


If you find all the small divisors of n that are less than sqrt(n), you can find the rest of them dividing n by the small ones.
By the way, this problem is widely known and googlable :) You can, for example, check out this link: http://stackoverflow.com/questions/26753839/efficiently-getting-all-divisors-of-a-given-number
Try coming up either with greedy algorithm or with two pointers algorithm.
Try to prove the following greedy: in each step we can choose the cheapest remaining mouse. If there is a computer left that has only one type of port suitable for this mouse, plug it there. Else if there is a computer with both types, plug it there. Else discard this mouse.
Try to also come up with the two pointers solution. If you cannot, it is described under the next spoiler.
Sort all of the USB mouses and all of the PS/2 mouses so that the price is non-descending. Then you will need to buy some prefix of USB mouses and some prefix of PS/2 mouses. Iterate over the number of USB mouses from 0 to their count. Now, the more USB mouses you buy and plug into computers, the less PS/2 mouses you will be able to buy, because the number of computers will only be decreasing. So you should move the first pointer forward, and in every iteration move the second pointer backwards until you reach such amount that it is possible to plug both USB and PC/2 mouses in.
Try thinking not about erasing a substring from B, but rather picking some number of characters (possibly zero) from the left, and some from the right.
Two pointers
For every prefix of B, count how big of a prefix of A you will require. Call these values p[i]. Put infinity in the cells where even whole A is not enough.
Same for every suffix of B count the length of the required suffix of A. Call these values s[i].
Now try increasing the length of prefix of B, while decreasing the length of the suffix until p[pref_len] + s[suf_len] is less or equal to the length of A.
The toughest thing about this task, is that you can go to the left. Try to come up with something to handle that.
Try to prove that in optimal solution you don't need to go more than one cell to the left before coming back.
Try to come up with a solution where you iterate over each frequency
Try to group stations that will be on the left side in a pair in one vector, and stations that will be on the right side in a pair into another.
Iterate over each frequncy. Suppose you are now on frequency i. Put all radio stations with frequencly i in the left vector, and all radio stations with frequencies i - k..i + k into the right vector. Notice, that the total size of all vectors you get this way is no more than (2 * k + 2) * n, because every radiostation will be one time in the left vector and at most 2 * k + 1 times in the right vector.
Now we need to calculate the number of possible pairs where left radio station is from vector left and right radio station is from vector right.
Sort stations in the left vector by position. Sort stations in the right vector by left bound of their range. Iterate over the stations from the left vector. Now, as you do that, larger and larger prefix of the right vector will have stations with their left bound less or equal to the coordinate of the currently processed station from the left vector. For each new such station you should add 1 to some RSQ structure (easiest is fenwick tree) to the position of this station. Since positions are up to 109, you will have to compress the coordinates (for example, use index of station in the sorted order instead of it's coordinate). Can you see how to query this fenwick tree to get the number of stations that match the currently processed station from the left vector?
No nested spoilers. It's serious business here!
One of the possible ways to make your life easier is to count the number of automorphisms of tree T. This way you will be able to first calculate the number of labeled matchings of vertices of tree T to the vertices of tree S, and then divide this number by the number of automorphisms.
Although solution that I will describe does not use this! :D
First, remember that every automorphism has a fixed point. Either a vertex or an edge. This is called center of the tree, and you can find it by first finding the diameter of the tree. It's middle vertex (or an edge, if there are two middle vertices) is the center of the tree.
Let's root T at it's center. Now let's enumerate subtrees (rooted ones!) of T in such a way that if two subtress are isomorphic they will receive the same number and vice versa. You can do it in a single dfs processing subtrees bottom-up. These numbers will correspond to different isomorphisms.
Now you can do a dp with memoization to calculate for each subtree of S rooted at some directed edge the number of ways to "attach" each of the isomorphisms from above to this subtree. This can be done by going through all immediate children of the currently processed vertex of S and doing a bitmask DP, where bits are immediate children of the root of currently processed isomophism of T. 1 means it is "attached" to some children in S, 0 means not.
One of the problems here is that root of current isomorphism of T can have isomorphic children, and if we shuffle how they are attached to children in S we will still receive the same way to cover S with T, so we will calculate some ways twice or more. The solution is to sort children by their isomorphism number and when processing a bitmask, never put 1 to the bit that has a 0 bit to the left that corresponds to the child with the same isomorphism number. This way you will match such children in a fixed order and won't calculate anything unnecessary.






Hints inside hint. Cool
recursion style
Nice structure of the editorial =).
Yo, dawg! We heard you like hints, so we put hints into hints so you can read hints while reading hints! Thanks for editorial!
for C.
and iterate two pointers help me.
Is the whole editorial going to be in this format? (spoilerception) I think it would be quite difficult to navigate.
This is already the whole editorial :)
I feel that people usually come to the editorial with specific task in mind, and not to read the whole editorial at once. This way they can just unroll the task they need, and not spoil themselves by accident glancing over the editorial of a different task :D
Also, seeing the whole solution may be less beneficial than taking a hint and trying to still solve the problem by yourself.
agree
what is open hacking ? will the non-participants be awarded with points if they are successful in hacking ?
Hack and see what happens :)
WoW! what an answer! anyways thanks!
yeah true!
You teach me and I teach you, POKE.. CODEFORCES
For E, it seems possible to do using 2D range-update point-query:
Sort radio stations by range in increasing order.
Now, imagine each station as a point on a 2D (position, frequency) plane.
Each radio station conflicts with any radio station in the rectangle given by (p-range, f-k) to (p+range, f+k).
Simply query each new radio station, the sum of which is the answer.
Seems more painful than official solution though.
This ensures that the one of the two has the other one in range but doesnot ensure the other way round
If you order by range in decreasing order yes.
I have a good solution on problem E.But in fact,it is similar to the official solution.
(sorry,my English is poor,and I haven't written comments before.It is my first comment.)
We can sort stations by range,and now when we query station i,we guarantee ri<=rj.
We need to find how many j satisfies this i,that is,satisfies these two inequations:
xi-ri<=xj<=xi+ri
fi-k<=fj<=fi+k
You can use the 2D-segment tree to solve it.But I don't really recommend this.
We notice that k is small.So we can iterate every fj which satisfies fi-k<=fj<=fi+k.We can use segment tree to query how many j satisfies xi-ri<=xj<=xi+ri.That is,for every fj we use a segment tree to keep xj,and when we query station i,we first iterate every fj which satisfies fi-k<=fj<=fi+k,and then we query how many j satisfies xi-ri<=xj<=xi+ri on our segment tree.
We can make a discretization for every fj,or we can ask for memory dynamically.Then we won't get MLE.
valorwxp
"then we query how many j satisfies xi-ri<=xj<=xi+ri on our segment tree"
How do you do that?
We can keep a value freq in every segment tree node, where [L, R] corresponds to the node and freq means how many numbers locate between [L, R]. Thus we can query the corresponding information on the segment tree.
We can use a segment tree to keep xj,and query [xi-ri,xi+ri]. If you are worried about the memory,we can make a discretization for every fj,or we can ask for memory dynamically.Then we won't get MLE.
Oh,my fault,we should iterate stations from smaller ri to bigger ri,and then we guarantee ri>=rj. I said:"we guarantee ri<=rj."In fact,it is useless.
I think you were right when you said ri <= rj
Ok, you are wrong.
If we iterate from smaller to bigger, then for xi, counting total xj such that xi-ri <= xj <= xi + ri, wont work, because even if the station xi can reach xj xj won't be able to reach xi because it has(or can have) smaller range.
There is little mistake, "we should iterate stations from smaller ri to bigger ri", we should iterate stations from bigger ri to smaller ri. Then we guarantee that xi-ri<=xj<=xi+ri where j < i
Yes……You are right……we should iterate stations from bigger ri to smaller ri.
Cannot get D solution. Help >.<
how to solve D,even after looking at editorial,i m unable to figure out the solution
Good day to you,
well the key observation is, "what moves can you do" if you are on coordinate x (up to N) and y (up to 3)?
A) You can move to any other "y" {including itself} and continue to next "x", adding the proper values
B) [if you are on y==1 or y==3], you can move to y==2, go back (as far as you can) to go to last y and return back being on it [i.e. if you was on "1", you end on "3"]. Here you add all values till the place where you made turn.
So here it is, that is all you can do — what to do with it?
Firstly imagine we have only "A" {B is harder}. Well, this shall be easy, it can be done by DYNAMIC PROGRAMMING [since you only move to greater 'X' and all 'Y' stuff can be solved locally]. You can move to ANY 'y' and continue to next 'X'.
Now, we want to extend this to solve "B" too. This might seem problematic, because it is forbidden [in DP] to return BACK. We also have no information about where we left space of size 2 (to y), so we could eventually do the move [this would cost another N]. The possibility which remains is to PREDICT the moves. In fact, you don't have to "count anything or so...", you just TRY and take if better. To do such prediction, you have to stand at "y==1" or "y==3" (as mentioned above). This will SHIFT you into prediction stat (switching to "1→3" / "3→1"). You can continue with this state as far as you want, keeping "shifted state" and adding ALL three values.
So basically, you will take maximum of:
A) Go to any Y and go to next X
B) Switch state and go to next X
while adding proper values.
This can be stored in array of size "[N][3][2]" → "[X][Y][state]" {and I guess it might be reduced even for the state}.
Complexity will go to (N), since the calculation in each state will be around "y" (i.e. 3), so basically constant
I'm very bad at explaining so don't hesitate to ask more questions!
Good Luck & Have Nice Day!
please elaborate part B,how your solution is ensuring that it won't miss any cases,basically i didn't get part B ,thank you :(
Oh yes.. I'll try: Imagine you want to return. The (with size of 3), you can't do that with some space "inside", so you will have to go through all 3 positions. Anyway, basically, it doesn't matter what happened before and what will happen after, what you will do is clear: you will go through upper row (or vice versa lower row) and at some point you make turn, go through middle row BACK and finally go by lower row (or upper) forward.
Reminding it doesn't matter what happened before/after — everything can be managed with "**A**" — this case only covers "3*K FULL rectangle", to which you will step on y=1 and end on y=3 (or vice versa).
This is about what it means — now how to solve with "recursion" — you can have "bool", which states, you are in phase. If you are in this phase, you can basically do two things "I" — leave phase [so you just switch off bool] or "II" continue phase (adding all 3 fields to solution and stepping to next "X")
PICTURE:
Here, you can see what the "B" means (B1,B2). On right side, you might imagine, that you are on X==5, Y== 1→3 and on PHASE, then you can do two steps:
I) Leave phase: You will continue freely with A (or enter phase again, as you want)
II) Continue phase: You will do, what is in last figure [as you can see, it is not, what you can really do, but thanks to this notation, we can extend it this way → harder for imaginations]
Is it more clear? :O
yeah clear
I personally need more hints to solve D.
First of all, think about everything without stepping left.
Then add: When you are at each point, think about what other points you can reach with a path involving a step back. There are not many possibilities.
That's at least how I did it, there might be easier ways.
Nice editorial. I really liked D, the hints are great, while not telling too much :)
is it correct to print the longest common subsequence in problem C ?
no, O(n2) is not enough
Also, LCS wouldn't always be the right solution. Consider the below case:
A: abcdef B: abxcxdef
LCS: abcdef
however the answer would be: abdef
Why the solutions are showing judgement failure?? HellKitsune
Could somebody please explain C to me? I really don't understand what this stands for: "For every prefix of B, count how big of a prefix of A you will require." Same with suffix.
Update: I understood now.
Please share your understanding. Even i am having difficulty understanding question. Thanks.
Let's count what prefix of A you need to get every prefix of B. First let's look at prefix of B 1 character long. To get that prefix you need one character that is same as the first character of B, but from prefix A. Increase your counter until you find the first character from A that is equal to this first character of B. That's p[0]. Now let's count p[1]. You need p[0] to get the first letter and you also need a character from A that is same as the second character of B. So just increase counter starting from p[0] until you find this second character. And so on... Do this for suffixes now and the rest is easy.
Thanks man....i just have some doubts, which i would try to clear by myself, else would ask you. Good explaination, +1
One more solution for E. set operations. Then remove current station from its set to avoid counting some pairs twice.
set operations. Then remove current station from its set to avoid counting some pairs twice.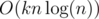 .
.
Store stations in map: frequency --> set of stations.
Then sort all stations by range, from smallest to largest.
Now iterate over stations in order of increasing range.
For each station iterate over neighbour ([f - k ... f + k]) frequencies and count stations in the current range using
The whole solution is
P.S. The only problem is that STL set cannot quickly count number of elements less than x. Thus this solution is painless only if you have your own set implementation with subtrees' sizes stored in nodes of BST.
Very nice and simple solution! I implemented your solution with GCC's order statistics tree and got AC.
http://codeforces.net/contest/762/submission/24472173
Thank you! I didn't know about these cool GCC extensions :) I should definitely learn about them!
In your solution ans should store total number of bad pairs. Could you please tell why you did ans-n instead of outputting ans.
Please explain D,i still don't understand.
Let me try to explain my solution.
Any vertical cut (segment between cells) in the grid can be intersected by any simple (that is, without self-intersections) path only in 5 ways (two first are top-down and bottom-up):
Now you can maintain dynamic programming array dp[i, way],
where i is x-coordinate of the cut and way is one of 1a), 1b), 2), 3) or 4).
dp[i, way] is the largest sum of cells located to the left of the cut
that can be traversed by a simple path intersecting the cut in the way way.
For example, let's consider the way 2). If you draw all the possible cases on the paper, you should get
The answer will be dp[n, (4)].
can please you explain 1a & 1b a bit more clearly and what about going to the left? thanks for your kind help
Let's consider any simple path going from top-left cell to
bottom-right one. Surely it must intersect our cut. But in what way?
If it intersects the cut only once, then it can be only the case 2), 3) or 4).
Can it intersect the cut exactly twice? Of course no, because the path must
end in the bottom-right corner. So it intersects the cut one or three times.
In the latter case (3 times) the first intersection is left-to-right,
the second is right-to-left and the third is again left-to-right.
At first glance each of these intersections could happen in any of three
rows, for example, the first in the 2nd row, the second in the 1st row
and the third intersection in the 3rd row. But if you take a sheet of
paper (and I strongly advise you to do so) and try to draw
a (simple!) path connecting top-left cell with bottom-right one and intersecting
the given cut in the described way you will certainly fail.
In fact, there are only two ways to perform such intersection.
The first looks like "top-down zigzag" and the second one like
"bottom-up zigzag". These are cases 1a) and 1b) and there are no more cases.
There is no need considering "going to the left" because we
are talking about all possible simple paths connecting two given cells.
Easy to implement solution for E:
Time complexity: N * logN * (logN + K).
It is based on the idea of 2D interval querying, but taking into account problem restrictions uses Fenwick tree with map as a value(in this map — frequency is a key). Using the fact that map is ordered we can get all needed values with frequency = [f — k ... f + k] in logN + K instead of logN * K.
http://codeforces.net/contest/762/submission/24558456
In problem F: "Now let's enumerate subtrees (rooted ones!) of T". Does The author mean "isomorphisms of T"?.
can Someone Explain What this error implies in java: Source should satisfy regex [^{}]*public\s+(final)?\s*class\s+(\w+).* I am new in programming as well as new in codeforce In advance Thankyou
Just add
public finalkeyword before the class keyword. like :What might be the approach for problem D if instead of a 3xN, it was a NxM problem?
An alternative solution to Task E : 1. Sort the array on the basis of ri. 2. For each possible frequency, have an ordered set (It will store the x-coordinates). 3. Start traversing from highest to lowest ri, and for each frequency between [fi-k,fi+k], count the number of elements xj satisfying xi-ri<=xj<=xi+ri. The only those coordinates of elements would be present in the set whose r>=ri. After traversing through the frequency range, add the current xi to the corresponding set. My Solution
Hate to necropost, but I need some help, can anyone help me figure out why my code gets MLE here? https://codeforces.net/contest/762/submission/194307712
I am using 1e4 wavelet trees and the total memory consumed should be O(N) (N = 1e5), so I have no clue why this exceeds the memory limit. Any help is appreciated.
Didn't want to necropost, but have a question.
In problem C one may leave different strings to be the subsequence of $$$a$$$, with the same minimum deleted length. For example, if $$$a$$$ is
abcdcbaand $$$b$$$ isabdcdba, the answer may be any ofabcdbaorabdcba. I've tried some AC solutions, some of them output the first, and the others output the second.But in both statement and output section of English and Russian statement(I use machine translate to read Russian), I did not see any words about multiple solutions.
I wonder whether the problem has such a testcase with this kind of input, and whether the checker checks correctly. Could you(or, anyone) please tell me(if I do not misunderstand the problem statement) the answer and fix the statement? Thanks in advance.