' + (v2 - new). Докажем, что в графе G' будет иметь место равенство b[to] = b[v2]. Заметим, что в G' уже n - 1 вершина. То есть по сути, чтобы доказать, что b[to] = b[v2], нужно доказать тоже самое, что мы доказывали для исходного графа (т.к. к G' также добавляются 2 новых ребра). Только в данном случае размер графа стал на 1 меньше. То есть можно вот-так бесконечно спускаться, пока n > 1. Для n = 1, это равенство, очевидно, выполняется. Таким образом мы доказали, что b[to] = b[v2].
Если теперь (после удаления ребра (v3 - to)) добавить ребро (v2 - new), то по предположению будет выполнятся равенство b[v1] = b[to]. Из этих двух равенств получаем, что b[v1] = b[v2]. Противоречие.
У меня на Е была такая идея была построить ДО где в вершине будет хранится
сумма всех f(a[i])сумма всех f(a[i] - 1)сумма всех f(a[i] + 1)ну сначала мы их просто посчитаем, а потом как обычное ДО с добавлением на отрезке, а пересчитывать будем по формулеf[n + m] = f[n + 1] * f[m + 1] - f[n - 1] * f[m - 1]если посмотреть для отрезка выйдет
f[m + 1] * (f[l + 1] + f[l + 2] + ... + f[r + 1]) - f[m - 1] * (f[l - 1] + f[l] + ... + f[r - 1])ну то есть грубо говоря два числа фибоначчи помноженное на суммы которые у нас уже есть, а что бы пересчитать те суммы мы будем добавлять не m, а m — 1 аналогично добавим m + 1. Что я упустил?Editorial Div 1 C: "Now, to perform the first request we should multiply all the vectors in a segment [l..r] by and to get an answer to the second request we have to find a sum in a segment [l..r]."
Care to elaborate this please ? How to multiply all the vectors in segment [l..r] keeping time complexity low?
You need to use segment trees with lazy propagation, you can read about them here.
http://codeforces.net/blog/entry/15890
DIV 1C:
I don't know much about Fibonacci number's properties. For this reason I can't understand the following statement.
to perform the first request we should multiply all the vectors in a segment [l..r] by A^x
Can anyone please explain how the idea works? or any resource to learn this kinds of stuffs. Thanks in Advance.
Here
Div.2 B: Please, explain, how we can get answer 3 for this test step by step: rbbbrbrrbrrbb?
swap 3rd 'b' with 8th 'r' resulting in answer=1 swap 9th and 10th resulting in answer=2 and color last one with 'r' resulting in 3
Thanks, I got it. Unfortunately, I didn't understand statement right, considering that we can swap only adjacent chars.
I also misunderstood the same.
For some reason my solution for Div1D failed on test case 26 and I have no idea why it failed. Can someone help take a look at it please?
http://codeforces.net/contest/718/submission/20885319
UPD: Tried out some other implementation and this somehow worked... http://codeforces.net/contest/718/submission/20890359
Now I am even more confused. Why does using the mapped value of the vector as a key DOES NOT work while using the vector as a key work? I suppose they are the same, unless this somehow cheesed some test cases.
I don't know if this is related, but isn't
m1[hh[now]]=m1.size();undefined behavior? You're using the value of size() which might be modified by the indexing operation.I am not sure about this either, yet from my prior experience this returns the size value after the insert action is done.
I just tried to replaced those affects by a time value, yet it seems that something went wrong... I shall update after I get back to my own computer and run it with a debugger.
UPD: Okay, I just found magic. On line 47 there was an extra semicolon behind the if condition causing problems, so the hashed values are not necessarily correct, and the second version seem to cheesed through this flaw and made an shameful AC...
Now the mystery remains on what black magic made the first code survived that many test case and the second one got an AC.
Was anyone able to solve div 1 C in Java , I tried the same approach given in the editorial but it's exceeding time limit in test case 11 . What might be the possible reasons Submission
how to speed up my div2E solution? http://codeforces.net/contest/719/submission/20888238
basically:
i precompute all powers of 2 of the transformation matrix so, for example i want to get A^18, i just do A^16 * A^2
then for each node in the segment tree, i store the sum of the transformation matrix, so if i want to get the fibonacci sum of a node, i just multiply (1,1) with the matrix stored in the node, however im getting TLE, while i see the editorial has a similar approach (it stores the fibonacci matrix instead of the transformation matrix)
how to speed up my div2E solution? http://codeforces.net/contest/719/submission/20888238 basically: i precompute all powers of 2 of the transformation matrix so, for example i want to get A^18, i just do A^16 * A^2 then for each node in the segment tree, i store the sum of the transformation matrix, so if i want to get the fibonacci sum of a node, i just multiply (1,1) with the matrix stored in the node, however im getting TLE, while i see the editorial has a similar approach (it stores the fibonacci matrix instead of the transformation matrix)
It appears that 2*2 vectors are too slow for the task... I don't know the reason though — I just somehow cheesed out a solution after hours of trial and error, and I am still quite lost.
Just FYI, here are my codes:
http://codeforces.net/contest/719/submission/20889881
Uses 2*2 vectors for computation, TLE on test case 10.
http://codeforces.net/contest/718/submission/20890001
Uses two variables instead, clutches the TL 4926/5000
As a side note, when I didn't fixed the overflow problem, the vector implementation failed at test case 8 ~150ms, while the two variable implementation only used 15ms.
My solution uses transformation matrix gets TLE on test 11 . Can you say how can i optimise it. http://codeforces.net/contest/718/submission/20890160
Can you explain your method of two variables.
Again, I still don't fully understand how my optimization worked, so I am as lost as you right now, and I can't guarantee the correctness of my suggestions. If somebody has a clear picture please kindly lend some help. =]
Try not to use long long everywhere. Although that helps out a lot with handling overflow, but they are very slow, so use them only when you have to.
You are parsing the full matrix. Although it does not affect the theoretical time complexity, but considering that long long has a slower R/W speed and you are trying to cheese through the time limit, parsing the full matrix seems to be pretty slow.
Thanks for reply.BTW can you explain a bit your method of two variables.
Instead of keeping the whole matrix, I just keep Fn and Fn-1, that means I am only keeping half of the matrix.
You can precompute even more. You can split the exponent E into 4 parts, let's say E = a + 216b + 232c + 248d, where each a, b, c, d < 216. Then you precompute 4 tables of the forms:
Then to get ME you make 4 table lookups and three matrix multiplications.
Moreover, using e.g. Sage we can check the order of the matrix:
So actually we can reduce the exponent modulo 2000000016 < 231. Therefore it is enough to compute 2 tables instead of 4 and we can compute ME for any E with only 1 matrix multiplication.
20869723 see Exper class.
I implemented your idea using a modulus of 216 also I have changed most of my long variables to ints (except in multiplication) but still I am getting TLE at test 17 . Is it due to the creation of matrices . Submission
whats sage?
It is a python-based mathematical system. http://www.sagemath.org/
so your solution is basically decompose A^x to base 2^16, right?
Decompose the exponent (x in Ax) to base 216, yes.
Can you please have a look at my solution in the comment below?
i tried your method all night, still cant find my bug http://codeforces.net/contest/719/submission/20909753. i just added the extra precomputing method and changed the "dnc" fucntion to return a^x. i beleive the rest are correct, would you take a look please?
First, you store M2i in pp array. So pp[0] = M1, not M0. Then pp[1] = M2, etc. In the loop you then use x = 0.
Fixing this I still get TL in 18th test.
Then I changed vectors matrix to structure and it passed in 1.5 seconds: 20923387
Маленькая опечатка. div1C "Тогда для выполнения первого запроса нужно домножить все ..." "вЕкторы", а не "векторА".
Did anyone use transformation matrix and got accepted?
Editorial for problem D skipped the difficult part as this comment.
Sorry, I've already answered for this question in Russian, but not in English.
Let's pick two vertices v1 and v2 we're going to add edges. It's obvious, that if b[v1] = b[v2], then these trees are isomorphic. Now I'm going to prove that if b[v1] ≠ b[v2], then these trees aren't isomorphic.
Assume the contrary, i.e. that trees are still isomorphic. It means that the we can pick some vertex v3 with degree 1 (let's the only edge leads to the vertex to) in such way, that these rooted trees (at the vertices v1 and to respectively) will be equal. Now let's delete from the first tree edge (v1 - new) and from the second — (v3 - new) (after this operation the trees are still equal).
Note, that the first tree is our intial tree, and the second — intial tree with edge (v3 - to) changed to the edge (v2 - new). Let's define our intial graph as G. Now we have that G = G - (v3 - to) + (v2 - new). It means that after deleting an edge (v3 - to) the following will be true: b[to] = b[v2]. If now we add the edge (v2 - new), then by the assuming the following will be also true: b[v1] = b[to]. So we get that b[v1] = b[v2]. Contradiction.
I'm having difficulty understanding this part:
Why b[to] = b[v2]? Isn't this statement equivalent to what you were trying to prove in the first place?
I think you are right.
The statement is equivalent to (G - (v3 - to)) + (v3 - to) = (G - (v3 - to)) + (v2 - new), which is the same as the original statement.
However, we can obverse that |G - (v3 - to)| = |G| - 1. So induction completes the proof.
Could you explain your idea in div.1B? Although it is incorrect, I am still curious about your approach, as it may be special and I can learn something from it. Furthermore, it can help to fix your nistakes. So I think sharing this approach should be appreciated :)
I think the solution should be posted, and the problem put back on the website with the updated statement so people can still work on it.
In div2 C,I am not getting the first statement."One can notice that the closer to the decimal point we round our grade the bigger grade we get." Can anyone please explain it?
In every move we can round it off to any decimal point (wherever possible) . Hence, it makes sense not to waste moves at the far off ends (right end ) and instead make it closer to the decimal point as closer the number the decimal point the bigger is the number. e.g 1.225116 should be rounded to 1.23 and not 1.22512 in one move. That's why after calculating the dp array we take the leftmost dp[i] that is less than or equal to t.
my solution for div 2 problem B failed on test #7 , the reason of which i dont know. my solution procedure is same as of editorial. here's my code , please tell me what mistake i made
http://codeforces.net/contest/719/submission/20898465
You are changing the value of s[0] in every loop.
Someone please help , getting TLE on test 11 optimised from passing transformation matrix to fibonacci numbers as mentioned in editorial, then optimised further using ints . Please help http://codeforces.net/contest/718/submission/20898639
initially i was passing the complete transformation matrix and still was getting TLE on test 11
Someone please help me in optimising this code ,getting TLE on test 11 , initailly i was passing the complete transformation matrix and getting TLE on test 11 , then tried optimising it as mentioned in editorial by passing fibonacci numbers and then furthur by using ints ,still to fail on the same case.
http://codeforces.net/contest/718/submission/20898639
Someone please help!!
You are doing exponentiation on each lazy push which yields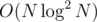 complexity (because exponentiation is
complexity (because exponentiation is  ). You have two options:
). You have two options:
optimize exponentiation as I mentioned before here so it becomes constant time (one or three multiplications);
or perform exponentiation immediately on query and store matrices in the "lazy" array.
can you explain a bit more the second method please?
We use matrix as a lazy tag(which is [0 1;1 1]^x).When we download the lazy tag, we just need to multiply it lazy tag with its father's lazy tag and change its father's lazy tag to [1 0;0 1](which is equal to E). Also we should record [f[a[n]-1] f[a[n]]] this matrix at each node. So when we do the query operation, we just need to calculate the sum of f[a[n]]. And when we do the change operation, we just need to calculate the [0 1;1 1]^x first, and then use it as a lazy tag.
THanks for your help but i am now caught in test case 28 here is my submission http://codeforces.net/contest/718/submission/20912507
i used fast input can you suggest more optimisation please?
In Div 2 C, I simply found the first digit after the dot which is >= 5 and then updated the marks. No dp, simple implementation. http://codeforces.net/contest/719/submission/20880366
Then b[root] = a[root] and all the other values for b[vi] we can get by pushing the information from the top of the tree to the bottom
What information specifically ? and how can we obtain values of b[i] for i != root in nlogn
So what we are doing are essentially similar to tree dp.
First you fix a root, run a dfs to get a[]. Since the the root is currently being considered, b[root] = a[root]. For other points, we have to move the root from a point to point. This involves three actions, assume that we are moving from node u(the current node) to node v(the new node):
This transfer process gets run by O(n) times, so that's O(NlogN) in total.
My code: http://codeforces.net/contest/718/submission/20890359
Refer to the "move" function for updating the root (i.e. pushing the information).
Div 2C/Div 1A (Efim and Grades) : Alternate Approach
Find the position of Decimal '.' and say it is dec . Now iterate from dec to end of the grade( stored as string) until we find a position where the digit is greater than or equal to '5' .
If no such position exits then print the string as it is. Else, reverse iterate from that position towards dec until we exhaust our seconds or the digit at consideration is not '4' . Round the grade at the position we stopped.
If we reached dec then the output should should be an integer, 1 greater than the integer part of input. That step is a well known operation.
Here's my code for further reference :
http://codeforces.net/contest/719/submission/20860189
same greedy approach here! 20863325
I want to solve (div.1B / div.2D)! Where can I submit it? I'm waiting for 3 days!
AFAIK you can't submit it, you can share your approach though — many are eager to know the correct solution as the greedy solution has a flaw.
My approach for that problem had 2 parts. The first part was finding the time where each machine starts working, the second part was finding the time for each query via binary search.
This solution has complexity O(M * NlogK), where K is the maximum time (1018 for one machine with ti = 109 and 109 sheets of paper). Certainly this solution wouldn't fit into the given time limit, but I'd still want to know whether it's correct or not.
UPDATE: As noted below, and as discussed previously, this solution is wrong.
This is the greedy variant, which most people assumed is correct (and the task authors too). See discussion why it's incorrect.
In short, "There will be always at least one paper available to work with" is wrong. Test:
Answer is 7 (greedy answer is 8).
Ahhhhh, I see! Thanks.
how to implement the div1 A using DP? I mean how to code the logic
Check this out 20928655
Div 1 A, alternate solution. Input number as a string, let's call it str. Scan str from the character after decimal point to end of number. Find the first character that is greater than or equal to 5. The position before this is where rounding off should be done. Eg — If no=3.13 3 523419, rounding should be done at the '3' in bold.
Now, multiple round-offs will be possible only if there is a chain of '4's before the first character >= 5. Eg — If no is 12.3444 4 5, then after one second it can be made 12.3444 5 , after another second it will become 12.344 5 until either time runs out, we exhaust all '4's or reach the decimal point.
After this step, wherever we reach, let's mark that index as 'x'. Now we need to round off from position x. To round off, keep moving backwards towards the beginning of number, increasing each '9' to '0'. Increment and break as soon as a non-'9' character is encountered. If beginning of str is reached, print 1 followed by modified number, else print modified number.
In Div1 C, This submission allocates only O(2*N) space for segment tree and also passes the system testing. Don't we need to allot O(4*N) space for segment tree? Solution
Imagine a function maxNode(x) of the number of nodes needed for segment tree, the first thing is that maxNode(x) is increasing, which is a little bit intuitive. So the next thing is the if N (the number of nodes) is a power of two the tree is perfectly balanced and the number of nodes in the segment tree will be exactly 2N - 1 so if MAXN is a power of two and is greater than any N that will be used i will be safe to use 2 * MAXN of size in the segment tree, since for any N < = MAXN the following expression will hold maxNode(N) < = maxNode(MAXN) = 2 * MAXN - 1. So know you know how to save memory ;)
Edit: As noted in the comments, in this explanation maxNode(x) should be the maximum index used (hence the size of the array it needs) in the "traditional" naive recursive segment tree used in the submission posted above.
Got it, thanks!
Actually, if F[N] is the number of nodes needed to construct a segment tree for N elements, then the equality F[N] = 2N - 1 holds for every N, not only for powers of two.
To prove it we can note that F[1] = 1 and F[2] = 3. The rest can be done by induction.
So, no matter the value of N, you can always go safe by setting the size of the tree to be 2N.
UPDATE: As noted by ffao below, while the tree will have size 2N - 1, there will be out of bounds violation when trying to access some children. Moreover, you won't be able to access all children intuitively by going to nodes 2i and 2i + 1. In other words, if you wanna be safe, always use powers of 2 as sizes. I always used powers of 2, so I never had these problems, but I'd never stopped to consider why we should use powers of 2 for the size.
Yeah it is true. I was referring to maxNode needed for maximum index used by the specific implementation he asked. Since what you demonstrate there doesn't prove why the posted implementation uses 2*N space.
To stress the point, "it is always safe to set tree size to 2N" is false, because even if your tree only uses 2N-1 nodes, indexing them in the intuitive way causes some of them to receive indices outside the 2N limit.
It's not false. I don't know what you mean by indexing them the intuitive way, but intuitive to me is indexing them from 1 to 2N - 1, such that the root is 1 and children of node i are 2i and 2i + 1, and that's clearly valid with an array of size 2N.
And here we have confirmation bias at its finest. When confronted with the opposite opinion, humans tend to hole up and defend their opinion to the death instead of, you know, trying to evaluate if the other person has any merit in what they're saying.
Luckily, unlike political stances this is an exact science, and I can prove you wrong.
Did you try doing the same thing as you did with 8 by listing the tree nodes, but with a number that isn't a power of 2, such as 18? I didn't think so, or you'd have seen the last index goes beyond 2*N.
Did you try submitting a solution that has an array of size 2*N? I also didn't think so, and I even did your work for you, here it is: 20952741. Look at that, runtime error, what a surprise!
Well, I think I gotta apologize... now I feel like an idiot.
Indeed, the tree will have 2N - 1 nodes, but not all the children will be at 2i and 2i + 1. For example, children of node 24 (range [10, 11]) will be at indices 34 and 35.
Sorry for being a jerk.
I might have overreacted a bit as well, I get a bit rattled when someone doesn't consider what new information might mean. So sorry about that, too.
This blog has a tutorial about how to implement a O(2*N) memory space segment tree in a very clean, abstracted way.
http://codeforces.net/blog/entry/18051
Why would we need O(4 * N) space for a segment tree? Consider this very simple example of what range each node of the tree represents, for a tree with 8 nodes.
T1 = [1, 8] T2 = [1, 4] T3 = [5, 8] T4 = [1, 2] T5 = [3, 4] T6 = [5, 6] T7 = [7, 8] T8 = [1, 1] T9 = [2, 2] T10 = [3, 3] T11 = [4, 4] T12 = [5, 5] T13 = [6, 6] T14 = [7, 7] T15 = [8, 8]
The same applies for other values as well. I like to work with powers of 2 for size, so I always allocate double the nearest power of 2 for segment trees.
Could someone help me why this[submission:20981794] TLE on test16?I thought this code time complexity was O(mlogn+(n+m)logx).so sad...
In Problem DIV2-B (Div. 2 B — Anatoly and Cockroaches)
I am getting a run-time error on test case 5. I have debugged the code, and don't see any reason for the error. Could it be because I am creating new strings?
Could anyone please help me out with this? Cannot understand why this is happening.
My code — code
You're creating empty strings and then trying to access indices from them. You should resize them or copy the content from the original string.
Here's the corrected code -> 20990040
Thanks a lot Tenshi!. Just a small doubt. My code then, shouldn't have worked on any test case, right? Why is it working for test cases 1-4?
I don't have much knowledge about compilers, but I'll try to explain what I think might be making your program work for small test cases.
s1ands2, you also declare 7 integers (28 bytes).s1and 13 bytes froms2, which your program already allocated memory for. You're overwriting other variables, I think.s1ands2to create stringsnew1andnew2, but in this step, you usepush_back, so your program allocates new memory and it works.new1andnew2, your program gives correct answer.I got it! Thankyou so much :)
Div. 1 C can be solved by sqrt decomposition. My solution passed by a tiny bit, and I had to cut down on the recalculation of fib(x) when answering queries of the second first type.
TLE Submission: 21113527 AC Submission: 21115015
Div1, C. Getting WA on TC 11 . I've checked the code like 50 times but not able to find mistake. Please help :O Code
Div 1C, I implemented a segment tree of nodes made of matrices and calculating fibonacci numbers by matrix exponentiation in log n (Also Lazy Propogation). The complexity must be o(n*log(max(ai)) + m*log(m)). But I've been getting a timeout on TC10. Can someone help why it is timing out? My Code