


1 октября в 17:05 Мск состоится отборочный раунд Intel Code Challenge. Официально в соревновании смогут принять участие ТОЛЬКО граждане РФ в возрасте от 18 до 27 лет. Все остальные пользователи Codeforces смогут принять в нём участие, как в обычном раунде.
Для участников Intel Code Challenge.
Для того, чтобы принять участие в Intel Code Challenge, необходимо ознакомиться с условиями проведения соревнования здесь http://codechallenge.ipdnn.com/ и здесь http://codeforces.net/blog/entry/47238 и зарегистрироваться в ДВУХ местах: здесь http://codechallenge.ipdnn.com/register и здесь http://codeforces.net/contests.
Для участников раунда на Codeforces.
Для всех остальных пользователей Codeforces это будет обычный рейтинговый раунд. Раунд будет общим для обоих дивизионов. Для участия в нем необходимо зарегистрироваться только в одном месте — во вкладке “Соревнования”.
Будут предложены 6 задач на русском и английском языках. Продолжительность раунда составит 2 часа. Традиционно, разбалловка будет объявлена ближе к началу раунда.
Автор задач этого раунда я – Владислав Епифанов (vepifanov). Благодарю Алексея Шмелева (ashmelev), Александра Фетисова (AlexFetisov) и Владислава Исенбаева (winger) за прорешивание задач, координатора Codeforces Глеба Евстропова (GlebsHP) за помощь в подготовке раунда и Михаила Мирзаянова (MikeMirzayanov) за системы Codeforces и Polygon.
UPD. Разабалловка: 500-500-1000-1500-2000-2500.
UPD 2.
Ниже, вы можете посмотреть текущие результаты Intel Code Challenge:
Если вы не нашли себя в таблице вашего города, хотя регистрировались по этой ссылке http://codechallenge.ipdnn.com/register, то после окончания контеста, пожалуйста отправьте ваши данные на эту почту — [email protected].
UPD 3.
Приношу свои извинения за задачу С. Мы решили несколько упростить эту задачу в последний момент, и так оказалось, что в такой формулировке она уже встречалась ранее.
В любом случае, надеюсь, что второй раунд пройдет лучше чем первый!
UPD 4. Разбор задач
По этой ссылке можно посмотреть места проведения очного раунда — http://codechallenge.ipdnn.com/onsite2.
На всякий случай напоминаю, что оплата проезда для участников до места проведения очного тура со стороны компании Intel не предусмотрена. В ближайшее время всем участникам, прошедшим в очный тур, будут разосланы письма с подтверждением и более подробной информацией о порядке проведения очного ура.
Ниже приведены списки участников, прошедших в очный тур соревнования:
Москва
| ФИО | Handle |
|---|---|
| Данилюк Алексей Олегович | Um_nik |
| Смирнов Иван Федорович | ifsmirnov |
| Ахмедов Максим Басирович | Zlobober |
| Ипатов Михаил Михайлович | LHiC |
| Дмитриев Алексей Сергеевич | riadwaw |
| Тихомиров Михаил Игоревич | Endagorion |
| Моисеев Борис Дмитриевич | SkyHawk |
| Останин Александр Михайлович | Kostroma |
| Омельяненко Виктор Алексеевич | TeaPot |
| Линьков Евгений Викторович | linjek |
| Краскевич Игорь Владимирович | kraskevich |
| Остяков Павел Александрович | pavelost |
| Семенов Константин Борисович | zemen |
| Минаков Александр Олегович | elshiko |
| Пособин Глеб Игоревич | passick |
| Рухович Филипп Дмитриевич | DPR-pavlin |
| Останков Александр Юрьевич | aostankov |
| Кондранин Егор Сергеевич | kondranin |
| Колупаев Михаил Владимирович | al13n |
| Кузьмичев Дмитрий Андреевич | kuzmichev_dima |
| Киян Сергей Олегович | sokian |
| Хадаев Константин Алексеевич | khadaev |
| Голованов Александр Игоревич | Golovanov399 |
| Иванов Михаил Александрович | Misha100896 |
| Кулагин Павел Сергеевич | Qmant |
Cанкт-Петербург
| ФИО | Handle |
|---|---|
| Пышкин Игорь Валерьевич | -XraY- |
| Гардер Антон Владимирович | .tx |
| Белоногов Иван Константинович | Belonogov |
| Будин Николай Алексеевич | budalnik |
| Жидков Николай Васильевич | ZhNV |
| Смыкалов Владимир Павлович | enot110 |
| Латышев Алексей Сергеевич | alex700 |
| Макаров Владислав Маратович | Kaban-5 |
| Горохов Никита Дмитриевич | wackloner |
| Гуликов Антон Александрович | scorpion |
| Логунов Александр Евгеньевич | el_sanchez |
| Збань Илья Константинович | izban |
| Сайранов Айдар Дамирович | aid |
| Банкевич Сергей Викторович | Sergey.Bankevich |
| Капун Евгений Дмитриевич | eatmore |
| Симонов Кирилл Алексеевич | Seemann |
| Степанов Всеволод Андреевич | Tehnar |
| Зуев Михаил Алексеевич | MZuev |
| Савченков Павел Александрович | pavel.savchenkov |
| Коваленко Игорь Николаевич | IgorKoval |
| Подгузов Никита Владимирович | Nikitosh |
| Богомолов Егор Олегович | egor_bb |
| Смирнов Даниил Олегович | Denzed |
| Самойлов Валерий Сергеевич | Sammarize |
| Немченко Евгений Дмитриевич | n.eugene |
Нижний Новгород
| ФИО | Handle |
|---|---|
| Калинин Николай Андреевич | KAN |
| Белошапко Георгий Алексеевич | ordcoder |
| Кривоносов Михаил Игоревич | mike_live |
| Юнович Станислав Олегович | k1nval |
| Савинов Сергей Викторович | StarCuriosity |
| Наумов Андрей Владимирович | softmob |
| Шилов Вадим Сергеевич | shilov |
| Коровин Алексей Валерьевич | Mavzes |
| Баландин Илья Алексеевич | Ilya_ |
| Матросов Михаил Валерьевич | mmatrosov |
| Сорокин Арсений Андреевич | arsor |
| Смирнов Егор Олегович | smirnov.egor.r |
| Филиппов Сергей Вениаминович | SergFilippov |
| Сафонов Александр Юрьвеич | akarilimano |
| Соловьев Дмитрий Евгеньевич | dimsol |
| Камынин Иван Анатольевич | justlovemepls |
| Путилов Андрей Владимирович | Great-expectations |
| Дёгтев Александр Сергеевич | AlexD |
| Полина Наталья Владимировна | Polina_Natalya |
| Блинцов Сергей Дмитриевич | SBlincov |
Волгоград
| ФИО | Handle |
|---|---|
| Финютин Максим Владимирович | HellKitsune |
| Сагунов Данил Георгиевич | danilka.pro |
| Рипинен Алексей Александрович | Perforator |
| Меркурьев Олег Андреевич | Merkurev |
| Ким Вячеслав Юрьевич | SlavaSSU |
| Лось Илья Викторович | IlyaLos |
| Глазов Роман Владимирович | Roms |
| Носов Артём Алексеевич | temich |
| Агафонов Владислав Юрьевич | Zool |
| Смирнов Олег Евгеньевич | Oleg_Smirnov |
| Курылев Дмитрий Петрович | DimonK |
| Кичатов Евгений Сергеевич | Eugen |
| Пенской Никита Андреевич | ShadowGorn |
| Дорогинин Вячеслав Михайлович | slavyan900 |
| Перетятько Никита Олегович | koPerNik |
| Карпов Сергей Александрович | Seraphim.v2 |
| Титов Алексей Константинович | ResQ |
| Марков Богдан Викторович | MBogda |
Казань
| ФИО | Handle |
|---|---|
| Безруков Денис Викторович | pitfall |
| Ветров Алексей Александрович | noxwell |
| Ямилов Рамис Рамилович | RamTararam |
| Муравьёв Вячеслав Вячеславович | Slamur |
| Барбанягра Владислав Александрович | WhatIsLove |
| Голуб Олеся Александровна | Taube |
| Лыжин Иван Александрович | Vanek |
| Пономарев Егор Андреевич | Petruchcho |
| Гайнитдинов Динар Маратович | dinarisio |
| Жуманиёзов Алишер Равшонбекович | AlisherZ |
| Контуров Дмитрий Алексеевич | kontr |
| Петров Владимир Алексеевич | Waldis |
| Газизов Артур Раянович | 2oo7 |
| Орешин Павел Евгеньевич | NutZ |
| Фолунин Владимир Александрович | CtrlAlt |
| Балакирев Константин Валерьевич | kostya11 |
| Серов Данил Юрьевич | danilserov |
| Нигматуллин Ранис Нафисович | Ranis |
| Кирилл Каймаков | Kirundel |
| Савельев Никита Олегович | defias |
| Мусин Рустам Идрисович | jvmusin |
| Колсанов Денис Валерьевич | deniskolsanov |
| Богданов Артур Ринатович | Dragon116rus |
| Голяндин Юрий Николаевич | ZUBAT |
| Хуснутдинова Зиля Ильгизовна | KhZi |
Архангельск
| ФИО | Handle |
|---|---|
| Попович Иван Владимирович | NVAL |
| Дергачёв Евгений Иванович | dergach |
| Гурьев Тимур Андреевич | ijnhtrgdew |
| Асютченко Павел Юрьевич | Svenny |
| Нугманов Тимур Шавкатович | orotti |
| Кобзев Дмитрий Александрович | GreenKiller |
| Пестов Сергей Алексеевич | pestov-sa |
| Рудалев Константин Дмитриевич | EclipseAltair |
| Шаршов Иван Юрьевич | sinkapoy |
| Рудный Григорий Константинович | yrog |
| Васюков Артём Олегович | vaselkov |







unusually usual unusual time
It is not a bad time for Chinese!
An usual comment about unusually usual unusual time lacking articles and punctuation.
Too much complexity brings something negative.
The round starts 15 minutes after AtCoder Grand Contest 5 ends. Must resist urge to do both...
If do both,maybe you will think of rating changes of Atcoder when you do Codeforces.
By the way, thanks for the message. I previously did not hear about AtСoder.
How does rating work when we have both divisions combined?
Probably using the same rating algorithm. It should still be fair.
if the algorithm depends on rank position, what will be then?
Glad to know that (Div.-2) can participate. Thanks... :)
What is the expected difficulty of the problems compared to codeforces's problems?
А возможно как-то проверить, зарегистрирован ли я на http://codechallenge.ipdnn.com/ ? То есть я кажется регистрацию проходил несколько дней назад, но мало ли, вдруг что не так помню, вдруг только хотел пройти...
hope for more combined division rounds like this in the future :)
Wouldn't div 1 on average do much better than div2? Lots of div2 ratings will be transferred one way to div1 lol
Wouldn't div1 on average rank much higher than div2? Probably the total rating of div2 will be transferred one way to div1 thereafter lol
It clashes with Neerc contest
Please delay Intel code challenge for an ~ 1 hour ...
I love it when codeforces organise contest regularly and that too on daily basis :)
Difficult?
http://english.stackexchange.com/questions/8856/is-it-a-usual-or-an-usual-why
A usual just like A uniform. An unusual, is good though.
is there hacking system?
Since it mentions usual round, I think we can hope for hacking as well
And boy were you right!
why you don't take into account that there is another counties can't participate the contest cause of time :|
wish to take it into account
google translate English xD
Google translate is pretty good for popular languages nowadays.
its not wrong to use google translate -_-
it's wrong when you don't know how to use it.
"into account" ?, lol. I think local terms shouldn't be translated to another languages.
For any given time there is always some country which can't participate.
This contest is mainly intended for Russians so obviously they would choose a time that fits them first and then think about the other countries.
simply they can change the time few hours and it still good for russians.
just understand that if they change "a few hours" to benefit "you", there will be people that will still be upset about the time. Simply there is just no way to please everyone simultaneously. If you can't participate at this time, just wait for a round that suits you better, it's not like there are rounds only once a month.
Вечер субботы. Серьезно?
Are the problems' statements written in Russian only?
Problems statements will be available in Russian and English languages.
How will this contest be rated for normal non Russian Div2 users?
Not the perfect time 4r a Bangladeshi participant... Bangladesh vs Afganistan cricket match is running :-( :'(
cricketers doing their job. you should do your job as a contestant too ;)
will there be any different trend in rating system as compared to other CF rounds for people like me in DIV2 ?
salam maybe it is advantage for us if we have good performance.
salam
register of this contest like register of previous contests.
Goood! I like combined rounds! I think many people will have a good rating after this round!
8 minutes before contest. Scoring distribution please? :)
Hope to finally advance in Div2 and enjoy plenty of rated contest. Wish me luck guys!
I am not being able to lock any problems prior to hacking. Is anyone else facing the same issue?
I am also not able to lock the problem
I had to click on the lock three times, but then, it worked.
Me too. I click the lock 3 times.
Couldn't lock problems
I have 1 extra submission for B, but I didn't send it. It have equal time and code with my first submission. Can you fix it?
send*
Thx)
Intel Hack Challenge Elimination Round
Karma be like:
Lol that time difference. More like instant karma xD
Same thing =) but against me..
Found a bug in my solution, but my attemps (both with different bugs) were accepted. Tests were too weak, and I used it)
P.S. hack attempt at 21:53 was really strange. Only in this moment I understood that my solution is wrong :D
Similar situation here.Only difference was I was the one who took revenge.
If only I ask question, and don't submit anything, will it be rated?
if you entered the contest area, you will get a rating.
Actually, no — you only get rated if you submit something.
i always thought that if you had already read a problem, you'd be rated. well, good to know, thanks!
Makes sense, because problems are visible publicly. You could always stay logged out until you wanted to submit.
I think some people got you wrong and put minus on your comment just because they saw "will it be rated?" :D
In problem B how can a text be divided into 0 syllable..
If all its letters are consonants?
Maybe if the text consists of only words which do not have any vowels in them.
in problem B:
statement said:
notice: "at least one vowel "
it also said:
notice: "if one can divide words"
now the answer for this test-case
1 0 bbbb
is YES, whyyyy?
because there's "Words that consist of only consonants should be ignored." on unrelated corner of the statement
are you kidding me ???
if at least this sentence was put after the condition it would be more reasonable.
Isn't it no different than the
ch allengein the first example? It is analyzed at the bottom of the statement, andchis specifically omitted.If we didn't ignore words without vowels, we would formally have to answer
NOto the first example, too. And an empty set of words with vowels, as inbbbb, is still a set of words with vowels.First, the example explanation said that
ch allengeis grouped this waych al-len-ge, I understood thatch alis one group.Second, can you separate the word
bbbbinto 0 groups and each letter is in exactly one group?? as the statement saidFirst, the example explanation said that ch allenge is grouped this way ch al-len-ge, I understood that ch al is one group.
The text at the bottom of the statement says: Since the word "ch" in the third line doesn't contain vowels, we can ignore it.
Second, can you separate the word bbbb into 0 groups and each letter is in exactly one group??
No.
as the statement said Each character should be a part of exactly one syllable
That's in the context which starts with Each word of the text that contains at least one vowel can be divided into syllables. So further we talk only about the words that contain at least one vowel. All until the last sentence of the paragraph. You can't realistically take a sentence from a random problem statement and draw conclusions without seeing the context.
I however agree with the general notion that the statement of problem B was needlessly complicating things, and was doing that not in the most readable way.
Same as my problem ,Really annoying :( !
But at least I could get its points from hacking .
Who else misread question B,locked it and finally realized that you cant have 2 vowels in the same group after trying to hack someone?
Very nice round! Problem C was the same as this one from CSAcademy.
Problem C
This is very unfair.
There is no guarantee somebody else somewhere didn't have the same idea for a problem. I'm pretty confident that this might happen very often.
Not only there :(
I think this is a simplified version of the one from RCC16 Warm-Up.
Well, that is sad. Though I don't think there is any way to avoid situation that some problem appeared on some online judge — there are too many of them nowadays.
Actually, this problem happens a lot in recent rounds, so if someone has a nice suggestion on how to avoid this sort of situations — they are more than welcome.
Use this technique: 202B - Brand New Easy Problem :D :P
The statement of F was awful. Even with answered clarification I still didn't understand that you created new array every second. So when I noticed it, I deleted some cases and copying of array three times.
I had exactly the same situation. I was just sitting and looking at the first sample for a very long time, trying to understand, why we can't achieve subsegment with length 3 consisting of only 1.
Well, it really was hard to understand but I think that first sample is the answer.
+1
This sentence is especially misleading:
at this time actually suggests to find the longest segment at instant t = 10^100. In Russian version of the statement says "за все это время" which means "during all that time", "throughout the course of a that time period".
didn't have enough time to implement D, I think Dinic + binary search can work
bin search + greedy passed pretests.
Can you explain your approach?
I tried greedy but got WA in case4, so I thought about other complicated solution. Can you tell the greedy details? thanks
Sort the sequence in reverse order. Bin search for the maximum value y. For each value x find maximum number <= y that x can be derived by operations and use it.
I got tle, but I think this solution can pass if you use int.
I used binary search + greedy and got accepted.
got it, thx!
I did D like this:
Everyone becomes equal in the contest. Thank you for Robing the Rich Bankers, and Giving to the Poor TwT
Hack case for A?
12
20:00
Depends on your program,
I hacked a few people with: 12 30:59
Why didn't you hack me??? :'( :'( :'(
A bad contest. E and F have less than 50 solvers, but D has nearly 1000 :'( So sad. The result depends too much on speed and hacks :(
Intel Hack Challenge Elimination Round
This was my first competition ever. Although my performance was quite poor, I honestly enjoyed participating. Thanks to all contributors! =)
Before system tests, every single user from 95th place to 159th place has at least one successful hacking attempt. That's 65 people in a row that are where they are because of hacks. This is ridiculous.
Everytime when I am not free to participate a competition I feel that I am comfortable with the problemset, yet I always know I will always forget to handle some exceptions and stuck in div2= =[
Anyways, the problemset is pretty interesting, but I noticed that question F is similar to CF559C. (Though there are a few extra work, especially on reducing P/Q)
UPD: Judging from the feedback it seems that I am pretty lucky to have not participated in this round... lol
You don't need to reduce P/Q at all. This problem is harder than that one because here we need to count paths with at least 20 nodes (and in that problem we needed to count paths with at least 1).
Looks like the solution here is very similar, but I still don't know exactly how to do it in O(n2).
Count path upto ith block with exactly x nodes = All path — path upto ith block with atmax (x-1) nodes — (path upto jth(j<i) block with exactly x nodes)*(paths btw jth and ith block) .
How is such a simple solution so difficult? u.u
Oh boy, it took me more than it should be to notice why it is not required to reduce P/Q ...
There's no need to reduce P/Q at all, since we do all our computations modulo a prime.
This round was an epic fail for me. It will be hard to recover my rating =)
Problem B. 1 1 a aa Why answer is NO? a — one, aa — ignore.
There are two words already. That means you cannot do less than 2 syllables.
You can only ignore words which consist ONLY of consonants. Hence you cant ignore "aa".
Words that consist only of consonants should be ignored!
Isn't TL in E too tight? :/ N^2lgS, with tons of modulos...
http://codeforces.net/contest/722/submission/21092074 (2418ms)
Otherwise O(N^3) solution would pass..
So I should compress more modulo operations in 2 seconds of contest time :p
It was enough to cache poss(j, l) value (and change loop order for more uniform memory access): http://codeforces.net/contest/722/submission/21093611
I somehow passed the pretests but still can't understand B:
1.Can we divide "aaaa" into "aaa","a" to obtain one syllable?
2.Why can we divide "to" into one syllable?
Each syllable consists of exactly one vowel (yes i'm hacked because of this)
I think the statement meant to say there are only one vowel allowed in each syllable, and thus it reduces to a problem that counts the amount of vowels(eg: to has one 'o').(which makes a lot sense as a question B)
1.Nope, after locking in and trying to hack, I realized that we cannot group 2 or more vowels into one group. So the only way to split "aaaa" is "a","a","a","a" . The correct answer would be 4.
Since when is 'y' a vowel?
It can be sometimes.
In every page i saw lots of hacked...Can you please tell me how to hack? and what is the benefit of this? thanks in advance..
Before you hack, you need to lock your solution to the problem you wish to hack. You can hack by going to your room, and double clicking on someone's solution that you wish to hack. Then you see their code, and if you think their code is wrong and doesn't work for all cases, you can click on the button hack, and give a test case for which you think the solution would produce wrong answer. If you are correct, you gain +100 points, if you are wrong you lose 50 points.
increase D's time limit to 3 :______________(
hmmmm... or 4...maybe
I missed D due to B.
B was easy, just had to count the number of vowels for every string which could be done in a few lines of code, I would have done it if I knew how to take multiple strings in one line :/
getline(cin, str) working only with cin.ignore().
It's you're problem not the problem of B. It was very easy to me to solve this problem.
The problem statement of B was very misleading.
Hack system has one really annoying bug. When I wanna see participant's code, it moves up and it's unable to see more than half of code. I could have 1 more hack without this bug..
I thought it's only my problem !
How can this code be hacked for 2A?
http://ideone.com/Z1ui6u
It could be hacked by:
12
35:00
Hack War( again )
How to do C >.< My solution use set and would most probably fail the sys-test. >_>
I think you keep a multiset/map for the segment sums, a set that keeps the destroyed elements, and a prefix sum for quick calculations. For each destroy action you binary search for the previous and next destroyed elements and update the segment sums from the prefix sum.
Set is probably better for this. But if you looking for a long approach then segment tree (infact http://www.spoj.com/problems/GSS1/ part of it)
An O(nlogn) probably won't TLE
Issue was not NLOGN . Issue was I was handling too many corner cases manually .
Check out my solution: http://codeforces.net/contest/722/submission/21092975 No ugly corner cases. (edit to change to the AC submission)
Great solution . Using -1 and n as sentinel was neat.
Thanks. Just resubmitted with 1-n indices for a nicer code.
You can use dsu.
I was thinking about DSU but discarded it because there is no delete option ( There is but that is too complicated ) processing the query in reverse manner was smart.
Can you describe your solution in words?
You can do operations from end and deleting becomes adding.
Here's my solution , A is the first array given in the input , B is the second array given in the input . segments is the total number of segments so far . At first you create an empty array , let ind = B[i],value = A[B[i]] . starting from the last element to be destroyed (from n to 1) : there is one element inserted in this empty array at index(ind) , so you add a new segment with :
right[segment] = ind,
left[segment] = ind,
sum[segment] = value;
now every time you insert a new element , you have to check the segment at the left index of you (ind-1) and at the right index of you (ind+1), if there exists ONLY one segment (either to your right or to your left) , you have to add the value to its sum and UPDATE its boundaries(right or left) , if you have BOTH segments you have to combine them and form a new segment with :
left[new segment] = left[segment[ind-1]];
right[new segment] = right[segment[ind+1]]];
sum[new segment] = some of BOTH segments + new value;
Very Poor statement for B :
We define a syllable as a string that contains exactly one vowel any arbitrary number (possibly none) of consonants.
Because of missing and,I thought it means exactly one vowel for any arbitrary number of times.
yes contest should be unrated :/
also problem C was picked form CS Acadmey
By the way u solved both B and C
I'm not like you...
I care about the others too :/
seriously?
no
lol :D
The same here!
This contest should be made unrated because C problem was directly picked from CS Acadmey without even changing the name.
Yes the contest should be made unrated.
Hmm, seems right, here's the problem link.
(to clarify, the comment is right that problems are the same, not that it automatically means unrated)
This problem is too standard, every Div 1 coder must have met it many times. It's not a reason to make it unrated.
yes , the round should be rated for some people who solve something they have not seen before , then they feel delighted at it , such people who after every contest simply demand the round to be unrated because of so and so reason should atleast think of it.
Contests aren't rated/unrated to make people delighted or not o_O
In problem B,can anyone explain why 2 vowels cannot be in the same group.
Via problem statement:
"a syllable as a string that contains exactly one vowel"
exactly one vowel defines a syllable
I tried C in a approach with queue and recording the divisions in a queue. but of course it got tle because it is O(n^2). But can I use the same approach and just upgrade the time?
http://codeforces.net/contest/722/submission/21090359
and wtf I got WA in A even though it passed pretests!! pls tell me whats wrong http://codeforces.net/contest/722/submission/21072772
if(m>=59) m=m%10;
Probably there was something wrong with English statements. People in my room wrote totally wrong solutions, and considering that the problem is very easy, the unclear statement has to be the reason.
I think the English statements look exactly the same as the Russian one. I think the most confusing part is the phrase "can divide words of the i-th line in syllables in such a way that the total number of syllables is equal to" like you can somehow divide them into different number of syllables, but you can't really =)
bad statement in problem B
you can steal problem C solution from HERE !
weak test cases and a lot of hacks
I'm glad because I didn't participate xD
Написал Д, послал, прошел претесты. Решил потестить. Ок, Рандомные тесты проходит. Сделал тест — все числа равны миллиарду — Решение упало. Поставил заглушку, перепослал. ВСПОМНИЛ, ЧТО ВСЕ ЧИСЛА РАЗЛИЧНЫ...
I had not seen the problem C before yet i solved it, so deserve my rating increment. So, making this round unrated is not the solution
such logic much wow
Yeah there were people who solved the question by thinking. The contest should be rated as too the people who are saying its copied too get to know it when the contest ended and looking at the time div 2 people solved it , the contest should be rated.
It should be RATED .
Yes, I agree with you!
How soon will the editorial be published?
Удалите меня, пожалуйста, из результатов по Москве, я когда регистрировался, не до конца осознавал, что он только для граждан РФ :)
Congratulations, extremely fast system testing :)
Hack & Hack Back :D
That is exactly what I call "Peresvet & Temir-murza" achievement. Well done!
I think problem D can solve by use trie and add all element as binary respresent and problem became choose node satify : In subtree u, number of choose node equal number of leaf. when at node u, I will choose node has maximum of leaf is minimum. But I has falled. Is my approach wrong ?? Can someone has same approach with me can explain me how to do this?? Sorry for my bad & poor E :))
yes trie can be used to solve the problem D
I had a similar approach wherein I add binary representation of all given numbers in trie and at each node
Now iterate i from 1 to max(a[i]), and search binary representation of i in trie and pick the max element with that prefix and delete it from trie and for that deleted element push "i" into another vector which would hold the answer.
Now this seems to be a valid approach but the catch is that I have to iterate over from 1 to max(a[i]) which can be equal to 10^9 . an example test case would be
30
1 2 4 8 16 32 64 128 256 512 1024 .. and so on till 2^29
Here I need to iterate from 1 to 2^29 and no number a[i] can be reduced to smaller number.
However, this problem is much easier and can be solved using a simple priority_queue and map. See my code 21097078
Thanks for reading. :)
Poor guy
I bet he's mad
I'd be mad
You know he's not actually losing points on this, right? People should actually think of being hacked as a favour / hint :)
Except of course if someone generates a testcase against the particular primes you're using in your hashing solution :P
Great round, maybe next time it will be a programming contest instead of a hacking contest.
My B got FST because I got a wrong statement:
I forgot the condition that each syllable can only contain one vowel.
But I passed the pretests easily.
I think the pretests should at least make the solution which have wrong statement get wrong answer.
I want to give this problem a downvote if cf have this function like uoj.ac
(╯‵□′)╯︵┻━┻
Maybe this is a advisement about UOJ...
(So come to uoj.ac and you will see a new world)
... And you cleared everything besides B, which could've made you placed fifth...
How to solve C? I got TLE.
You can solve it offline starting from the last query. Instead of destroying, you can insert elements, always keeping the maximum sum. If you insert an element at position p, you can find the first destroyed element to the left and to the right, and update the maximum sum.
You can do like statement , when destroy i, assign a[i] = -oo and find maximum sum of consecutive elements use segment tree like this problem
C: You start off with 1 segment corresponding to the sum of the entire array. Every time you remove an item, you destroy the segment corresponding to that index. Usually you end up "splitting" a segment into 2 smaller segments so you need to destroy one segment and add 2 new segments. However, if you remove an item from either end of a segment, you only have to create 1 new segment (or 0 in case where segment had only 1 item).
How to quickly find the segment we are splitting? Keep a TreeSet or similar structure of locations of previous splits. When you initialize, add 0 and n+1 as bounds into the set.
How to quickly find the sum in any given subarray? Create a sum array where sum[j] corresponds to sum from [1...j]. Then you can query a sum between [i,j] with sum[j] — sum[i-1].
How to quickly find the maximum sum of all segments? Keep a TreeMap or similar structure where the keys are the sums of segments, values are the counts. For example, if you have 2 segments where both have sum 47, it would correspond to entry (47, 2).
http://codeforces.net/contest/722/submission/21084299 (used Fenwick tree instead of a simple sum array)
Hello,
I follow the same algorithm as yours but I am getting TLE when n = 100,000.
Here is my code — http://codeforces.net/contest/722/submission/21109605
Using System.out.println() for multiple lines of output is slow. I changed your code to use PrintWriter for (buffered) output and it passed in 700ms:
http://codeforces.net/contest/722/submission/21113948
Awesome! Thank you!
Why can't we make submissions? I coded problem D, after the contest ended but I can't test whether it is gonna pass or not.
submissions are locked while system testing is running. you can submit now.
When not to fail A is harder than not to fail C
u can iterate all possible time and get min different between them and origin time, it will be accepted =))
Yea, I understand, but it`s not funny :D
А что делать, если я нашел себя как минимум в трех городах?
Участник отображается во всех таблицах. Чтобы узнать, то надо разлогиниться или попросить посмотреть другого человека.
Ты смотрел под своим аккаунтом или инкогнито? Кажется, ты автоматически показываешься во всех таблицах, просто когда смотришь их.
Я нашел себя как минимум во всех городах. Думаю, это просто для удобства, чтобы оценить на каком бы ты был месте, если бы участвовал в этом городе.
Почувствуй себя Джанго Феттом.
bad statement for B, and C picked from CS Academy. making the contest rated can be seriously unfair!
why F F?
How this can be TL??? http://codeforces.net/contest/722/submission/21077518
Shit, I got it. I missed debug cerr with endl before the submit and of course it's very slow. Without it it gets 200ms as it should.
How to solve D?
I was thinking of making binary tree with children of current node as node*2 and node*2+1and the solution using DP on tree on this tree with state (node, {0, 1}) where DP(node, 0) is the minimum cost to fulfil all leafs in this subtree excluding one of them, and DP(node, 1) is min cost to fulfil all leafs in subtree including all of them. But I was unable to figure out how to generate the actual values that we have chosen(and not just the maximum). Did anyone try this approach?
It seems greedy with binary search passed. Can someone explain there solution?
My greedy solution passed the sys tests (to my surprise). I put all numbers in a binary tree, and then i repeat this:
1) remove the max element from the tree
2) divide that element by 2
3) check if this number is already in the tree, if it isn't put it in the tree, and go to 1), else continue dividing by going to 2) while the number is bigger than 0.
When a number can't be inserted in the tree with this algorithm (i.e. you keep dividing untill you reach 0) break from the loop, and print all the contents in the tree.
I did almost exactly the same thing. My complexity for this came out to be O(n*log(n)*log^2(1e9)). It still passed though. What was your complexity?
Proof of correctness ?
After finding out the maximum value with tree DP (if it is theoretically correct) you can just get a boolean array b[1... max] recording whether each number is used in the answer. For each y just divide it by 2 until it reaches a number that is not used (b[y'] = false holds), mark this number as used and append it to the answer. Through simple observation we can figure out that going further (using y' / 2, y' / 4...) will never be better since doing so eats up more possibilities for it serving other y's.
I wasn't able to find out the DP method before switching to a binary-chop approach, but once the maximum value is found (in either way) the remaining part keeps the same.
21085320 [ Weird output ]
Why does
nvalue changes toNin the last for loop?Anyone?
Due to hacking we have NO solutions failed on system tests in our room. During the entire contest I was wondering why some people have that many successful hacks on B, was checking my room constantly and only in the end some participant sent submission which was checking 'at least N syllables' rather than 'exactly N'. Was it the main hack case in this problem for other participants?
yes. I got 3 hacks because of that, I could get 2 more but round finished
Умные люди, расскажите, как в C понять, что много set'ов получат TL. У меня решение за NlogN радостно его получило.
UPD: ясно, привет, cin/cout. Но не давать какой-нибудь макстест в претестах не очень красиво.
какие давать претесты — полностью на усмотрение автора
У меня с
cin/coutзашло.Практически единственное различие между своим кодом и твоим, которое я вижу, заключается в том, что я не делаю лишних
lower_boundи вставок. Зачем два множестваzero_pos, если хватает одного? Можно же сделатьleft = *--zero_poses_1.lower_bound(p);И зачем вообщеlower_bound, если хватаетinsert(и аналогично по одному разу++и--)?Тот же вопрос. Может они юзали не экземплярный upper/lower_bound(), а статический из algorithm?
у меня NlogN упал по ТЛ из-за cin/cout. Заслал с scanf/printf отработало за 180 мс
And now I wonder if we really should visit the onsite. Is it worth going, will the quality of the next round be significantly better than of the current one?
Codeforces coordinator said it :D
I don't know about problemset, for me it was fine, texts were unclear but that is job of codeforces reviewer right ?
I spent around one hour on thinking why my function erase doesn't work for multiset and then I realize I can read c++ reference :D
It`s a question of belief! (And fear of being hacked forever :P)
My solution for C was getting wa on test case 15. link to soltution: http://codeforces.net/contest/722/submission/21088563 while it gives correct answer for same test case on ideone and my local complier(dev cpp) http://ideone.com/08V4dG Can somebody please help me understand what am I missing here?
multiset erase function erases all instances of that variable , thats why it is giving wrong ans , I use linux and its giving wrong ans on my machine
C is a simplified version of 527C - Glass Carving
Exactly this was the question that came to my mind when I first read problem C today. But could not find it. Thanks for sharing. :)
AABBEE
AABCFD :(
for me, fourth problem was easier than third
I wonder, it is word "me" provokes downvotes? o_O
Can't agree more!
Missed a long and lost tons of point in F :( Maybe I should use
#define ll long longor something else......C++11 way:
using ll = long long;Just if you want to look cooler. =)
u can use #define long long long. That is so fun.
English statements were ambiguous :| Round should be unrated :/
Poor problem statement for B.
"Официальные результаты Intel Code Challenge, а также разбор задач будут опубликованы в воскресенье, 2 октября."
А рейтинг когда пересчитан будет?
О, пересчитали
Does UPD 2 mean contest is rated ?!
Waiting For The rating update ....
Wait is over. :)
I cracked the logic for problem D 5 minutes after the contest ended, and it took me another 5 minutes to code it, since I was already thinking along those lines. :(
Newbie forever :(
http://codeforces.net/contest/722/submission/21074766
Can someone tell me how to track the set having max sum among all possible sets in DSU Its understood that in the above code find() and merge() functions are to find parent of an element and merge an element into a set to which it belongs but how to keep track of the sum ?? Can any1 xplain in details please.
following
I understood it. the main idea behind the solution is actually we can process the queries offline . That is instead of traversing from i=1 to n and deleting every element we can actually revert the task and start from i=n to 1 and insert the element into its corresponding set.
Everything is 1-indexed :)
Like the example n=4 , a={1,3,2,5} and p={3,4,1,2}; We have a boolean array ok to check if certain element is in set or not. Also keep a sum(long) array to keep track of sums of a set Initally all elements have parent[i]=i;
we start from i=4 and intially we have all sets as null so current ans=0 ( beacuse at last all elements are going to be deleted ). Now print 0 and let x=p[4] so update sum[x]=a[x] , as in our case a[2]=3 . we check both left and right of 'x' and we can see that neither 1 nor 3 is visited so simply find parent of 'x' which is 2 itself, so ans is updated to be max(0,s[parent[x]]); =>ans=3 and mark visited[2]=true;
Next we have i=3 ans p[3]=1. So we again check for left and right . In our case we only check for right side(1-indexing) so 2 is visited so we merge both set having element 2 and set having single elememt in 1 in such a manner so that the parent of the resulting set has suppose index as "parent_index" then sum[parent_index]=sum_of_all_elements_in_set; next we update our ans and as its either max sum from merging our current set or from previously merged sets and then we mark the element we processed as visited.
Continue for rest elements and Bamm its Accepted.
Thanks to FatalEagle for his clean code . Helped a lot.
For Java Users my submission :- http://codeforces.net/contest/722/submission/21097209
this is a hacking round >_<
Yay, I am finally yellow! <333
*orange
тот момент когда падает задача С потомучто пользовлся cin/cout вместо scanf/printf
99% кода пишу на джаве, но когда нужно что-то написать на плюсах — первым же делом пишу sync_with_stdio(0) — и очень удивляюсь, когда люди, постоянно пишущие на плюсах не включают ее в шаблон. Может этому есть какое-то объяснение? Ваш код — 21096389
Ответ очень прост: лень. Тем более это полумеры. Со сканфами и принтфами 180мс, с sync_with_stdio(0) — 600мс.
С cin/cout все хорошо, если правильно работать. Например, если заслать ваше решение под C++14 (21107832) то оно получает уже 420 мс. Так же, если добавить строчку "#define endl '\n' ", то ваше же решение (21108089) работает всего 200 мс, что уже очень близко к scanf/printf
По-моему, там разница не в C++14, а в наличии
cin.tie(0).Но вот уж чему-чему, а тому, что
endlмедленно работает, удивляться не стоит. ibra, в варианте со сканфами и принтфами Вы же не пишетеfflush(stdout);после каждого принтфа? А ведь именно это означаетendl.Да, про
cin.tie(0)я не упомянул, хоть и использовал его. Но все же в C++14 cin/cout работают заметно быстрее, например вот тот же код на C++14 безcin.tie(0)(21163397) и его заслуженные 450 мс вместо 600 на C++11.Это странно. Разве в C++14 были какие-то изменения, связанные с производительностью iostreams? Может быть, дело в том, что для C++14 на Codeforces (по непонятным мне причинам) используется более новый GCC и libstdc++? Хотя в любом случае я не знал, что cin/cout стали быстрее — это приятно и полезно знать. (Если, конечно, быстрее действительно стали именно cin/cout, а не какая-либо другая часть программы.)
MikeMirzayanov упоминал об этом в своем блоге. Иногда полезно читать главную страницу Codeforces :)
OK. :)
Хотя это, к сожалению, всё равно не объясняет, почему стало быстрее (равно как и почему C++11 всё ещё на GCC 5). Было бы интересно знать.
И непонятно, есть ли какой-то способ об этом узнать, кроме как прочитать блог. К тому же, если это особенность конкретных версий, сборок или даже настроек компиляторов/библиотек, которые используются на Codeforces, то это тогда не правильное использование cin/cout, а правильное использование Codeforces!
Thanks for a really awesome problem set. Really enjoyed the contest.Almost turning color.
Anyone getting this message "The page is temporarily blocked by administrator. " on clicking problemset?
Yes, maybe administartors want to add new problems
Come on, still blocked! :(
Much simpler solution for D 21091527
Push all elements into a Priority Queue and pop out the top element, reduce it ( divide by 2 ) until it encounters a value which isn't visited yet and push reduced value into this Priority Queue.
Repeat this process until you are unable to reduce the top most element further.
That's it!
Yup, nice! I actually used the same solution during the contest: 21088132
can you explain your solution and why it works? I'm unable to solve it without binary search.
Let's start with set Y, and we want to find X such that the largest element is as small as possible. To make our set better, we want to take some element yi and replace it with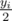 , or we keeping dividing by 2 if that number is already in the set. Since we only care about the value of the largest element, decreasing any smaller number doesn't improve your answer.
, or we keeping dividing by 2 if that number is already in the set. Since we only care about the value of the largest element, decreasing any smaller number doesn't improve your answer.
For example, changing the set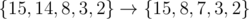 doesn't improve our answer, since the greatest element is still 15.
doesn't improve our answer, since the greatest element is still 15.
Because of this, it's always optimal to process the largest element first, because not changing it, in a sense, makes all your other changes "useless." (Again, we only care about minimizing the largest element in the set).
To find a replacement for the largest value (let's call it x), we can successively divide by 2 until we find a number that has not already been taken. Once we replace the number, we can repeat the process for the new largest number.
If, at any point, there is no other number that can replace the current maximum, we are done, since any future changes will not affect our answer.
A priority_queue works well in this case:
I was also going for binary search. But finally had similar n log^2 n solution in the contest.
Can someone explain me this thing. In C. Destroying Arrays, I have a doubt regarding second example testcase. 5 1 2 3 4 5 4 2 3 5 1 After 1st destruction, we will be left with segment (1 2 3 4) implying 10 as the first output, but it is 6 as for the test case. Thank you.
The indices are 1-indexed, so after removing element 4, we are left with 1, 2, 3, X, 5. Taking the interval (1, 3) gives us a sum of 6.
after destroying the first element we will be left with two segments
[1, 2, 3]and[5].why were all my submissions skipped? http://codeforces.net/contest/722/submission/21086541 http://codeforces.net/contest/722/submission/21082063 thanks
My screencast (got 42nd place)
Keep them coming mate!
In problem D, as I see on reference C++, function count on unordered_set in worst case work in container size, why your solution got AC dj3500 ??
It's average-case constant (that is, amortized and with high probability). It's based on a hash-map — you might want to read up on these :)
Three CodeForces bugs (two of them very old), documented in my screencast:
%lld: link,Why Problemset page is still blocked?
// Why 12:01 ?
12:01 with 12:91 ->1 dif 11:11 with 12:91 ->2 dif
I mean why 12:01 is correct ? The format must be 12-hour , but 12:01 is valid only in 24 hour format,or not ?
In 12-hours format hours change from 1 to 12.
.
.
.
ITDOI Use the contest problem page, its working through that.
Problem C
I want something more
А где можно будет найти разбор?
Can anyone please help me find (what I think is) undefined behaviour in my submission for C?
These two submissions differ by essentially a nop, yet one of them passes and one does not: http://codeforces.net/contest/722/submission/21097824 http://codeforces.net/contest/722/submission/21097825
There should be 0ll, not 0. With 0 you actually pass a 4-byte integer to a function with variadic arguments. Implementaion of printf finds the %I64d specifier, attempts to read 8 bytes and prints some garbage with lower 4 bytes equal to zero.
My suppose on why this is resolved by adding an fprintf: by calling fprintf you sanitize the stack. It means that because of some inner recursive calls inside fprintf or because of fprintf itself it happens that the 8 bytes you going to print are actually assigned to zero as a side-effect, and you successfully print zero in this case. Note that all function calls between fprintf and incorrect printf are in
ifblocks that are not executed, andsums.empty()is most probably inlined and does not result in a function call, so the zero-effect is still having place at the moment of invalid printf.Thanks. Looks like you are right, and compiling with
-Wallcould have saved me.In the spirit of the day, I'd call it a nontrivially trivial nontrivial bug.
I am getting wrong answer in C. i tried to solve it by segment tree. tried many times but can't manage to get accepted.Help me please :)
my code: 21093304
my similar code got accepted in spoj GSS3. link: GSS3 .but why not here? please tell me if i get anything wrong.
I solved it by segment tree too.
but there is some difference between your code and 21097169 .hope it helps you!
you can set your inf larger, MAXVALUE * N is enough, and when add two value, get max of it with -inf, don't worry about overflow
Did the same mistake and someone hacked me...change your inf value to 7*1e13 and it should get AC
Thank u very much :D. i changed my inf to 70000000000000 (7*10^13) and got green signal :)
but i used some other values like 9*10^16,9*10^17,9*10^18 for inf, but they failed me.the reason is not clear to me, can u pls explain me why they failed? please dont bother if i say some thing stupid :D
for each node of segment tree, you store sum associated with it (in your code total). If u use something > 1e14, than it sum over the largest array of size 1e5 becomes > 1e19, causing overflow and incorrect results.
thank u very much :) just another question, what can be the minimum value for inf in my code? 10^9?
(greater)> 5*10^13
range what I think: (5*10^13,9*10^13)
In contest I used 10^13 and got hacked!
everybody can take part in final round ??
Does anybody have a proof for D's greedy solution (with heap and dividing by 2)?
let S denote the answer set by the greedy method, let a1 denote the maximum number in S, then
every b = a1>>k (k >=1 and b > 0) is in S
It's obvious S can produce Y, just need to prove a1 is optimal, we can prove it by contradiction. if there is an optimal set S' whose maxinum number is c(c < a1), then a1 must corrispond to some smaller number a2 = a1>>k(k >= 1), and now a2 is in S, S contans no a1 and duplicated a2, we must changed a2 to a3, and if a3 becomes duplicated, we must changed it to a4 and so on, until an a(n) which is not duplicated, we can prove by induction that such a(n) doesn't exist.
if ai(i>=2) is duplicated, and every b = ai>>k(k>=1) is in S, we change ai to aj(j=i+1, aj < a1), then we have
aj becomes duplicated, and every b = aj>>k(k>>=1) is in S.
There are 2 cases,
1.aj=ai>>k, trival.
2.ai != y, ai=aj>>k, let ai = ai'>>ki, where ai' is a maximum number in the set and changed to ai during the algorithm loop, since the maxinmum number in the set is decreasing during the loop, so ai' >= a1, hence aj = ai'>>k' and ai' > aj > ai. At the time when ai' changes to ai, for every p = ai'>>kp and ai' > p > ai, p is in in the set(by the algorithm), so either p remains in S, or p changes to some smaller number which means p >= a1(same reason for ai'>=a1). since aj is some p and aj < a1, so aj becomes duplicated, and every b=aj>>kj is in S.
Thus there is always a duplicated number in S, a1 must be optimal.
Thank you so much! A nice proof!
Editorial?
For me, I had never attempted problem C or any very similar problem on any other online judge or CF, and after attempting D this morning, I feel D is easier than C. C is a little implementation heavy, and D is more of logical thinking problem. If the statement of B was more clear yesterday, I wouldn't have wasted so much time solving it, and might have ended up solving 4. All in all, I really enjoyed the contest, as I always do on CF :)
В финале будет Div2?
Editorial for this round will be published on Sunday, 2 October.2017
Can anyone please tell me the difference between the below two (complexity wise):
where, S is a set and x is the number to be searched in the set.
In problem C, using 1) gives TLE on test-13. The same code gets Accepted on changing 1) to 2).
check this comment
Thank you.
Разбора все еще нет(
Please offer a (hopefully rated) parallel round of the final round for those of us who didn't make it into the finals. :(
Second round will also be open to all participants as well as the first one.
Thank you!!