


The best I came up with is O( N*sqrt(N)*log(N) ) using MO to sort the queries — the log(N) part is for querying the most frequent value in that range. Got TLE with that — even in some smaller cases.
Any hint? :)
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 157 |
| 6 | Qingyu | 156 |
| 7 | djm03178 | 152 |
| 7 | adamant | 152 |
| 9 | luogu_official | 151 |
| 10 | awoo | 147 |
The best I came up with is O( N*sqrt(N)*log(N) ) using MO to sort the queries — the log(N) part is for querying the most frequent value in that range. Got TLE with that — even in some smaller cases.
Any hint? :)






I solved this problem using random sampling — I took k random indices (where k is a constant) in the range for each query and checked if the number at that index appeared enough times in the range to be dominating (in O(logn) with a binary search), so the total runtime is m*k*log(n). The probability of failing to find the dominating element of a query is always less than 1/(2^k).
Could you please explain how to check if a number appeared enough times in the range with a binary search?
For each number keep a sorted list of all of the indices where that number occurs. Then, create a function f(L, x) that counts the number of elements in a list L less than a number x. The number of occurrences in the range is f (L, b+1) — f (L, a).
Great solution :) What did you consider to decide on the value of K?
I went with 35, but it might be necessary to decrease it depending on the time limit.
There's a deterministic solution which runs in O(log n) per query. Think about how you'd solve a single query in linear time, but constant memory. If you fail to do this on your own, look it up, it's a somewhat classical interview problem. You'll notice that it has some neat properties that come in handy for solving multiple queries.
Thanks! That was helpful. I actually read solution long ago about how to do for frequency > N/3 ( linear, constant space ) but totally forgot until you mentioned "classical interview problem".
Consider a range of numbers. Let's remove pairs of unequal numbers (arbitrarily) until all the numbers are the same. (Or there are no numbers left). There will be at most 1 number left. Can any other numbers be dominating in this range?
Now, you can use a segment tree to simulate this process. For each node, store some information about the number remaining after cancelling out unequal numbers.
Here's the code for combine (spoiler!)
Thanks man! That was a lot of help!
I solved it like this: Let Length = R — L + 1. Consider the value bit by bit. Suppose we're considering the kth bit. If in [L, R], there're more than (Length / 2) values with kth bit equals to 0, then kth bit of answer must equal to 0, otherwise it's 1, and if there are exactly Length / 2 value 0 and Length / 2 value 1, there won't exist an answer.
After that, check if that answer appears more than (Length / 2) times using whatever you want (I use a vector and binary search).
Another non-deterministic solution in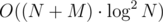 .
.
Observe that if some element is dominant in an array, if we split this array into some parts, it must also be dominant in at least one of these parts(this is easily provable by contradiction). Keep a persistent segment tree to find frequency of an element in a sub array. Now, build a segment tree on the dominant value in a subarray. As we know during range query we visit at most nodes, we can query the dominant member of each of these parts in the entire subarray and check for it's dominancy.
nodes, we can query the dominant member of each of these parts in the entire subarray and check for it's dominancy.