


Hi everyone!
We invite you to participate in Codeforces Round #429, wich will take place on August 18th, 18:05MSK.
The problems were set by Fedor Mediocrity Korobeinikov and Vlad totsamyzed Mosko. Special thanks to Alex netman Vistyazh for helping to prepare the round, Alex AlexFetisov Fetisov and Vladislav winger Isenbaev for testing problems, Mike MikeMirzayanov Mirzayanov for Codeforces and Polygon systems.
Participants of both divisions will be given 5 problems and 2 hours to solve them. Scoring will be announced before the round.
We hope you'll enjoy our round! We wish everyone good luck and high rating!
UPD: The scoring is: 500 — 1000 — 1500 — 2000 — 2500. Note, that number of tasks changed from 6 to 5. Also great thanks to Alex Um_nik Danilyuk for testing problems.
UPD: We are really sorry for our awful english statements.
UPD: The round is finished. Sorry for inconvenience again. Congratulations to the winners:
Div1:
Div2:
UPD: Editorial.






Let's hope cp will become a real sport. And let's hope for short statement too :))
After all Hope is a good thing, maybe the best of things! :')
And no good thing ever dies! :')
Short announcement, short problem statements. Hopefully.
Boy you were so wrong.
Unfortunately yes. Though long statements wouldn't be a big problem themselves...
There is a codesprint on Hackerrank one hour in the midway of this contest.
Is he from Game of thrones?
It's from LotR. See here.
One doesn't simply walk into Mordor from Westeros.
Assuming that any contest clashes with a CF contest, It can only be bad for the clashing website and not for CF.
If HackerRank care enough about their own, they should change timings, not CF.
I kinda disagree as there is prize money for the top 7, so those top rated participants might go for that instead.
just look at the leaderboard on hackerrank. and then say a word bro...
Gennady finished the entire contest in 29 minutes. It took me more than half hour to understand all the problems properly.
It's a two day contest, that's probably why this round didn't yield way.
but the first hour is the important timing for those who wants to win top places(not me of course)
Never mind.
Who will be the main character of the round?
New round, means new chance for better performance and improving our rate.
Chance of learning new things
I think the winner is obvious.
Not after Rudy1337 registred.
they are not even the same division
He just doesn't want to scary tourist, that's why he participate in div 2.
Why so salty man? Still mad that you sucked at IMO?
UPD: WTF I was not expecting upvotes.
Why is it salty? Did i offend aomeone?
Anyone who knows sarcasm will understand it. Can't understand if you really hate him, because he did better than you at IMO or you're joking too hard.
miro registered too so I got no chance :'( Although I heard there are problems that even he can't solve
tank you all for contest. and hope for statement be as short as blog.
R.I.P English
Sorry for bad english :)
Where is KAN?
Hi , I just wanted to ask that whats the difference in div 1 and 2 like can we say that Div 2 E,F > Div 1 A,B,C,D in terms of difficulty?
Usually, Div 2 C/D/E.. is the same as Div 1 A/B/C.. and so on. The difficulty is in the increasing order.
Are 2 hours good for 6 problems ?
do you want to full ?
What do you think bro, my color still f*ckin gray :3
We don't judge people by their color here <3
Sharon are you sure ? :"D link1 link2
All colors are equal, but some are a bit more equal.
Good, I'll try make website and make the rate by hair color so you know overages coders will be gray newbies
Animal farm..
I wonder what is the story behind your rating graph, totsamyzed. Are you going to be our next dreamoon_love_AA?
I think this guy is also hero
I hope we will have an interesting contest tonight:) GL
OMG :O ThePilgrim Registered for this contest :O
Who is he? :/
he is sad ,he is hurt ,he is dying ,he is lonely ,he is a mess ,he is judged ,he is ignored ,he is suicidal ,he is depressed ,he is misunderstood ,he is tired he is SmSS
Kool(Sorry for my bad english)
London is the capital city of Great Britain
?
Why was number of problems changed?
because time was not good for Abdo_Naser !
he want to full :D
Link
Probably they found an issue with one of the problems.
why not ?:)
someone hack your code is so better than judge do it :D
He'll find and kill the judge.
Not the right place for this post, but could some of the contest organizers or idk inform CF staff that email system isn't working. Thanks
Did Um_nik save rated contest? :D
Not all heroes wear capes.
I hope this time the tests were weak instead of author's mind.
totsamyzed, don't make us sleep during the contest.
and during system tests as well. :)
Wish not granted :D
Please open additional registration! Why is it even closed? I have not expected it would be impossible to register after the competition started
so many spelling mistakes.
having trouble guessing the meaning of div2D
and even no explanation of the Sample
took me a good 10 minutes to get it too, but what do you want, it's all part of the challenge !
I asked for clarification of sample cases. Reply was "read the statement". No i'm asking for clarification without reading the statement -_-
RIP English
I'm sorry, but these problem statements are all cancerous. When you see a red squiggly line below your text, that means you have a problem. Don't submit text with a red squiggly line under it.
What the heck is F(n,k)???? So much broken english...
I don't get it, why do you need F(n, k) if you can guess the solution by sample cases -_-.
English is my first language and I can't understand Div1 B. It's riddled with typos and the grammar doesn't make sense.
Can someone clarify: "Subset is calling «good», If we save in a graph only edges from subset , and for every vertex i will correct, taht di = - 1 or it's degree modulo 2 is equal to di."
G=(V,E) is a graph, with V its vertices and E its edges. A subset S of E is called "good" if in the new graph G'=(V,S) we have the following property: for any vertex i in V of G', we either have d_i = -1, or deg(i)%2 = d_i ("deg" meaning degree, the amount of edges in S that are incident to vertex i).
(hope it helps, though it's a bit too late now i guess)
With due respect to the setters, seriously, what is that? I haven't yet understood the statement of problem A and B -_- RIP English.
Neu languache unlokt für CF: German
Was excited for a rated round :/ 6 more days i guess.
I'm going from one extreme to another :/
After reading ABD, I had no option other than withdrawing participation.
Worst problem statements I've seen on codeforces in a long time. Very disappointing. The proofreaders are all on vacation or something?
Div2 D is a total disaster. Can't understand anything! RIP English!
Horrible problem description! :/
Delinur, where u at when we need you?
You should really make this unrated. This is not English.
Horrible statements, and they're also not answering my questions. Not to mention zero shts were given with regards to the statements' coherence and story.
As if we could "save in a graph only edges" from a subset... Really, how old are the proofreaders? Freaking 5?
Okay, this is getting ridiculous. This is what I get when I translate from English to Russian to English.
Lech plays a computer game where at each level a connected graph with n vertices and m edges is given. Graph can contain multiple edges, but can not contain loops. Each vertex has an integer di, which can be 0, 1, or -1. To pass a level, it needs to find a "good" subset of the edges of the graph or say that it does not exist. A subset is called "good". If we save only edges from the subset on the graph and correct for each vertex i, that di = -1 or the degree modulo 2 is equal to di. Lech wants to pass the game as soon as possible and ask you to help him.
At least that's understandable.
And yet the last Announcement says "Loop is an edge like (u, u). Loops are not allowed. Cycles are allowed."
Loop is an edge similar to (u, u). Cycles are not allowed. Cycles are allowed.
Not like this. Not like this...
What is the problem with that?
Never seen so many announcements in a single contest :/
when an announcements published I thought my solution hacked :\
Thanks for closed registration
Man dis, shit is aw full following time I am save Russia probs text in, google translate and read 'from they're.
Man, shit, complete, after I save Russia, ask for the text, translate and translate the text "from them."
Well I think the best method of reading grammatically incorrect sentences is to translate to Russian and then back, I guess.
When your problems' themes are so thin like that (really, Leha somehow found arrays and queries in pockets?), you'd better off not using any theme at all. Just state the problem without involving Leha in any way. For example, Div1D (what I mentioned above) should just be stated as "You are given an array of n numbers and q queries l r k...", so you don't need to stare awkwardly at why Leha's pockets are of any relevance.
Say what you will, I still think that
"Mom brought him two arrays A and B"
Is the funniest thing I've read in a long time
Hands down one of the worse contests. Close to 2000 people passed pretest in C but less than 50 is able to solve D. The difficulty is so low in A,B,C that difference in ranking is explained by whoever understands the statement first.
Codeforces has just pulled off a codechef.
the predictor isn't working for me .
does anyone have the same problem ?
yeah
I jumped directly to the Problem D, its been an hour and still I am not able to understand the question at all. So many mistakes in the spelling and explanation, I am leaving this round :(
can someone give me brief idea of sample test 2 of Problem D , how is the answer 0 ??
It means: Find a sub graph of the given graph, such that for every vertices i, if d[i] != -1, then the degree of vertices i in the sub graph module 2 should be d[i].
And you're asked to output the number of edges in the sub graph k in the first line, then k lines follow, indicating which edge you'd decided to remain in the sub graph. Edges are labeled in the input order.
So, for test 2, a simple answer is to leave nothing in the sub graph, so 0 is acceptable. Another proper answer can be
4
1
2
3
4
BTW, this is the worst description I'd ever seen. I believe even google translate can do a better job :(
Isn't 0 good for every graph then?
So why 0 isn't good for sample 1?
Problem C and D (div2) are awful. They didnt even provide good sample test explanations as well. And I dont know who are the heads of CF?? I mean, come on, after all this time you should at least look at the problems before deciding it is "contest-worthy".
My code gave TLE in C++11 and got PRETESTS ACCEPTED in C++14 :( Is it my fault or Is their any way so that my penalities are taken back.
Please someone suggest me on this.
yeah I lost 150pts for penalty and 160pts more for wasting time until I see this comment :<
time run of 2 version is different. If you use "cin/cout" in problem B without something else, I think it must be TLE...
I used Fast I/O but the result hasn't changed
What a shit contest. Div 2 D is hardly being understood and C is being solved by even those who might have never solved any other C in their lifetime.
true, still made it harder for myself didn't read a[i] >= b[j] , hope i don't get a tle .
I also got myself fucked in A because of a fucking reading mistake. And the sad part is that I locked the problem as soon as I submitted. :(
Moral of the story ; Dont lock the problem unless you don`t see one or two hacks in the room.
you haven't solved any C in any contest so far, so you dont have any right to comment like this
I have solved C twice before too.
The only thing is that, I got WA in systest in either A or B in those contests.
Do your research properly from the next time.
Just because someone has solved 2 problems in the past doesn`t mean that it needs to be A and B only.
And I was not talking about this in-fact, I meant that there are people who haven`t solved a C even in practice sessions, and even they have solved C today.
I never solved E . Not even today. It looked easy today :p
Was expecting short statements but not this short...
I passed Div2 C just by reading examples :D
I think most did same:)
So.. Is there a necessarily proof that it's correct to do...whatever we did?
Me too
F(n, k) =(n+1)/(k+1)
I have just generated values and observed the pattern
The function F(n,k) is largest when k is 1 and smallest when k is n. So you want the difference between n and k to be as large as possible so you can maximize F(n,k). So just pair the numbers so that the sum of differences is as large as possible (I think greedy pairing works for that).
It's not exactly a formal proof but I think it's correct.
I think this would give you the sum of expected values
We can naively say that in order to maximise sum we need to maximise A[i] - B[i] + 1 . But that's not a rigorous proof either
Once you prove/guess that F(n_i,k_i)=(n_i+1)/(k_i+1), the question is how to maximize the sum. The answer:
https://en.wikipedia.org/wiki/Rearrangement_inequality
So to maximize in this case, we need to sort (n_i+1) and 1/(k_i+1) in the same order, which is equivalent to sorting n_i and k_i in opposite orders.
how is ?
?
For each m<=n, look at the subsets of {1,...,n} whose minimum element is m. There are (n-m)C(k-1) of those (because once you choose m, you have to choose k-1 remaining numbers from {m+1,...,n}.
Thus, the weighted average is the sum of m*(n-m)C(k-1) , 1<=m<=n, divided by nCk.
Using some basic identities (hockey stick), this simplifies down to (n+1)/(k+1).
Yeah I was able to derive the formula , but how do you get all terms cancelled . Also what do you mean by hockey stick ?
https://en.wikipedia.org/wiki/Hockey-stick_identity
But after thinking a little bit... it's not even needed! There's a simple bijective proof that the numerator equals (n+1)C(k+1).
If we choose k+1 numbers from {0,...,n}, and throw away the lowest number, we get k numbers from {1,...,n}. How many times does each k-set get repeated? Precisely its minimum-element number of times!
DELETED (Sorry for my mistake , I get it) .
Nope, if you take a subset of size k+1 of {0,...,n} and remove the lowest element, you will always get a subset of {1,...,n} of size k.
I love this proof as it is so elegant and straight forward, yet, I still want to know how would you get rid of the (j*) prefix from this formula.
Then use the hockey stick formula for the inner sum, and again for the outer sum.
Thanks, got it now. :)
"Thus, the weighted average is the sum of m*(n-m)C(k-1) , 1<=m<=n, divided by nCk."
1<=m<=n? why till n? shouldn't it be till n-k+1?
Sure. But it doesn't matter, since if m>n-k+1, the binomial coefficient will be 0 anyway.
This is one of the frustrating things about competitive programming that make me hesitant to participate again. It is possible to get a problem accepted without being able to argue about the correctness. In mathematics and real CS, this is nonsensical, useless and completely unacceptable.
Competitive programming is not math/CS. (I myself am a math/CS person, but I know that in competitive programming I might not need to prove correctness. On the other hand, having math/CS background helps to give intuition whether an approach will likely be correct or not.)
It can be mathematics/CS if one takes the time to understand the reasoning. The fact that it sometimes encourages non-sense (by not requiring the contestants to actually understand their solutions) is one of the reasons I think it's sort of overrated. There have been times when I got introduced to some graph algorithms and was able to code them in a competitive programming environment without having a clue about why they worked. It's a relief that those times are over. I think many competitive programmers just use "pattern recognition" (of the form "I have encountered a similar problem before" or "the samples reveal a plausible approach") and end up ACing problems with a minimal or even nonexistent amount of the much-needed rational thinking. (Yes, I believe that is the case too for a number of competitive programmers who are highly rated on this site or even scored IOI medals and the like). Over the time, I realized that writing formal proofs and good code is more enjoyable for me than competitive programming.
I think this is somewhat a fault on the problem setter's part — had they asked for the value of sum(F(A, B)) it would requires a prove for it. (Maybe they didn't asked for it since it's just Div2C .... but yeah I would rather ask for full feedback and use it as 2D or 2E)
Worst Div2C ever!
same here. but C and D had the worst sample explanations ever.
Spent plenty of time Prooving and the greedy is correct during the contest, although I had observed the feature in the sample. Sad.
and the greedy is correct during the contest, although I had observed the feature in the sample. Sad.
how?? I am still confused as to what the question means and a lot of people have seemingly solved it by seeing the samples.
"Consider all possible k-element subsets of the set [1, 2, ..., n]. For subset find minimal element in it. F(n, k) — mathematical expectation of the minimal element among all k-element subsets."
This statement does not make any sense to me
Consider all k-element subsets of the set {1, 2, ..., n}. For each subset, look at the smallest element in it. For example, when n = 4, k = 2, you have the following:
Define F(n, k) as the average of all these smallest elements. So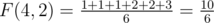 .
.
You know you are 100% sure of your solution when you lock your problem even after getting hacked
photo
Actually I got that "hacked" notification real late. After making an unsuccessful hacking attempt on someone's code, I got the notification that my code has been hacked -_- . Don't know if it was my internet problem or something else.
I should have read the Russian statements.
I don't know how to speak Russian but it can't be worse than the English statements.
D is easy if you can understand it. I understood it but I can't solve it :'(
Is there anyone who got TLE in B div-2 just reading input and printing output
what is your language if C++ use scanf and printf
use
ios::sync_with_stdio(false),cin.tie(0),cout.tie(0);
change language to c++14 if using c++11
Yes T.T
Me seeing the succinct statements>>>> hell yeah!
After reading statements>>>> wait, what ?
Problem D blew up my brain, how to solve it?
I think if there is a -1 node, then an answer can always be formulated. But other than that, no clue
When there is a -1 vertex, you can simply do a dfs and solve it greedily. When there isn't any, if the number of 1 vertex is odd you can't solve it (the sum of degrees of the subgraph should be odd which is impossible). This is as far as I got, in the case which is left I believe you can greedily solve it aswell but I'm not sure.
I'll call d[i] == 1 vertices black and d[i] == 0 vertices white.
So given the case where the number of black vertices is even we can solve it greedily.
We can consider any spanning tree of the graph and do a dfs, let it return 0 if the subtree is solved or 1 if it is unsolved. Hence Black vertices are unsolved and white vertices are solved. Then we will put the edge to the parent if it is unsolved.
If the parent is solved but not the subtree, after putting an edge the parent will become unsolved and the subtree solved.
If the parent is unsolved and the subtree aswell, both will become solved.
We can see that the parity of unsolved vertices is always the same, while running this dfs is simply pushing these unsolved vertices up. Then if the black edges are even at the start, we can simply push them all up the root of our spanning tree.
There is an answer iff there is a -1 or there is an even number of 1's. You can then get the solution by doing a dfs and just greedily selecting edges you need on your way back up.
Can you please elaborate why is there always an answer when d[i]=-1 for some i.
It doesn't matter what degree the -1 node has, so all of it edges can be arbitarily choosed or not choosed. By using this we can fix every adjacent nodes to have correct parity degree, because we can either choose it's edge to the -1 node or not. After that we can make sure the nodes adjacent to the nodes adjacent to the -1 node are good, and so on. Because the graph is connected, we can make every node's degree good.
Going by that logic if we satisfy parity of 3 using 1(the -1 node) we get stuck,don't we?
4 3
-1 0 1 1
1 2
1 3
3 4
Why does this submission give WA on TC 5 and this submission give AC, when the only difference is the equality sign in the comparator function?
I think that the first one should also give AC..
Compare function must return 0 if they're equal.
Why? How does it make a difference?
Do you think 1 million number 10e9 can be read with ONLY "cin" in 2 seconds?
before reading
Yes, I know it. But someone don't write it and still get AC pretest with 1800-2000ms ._. ._.
Maybe they use different compilers?
I think pretest don't have 1 million number 10e9 :)) it have smaller :))
i forgot to use ios_base::sync_with_stdio(false);
but i tested my code on local machine with 1000000 10e9 and got 1.53 ms (my machine is way slower then cf machine)
here is the victim http://codeforces.net/contest/841/submission/29559824
WHY
Typically I would be unappreciative of the meme, but I feel it has real value here. Thank you for positively contributing to the Codeforces community!
I got Unexpected verdict on my hack in the solution on problem A and receive this result. What does it mean?
Probably someone hacked before you and you didn't reload page to see that. It happened to me in some contests too.
That was not the case.
I tried to hack Mr.Donaldo three times using the following testcase: 5 2 aaaaa
and then received this verdict.
KAN
I too had the same problem, in fact with the exact same person.
Both of your profile pictures also...
Dont get me wrong, Mr. Bean is <3
How to solve D?
pick K elements which are different and remove them from the array permanently , keep repeating this process , in the end , we will have atmost K-1 elements left , those are the only possible candidates for our answer , this can be simulated with a segtree easily.
Note that K=2 version has appeared before several times.
Version with K>2 is also well-known and even appeared in some companies interviews
I think you can just check the frequencies of all the possible candidates for the answer. Sort the subarray. Let sz = (R-L+1)/k. Then the only possible choices are the elements at indices sz+1, 2*sz+1, 3*sz+1... while <= R. Check frequency of each and if any of these satisfy the condition, then that is the answer.
Time complexity is O(N*K*logN)
Code
Elegant solution.
Is there a better solution to D that NlogNKlogK if no , then why is the time limit so strict.
There's funny solution to Problem D which it's complexity is O(cnlogn) or O(cn).
First, We randomly choose the answer in interval [l, r], then check it.
For even k = 5, there's nearly 0.2 probability that we can find it.
Assume we randomly choose 90 times, we can deal with each query with correct probability 1 — (0.8)^90 = 0.99999999810286240993581145418021.
So for a each testcase, the probability for all the queries are right is 0.99999999810286240993581145418021^{300000} = 0.99943102065261594539434408072871.
We need to pass several testcases, assume there're 100 testcases, We can get accepted with probability 0.99943102065261594539434408072871^{100} = 95%.
That's our destiny.
i would have definitely submitted this if we had full feedback with all test cases , but with pretests i preferred not to do this.
Sure, I do not have the ability foreseeing the risk
How do you solve it in O(c·n). How do you find the frequency of an element in an interval [l, r] in O(1)?
offline
How to do this offline?
29579955 UPD:My friend's PRETEST-PASSED submission.(despite getting TLE)
And you can use some simple technology to reduce the complexity to O(cn). Something like Random for each query at first, then get the answer while inserting the elements to a hash-table.
I did with something like sqrt decomposition and it atleast passes in pretest < 500ms
Set Freq = 300. Max Number of heavy elements having > Freq = 1000
Process all queries on heavy elements independently. Elements having freq <= 300 can only be answer where r-l+1 <= 1500. So bruteforce on those light queries.
Something like O((N+Q)*1000 + (N + Q)*1500)
Probably to defend straightforward Mo solutions.
straightforward Mo solutions.
I couldn't pass with some constant factors. I'd say TL is definitely more strict than it should be.
with some constant factors. I'd say TL is definitely more strict than it should be.
It is possible to solve it in time O(NKlogN) using a wavelet tree.
Can anyone provide a proof for Div1 C?
I got nowhere by trying to analyze the expected value.
Ok so I almost hacked V--o_o--V's solution for D but I couldn't submit the file because it was too big...later on, I got the answer to my question that I should send the generator...I guess nothing else can be done, now, can it? generally, what sort of syntax should the generator have? I mean does it write the test to standard output? What language should it be written in?
You can choose among many languages. Yes, it should print the test to standard output. Once I luckily got 7-th place in Div2 which could have been 5-th if I knew this. I guess we both learnt it the hard way :d
How to hack his solution? And what's the probability of hacking? :)
A test with 60001 of 1 and the other values all distinct that's querying the interval [1, 300.000] 300.000 times would be just enough. The probability for his solution to work on one query is P = 1 — (4/5)^40. The probability for all the queries to work at once is P^300000 ~= 1e-14. It was failing on my machine after less than 20.000 queries usually. So it was sure deal:))The constant that he chose made it easy to hack. On the other side, if it were much larger than that, he'd get TL
I have 80 as constant :D
Had pretests passed, not sure about TLE.
But seems like it's going to fail as well.
On my test, you get 99.4 percent probability of correctness, which is pretty much enough I think. Even if this extreme test were used 100 times in a row, you'll still have a 58 percent chance of getting AC, and for sure there won't be more than 5 or so tests like this one. Also, this test is the worst scenario, so it seems your solution will pass. If they really wanted to make sure it wouldn't pass, they'd have put K <= 8-9 which would destroy any such approach. Honestly, though, I find the randomized approach quite elegant
I had tle on pretests in systesting lol
CF admins, why do you let it happen? 674G - Choosing Ads
Am i the only one who solved Div.2 C by just looking at the samples, without understanding what the author wanted???
I did that too.
Me too :)
Waiting Petr screencast to see myself being hacked. :)
Sorry, wasn't recording today :)
:( . I hope you have another chance to hack me.
haha xD
What kind of screencast do you provide?:)
Very bad statements (Guys using the Russian statements have an advantage), Long queue at the first 30 mins, Very weird hacking/locking problems bug in my room (not sure about the others).
This contest will be unrated right ?
rated or unrated, I really hate to say this (cause CF really helped me improving a lot) but last few CF contests were really awful and not to forget that there were back to back two unrated contests.
Anyway it was understandable, mistakes were grammar mistakes.
Usually I don't complain about grammar if it costs me a few minutes. But today's B took me 45 minutes to understand, and only after backsolving from examples. When variance in read times dominates variance in solve times, then we're measuring the wrong thing.
It's not like I didn't try either; I asked very early on for clarification, and got no response.
Yes, you are right. Div2D/Div1B statement was very bad.
Am I the only person that all problems felt too hard? T_T
I was trying to hack @MrSoab B solution with ai=10^9 and n=10^6 it was giving me invalid input why?
then I tried with ai=10^7 and n=10^4 and got unsuccesful even though his sum variable should overflow as he declared it as integer
1) Because you can upload only 256KB input test (maybe) 2) overflow don't mean result is wrong :))
Exactly, even if it overflowed the parity was the same, so depending on the language it wouldn't get hacked.
Div. 2 C and D were both shots in the dark for me
I guessed a solution for div 2 C based on the examples and it passed the pretests. I sorted A and sorted B in reverse and paired them. But is it actually the solution? How does one prove that this works?
Prove that if n1 ≥ n2, k1 ≤ k2, then F(n1, k1) + F(n2, k2) ≥ F(n1, k2) + F(n2, k1), so it's always at least as good to assign n1 to k1 and n2 to k2, instead of n1 to k2 and n2 to k1. This means if you sort B in increasing order, you always want to have A sorted in decreasing order, since otherwise you can do better.
it works because we have min(A)>=max(B) and we have to maximize the sum of A'[i]-B[i] .
Achievement unlocked : Successfully challenged a randomized solution
http://codeforces.net/contest/840/submission/29578088
Phew, I pressed the hack button while hoping that I won't be very unlucky.
And I pressed the submit button while hoping that I won't be very unlucky :P
That statement seemed so apt for 'L' to say, with that profile picture. :D
How to solve Div 2 D ?
If it's a tree, the problem is trivial. But it turns out that the extra edges don't have to be used... so just treat the graph as a tree.
It's possible if and only if the number of "1" labels is odd. So if there are any "-1" labels, it can always be done (replace all "-1"s with "0"s, except for possibly one "1"). Then do a depth-first search; the edges adjoining the leaves are forced, which forces all the edges all the way up to the root.
Can you give me some similar problem to this, which you called trivial? I wanna try to solve that problem
What I meant is the following.
Suppose we have a tree (connected graph with no cycles). In this tree, the vertices are labeled 1 and 0; the goal is to choose a subset of "special" edges such that the vertices labeled 0 have an even number of special edges adjoining them, and the vertices labeled 1 have an odd number of special edges adjoining them.
This problem is quite straightforward, and once it's solved, it's easy to extend to a generic connected graph (even with multiple edges: it makes no difference).
can you explain why
the extra edges don't have to be used..In a cycle, every node has degree 2. That means that if you remove all cycles from your solution, it will still be correct.
Div2 e. Kirchhoff's theorem + Gauss method? I just couldn't find matrix determinant.
The answer is not determinant of the adjacency matrix, it is the permanent. Computing permanent however, is NP-hard.
The task statements were very bad, but I think that the tasks were still understandable after reading them a few times. It's very annoying and should have been fixed before the contest, but it's really not a reason to make the contest unrated.
That moment when you don't understand any of the problem statements and manage to solve them successfully. xD
Read test and write solution :)) :))
The task 841B How is it possible to have TLE on the pretests for the loop from 0 to 10^6, used to input data anyway, with the task's limit of 2 sec. GNU C++ 11 Thanks.
Maybe it's an issue with cin/cout being slow? Use ios::sync_with_stdio(0) and cin.tie(0) .
The Problems' statement was understandable to some degree,maybe was below average this time,but you could understand it.. that's how it was for me, It shouldn't be unrated :D
Sorry, I didn't understand your comment.
I can see where the problem lies now :)
Got TLE on B using simple input , output only Can't understand why???
Apparently, you need to use the IO 'accelerating' lines at the beginning of your main (if using C++):
to stay within the time limit
Any hints for Div1 E?
Divide all mask into two halfs.
Process all numbers within path by blocks of 256. For each bottom vertex of a block and each value of biggest 8 bits of XOR we can precompute the partial answer in 8 * 256: for each number there is a unique value of biggest XOR bits that make 11111111... after XORing (these will obviously be largest answers in their groups), after that traverse a tree from bottom to top and fill still unknown values by swapping smallest bit possible.
How to solve Div1 C? Ok well we can divide the numbers into some equivalent classes.... and so what?
--nevermind, this is probably wrong solution
Say you divide the array in groups of sizes X1, X2, ..., Xk. For now, lets consider all of the members of same group identical. In other words label them, and add a constraint that they appear in that fixed order.
Then, say there exist xi indices in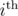 group, which have next element in the permutation belonging to the same group. Then the number of such orderings is:
group, which have next element in the permutation belonging to the same group. Then the number of such orderings is:
Now, we can just use inclusion exclusion on the total number of indices where the next element is in same group. Such a term must be multiplied by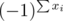 when added to the total answer.
when added to the total answer.
To find the sum over all tuples of xi, we can use polynomial multiplication.
In the end, multiply the answer by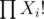 to account for orderings in same group
to account for orderings in same group
I think this could have made a good FFT problem.
If I understand correctly the answer is:
but could you clarify how this can be calculated using polynomial multiplication? I can't think of how to separate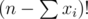 .
.
Let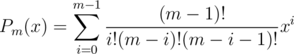 ,
,
Then the answer is coefficient of xn in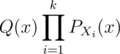
So, we can actually solve the problem in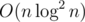 instead of O(n3)
instead of O(n3)
29575088. This one is O(n2)
Thank you, that clarified a lot.
f(i, oldBad, curBad) = ways to place i, i+1, ..., n-1 if we have placed 0, 1, ... i-1 and there are curBad pairs of consecutive numbers of the same class as i and oldBad pairs of consecutive numbers of the same class, but different of the class of i
answer is in f(0,0,0)
I guess you can figure out the base cases and how to do the recursive step :)
https://csacademy.com/contest/archive/task/distinct_neighbours then you solve this and you're done. It has an editorial, a really nice dp
Lol, I opened that problem and it is solved by me. But I didn't manage to solve it again today [facepalm]
What is the time complexity of the DP solution described in the editorial? I'm having a hard time trying to figure it out.
Indeed, it wasn't trivial to compute. At the time I solved it, I computed an upper bound of N^3
At first glance, it seemed N^4 to me. How did you get the bound of N^3?
Ok, so let us consider my code. The time-consuming part — the one with 4 fors — is actually N^3 because the first and third fors have a total complexity of O(N). The first one is basically choosing the color and the second one (it loops, in worst case till F[i + 1] which is the number of balls of that color) is basically choosing the ball, so the complexity of these 2 fors would be equal to the number of balls (which is N in our case). I know I haven't defined the term of ball or color but it should make sense anyway
Thank you for your explanation. There is the same problem on Codechef which has a very nice detailed editorial and explains the time complexity properly too. :)
Was Div2C inspired by Problem 2 from International Mathematics Olympiad 1981 ? Probably a coincidence but I was reminded of it just after reading the statement. (Also, not good problem for a programming competition, in my opinion — many people saying that they just guessed the solution).
Ah, those were the days... today's IMO Problem 2s are much harder...
I was also surprised by the high number of accepted solutions. I noticed that the expected value of F(n,k) is (n+1)/(k+1) and based on that I found the solution.
Not doing this for fun but need to ask this.....Is it rated ?
Solving problem A be like
(idea from afaji321)
I guess expectation value is n+1/k+1 ( Guess )
Your guess is correct!
Any hints for Div2E/Div1C?
Something wrong with A problem validator because my hack (2 3 ab) was recognized as incorrect test, but it is obviously not true.
same for me :(
Mediocrity
I hacked with the same test and got a successful hacking attempt!
It might be because its mentioned that string is inputed in new line. I hacked with same test , but in new line.
Can someone say why this code didn't give RTE (in pretests)? — 29563087
Because it's undefined behavior, so anything can happen.
a[i] you mean !
Why would I even say
cin >> a[i]will give RTE? -_-It's gives RTE because you used n instead of i that's what I want to say !
Did you even read the first line?
Can someone say why this code didn't give RTE (in pretests)?
[Anyhow that submission isn't mine. It is of an IMO guy, this is his first contest in CF :) ]
aah sorry ^^
// Implementation practice (Have seen the editorial)
He has written this on top, Now I get why its beneficial for IMO participants to get better easily. xD
An array is simply a continuous memory segment, so as long as it doesn't go outside it is fine. For instance, this code will print 1..n.
as the n-th position in the memory segment is int i.
EDIT: I've been trying to reproduce this and doesn't seem to work.
No, I think your code will run into an infinity loop.
even if you set
i = 1,mem[n]will have some garbage value!In my machine it runs into infinity loop! So
iisn't n-th position in the array. It is just undefined I guess.I tried it several times I believe it depends on whereever the compiler decides to allocate the data. In any case the point still stands, a[n] is simply one more position in the memory, so accessing it will not give RTE although it might give unintended behaiviour
Unrated contest?
Why unrated ? :///
IS IT RATED?
div1 C — https://csacademy.com/contest/archive/task/distinct_neighbours/
div1 D — http://codeforces.net/problemset/problem/674/G
div1 c = https://csacademy.com/contest/archive/task/distinct_neighbours/
?? really?
we say two numbers are equal if they multiply to a square. This is an equivalence relation because it satisfies reflexivity, symmetry, and transitivity.
Yes, just find pairs such their multiplication is perfect square, create new array and make these pairs equal.
oh:) i thought 121 is not a right permutation ty:)
It'd make an interesting statistic if we can find the ratio of submission passing system tests vs the ones that passed pretests for each problem.
It will be longest systest ever
Hi.
The problem 840D is really similar to this problem.
The solutions for these problems are also similar:
Code for PATULJCI
Code for 840D
UPD: Also, netman accepted the similarity between these two problems.
The limits of Div 2 B are too strict participants are getting TLE due to I/O issues and there was no mention of using Fast I/O in the problem
Yes, it is rather dissapointing! Thank very much the authors for the TLE on O(n) solution!
KAN please look into the issue
Yes, that is really bad, but firstly, it is your mistake, you should have to handle big input, secondly, system test has started, so, they can't fix this.
There can be a rejudge of TLE verdicts with new time limits
Nikolay KAN is not the coordinator of this contest, ask netman instead.
netman Please respond
I give up.(ignore)
It happens. I think it has happened to everyone at least once. Next time you will use fast I/O. Get over it.
Let's say I get over it, it doesn't change the fact the the problem setter did a shitty job.
Beyond the (very) bad problem statements I don't see why would they do a "shitty" job. I/O problems aren't rare in CF contests, and they can't really do anything against it. They can't test every language for every I/O to see if the intended solution passes.
Screencast
I did that face too
LMAO
I remember in the Div 2 contest I saw 2000+ people passing pretest for C and thought I was doomed, and now only see ~400 attempts... is it my hallucination?
That is the number of submissions that have been ran against the system tests so far.
Thanks. I tried to refresh and indeed saw the number "tried" increasing.
In Div2 problem b many contestants got TLE in pretests and main tests. But same code got ac. http://codeforces.net/contest/841/submission/29560214 http://codeforces.net/contest/841/submission/29560699
Why are systests so slow? Is KAN running judge on his own computer?
Because div2A(which is like a+b) has 110+ tests and was solved by ~3500 people.
There are 32 pages of TLE on Div2 B. This could cause unexpected slowness of systests because it was submitted by much more people than usually submit a problem that can theoretically got TLE.
Nikolay KAN is not the coordinator of this contest, ask netman instead.
can anyone explain ,why my solution is giving tle . solution
ios_base::sync_with_stdio(false);
Change
cin / couttoscanf / printf. Don't usecin / coutif you have some constrains N ≥ 106but constrains N ≤ 10^6
Most probably your browser isn't JS supported.
Yeah, but each of the 106 numbers can have up to 10 digits, which, including spaces, adds up to 11 MB of input.
<iostream>can have give TLE on problems with such large IO even with theios_base::sync_with_stdio(false);crap. To be safe, just use<cstdio>when you see even a couple megabytes of input (or output).Just add fast I/O, i.e. add these two lines in top of main:
But is it fair.Is their no value for the idea which is 100%correct and just because of Input we are getting 0
Well, you are partially correct, but it is Competitive Programming, it is like you are in racing, so you have fasten your belt to not get injured in accident...
Yeah I agree atleast they should add Take care of inputs warning
Because you use streams cin/cout that work for a long time. Just use scanf/printf and you will be happy) (sorry for my English)
Accessing array element has cost of additional operations. Doing this million time is taking some time.
http://codeforces.net/contest/841/submission/29562890 simple cin/cout is passing in this solution.
using a 1996ms solution as an example is not too good of an idea.
My Grandma is faster than the systest :/
I felt they are manually correcting the solutions :)
RIP randomized solutions on D :')
Nevermind, yeah this doesn't work.
Guess the intended was to calculate cnt(value, left, right) in O(1) with something like Mo's and doing close to 500 iterations of random choice
I have a divide&conquer approach with K(N+Q)logN complexity. It works pretty well in practice (<700 ms on pretests and I didn't even try hard to optimize the constant). It works with O(K*N) memory if you can handle the queries offline or with KNlogN memory if you need to do them online
Is your solution deterministic? Cause I remember in exactly the same problem 674G - Choosing Ads, all solutions weren't.
It is deterministic. The first observation is that the answer, if it exists, for an interval is, when dividing this interval in 2 others, among the most frequent K — 1 numbers in each of the 2 subintervals. Now, try to solve all the queries offline by using divide&conquer. Solve (left, right) would solve all the queries with left <= x and y <= right. You fix mid = (left + right) / 2 and recursively call the function. Then you just need to handle in O(right-left)*K the queries that have left<=x<=mid<y<=right. You can do so by precomputing for each i:
1) i <= mid, then you precompute the most frequent K — 1 values on [i, mid]
2) i > mid, then you precompute the most frequent K — 1 value on [mid + 1, i]
Now, using this precompution, you've narrowed down the set of possible answers to one of size O (K). you could make an extra check for each of them in logN (to compute its frequency with some easy lower/upper bounds) to see which of them are the really solutions. Now, for each query, you've made O(K) checks of logN each, and overall, you have KNlogN for precomputing, at each step those values.
The precomputations are easy to make if you traverse the array from mid to left and then from mid + 1 to right and keep a frequency array and those K — 1 most frequent numbers so far
It's unfortunate that many O(n) solutions are failing due to I/O (mine will likely also fail); however, I think that if any solution fails for not recognizing the need for fast I/O, all solutions that don't consider fast I/O should also fail — otherwise, the test cases should be considered weak. Currently, several solutions using cin/cout without toggling off synchronization still pass at around 1900 ms. Most of the solutions that pass return once an odd number is found, which suggests test 49 contains an odd number and that the test cases don't contain something like:
Rather than failing all the accepted solutions that should TLE, the better answer would probably be to re-run all TLEs with a slightly higher time limit.
Example: My solution: http://codeforces.net/contest/841/submission/29560386 (TLE), and other guy solution: http://codeforces.net/contest/841/submission/29562750 (AC). They are almost the same but different verdict :(
you every time Define Variable
mohabd is right. Also, you could
as soon as you see an odd number. This worked for me in 202ms (using
scanf, but I don't think it would have been that close to 2000ms usingcinwhatsoever)Yes it is. I submitted with cin, got TLE on pretest, and with scanf I passed with 200 ms.
Alright then, my mistake
They must respond for this issue
It seems ur code failed. If it did then can u give the link of ur code.
Time limit should be even more strict, to fail such solutions very quickly, not to block the system tests..
Div2.B test#49 is brutally savage
totally agree.
System testing is not finished yet. I bet it will be after 2 hours since the end of the contest.
Looks like checker to verify the solution needs as much time (or more) as a participant to submit...
codeforces servers be like
I think the number of potatos is less than 2 ( or maybe equal ) :))))
Codeforces Div2 Contest for me are like typing contests now a days. Do Easy ones as fast as possible !!! I am never able to solve tough problems :(
...And don't forget to use fast I/O. Still, I hope we can slowly improve and get to Div1...
The fastest system testing EVER
Any idea for Problem Div2 D?
The problemsetters:
1 hour and 30 minutes passed from beginning of systest, still not checked 30th minute...
Luckily number of submissions through time isn't constant, as the test is already at 50%.
So measuring by the submission times isn't too good.
Most users solved A,B,C in 30-40 minutes, and didn't solved anything in rest of time...
Any idea why people are getting TLE in Test Case 49 in Div2B?
For not reading input fast enough.
Why would it matter in 10^6 sized array?
Modulo operations on long integers are very costly. Use them with slow IO and you will definitely get TLE for n=10^6 :)
Oh!! Thanks a lot.. :)
I heard somewhere that around orders of 10^6 and 10^7 the way you operate with input/output also starts to matter.
Thanks.. :)
system testing is like
The system testing seems kinda... frozen.
Systest running in O(N^N) :/
Wake me up when it ends.
I hope you will wake up due to excess sleep
That moment when the systest is harder than the contest itself :/
In Div2 C Does anyone have a solid proof of why matching higher n in array A with lower k in Array B always work? I spent 40 mins trying to prove it, then got bored and submitted!
By the rearrangement inequality,
is maximized when A' is increasing and B is decreasing.
Excuse me, but how did you arrive at that final simplified equivalent of the function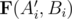 ? Also, how can there be multiple valid answers for such function?!
? Also, how can there be multiple valid answers for such function?!
by application of the Hockey Stick Identity.
What do you mean by multiple valid answers?
Wow! that's very satisfying! Thank you.
I meant how could there be more than one valid permutation?
I mean, obviously if you have A = {4, 5} and B = {2, 2}, then both A' = {5, 4} and A' = {4, 5} are valid. Other than something like that, I'm not sure what you are talking about.
Quick question: Did you actually prove that in contest time or trusted your instinct? :)
I actually proved it, as the Hockey Stick Identity is fairly common in contest math.
Indeed, I remembered the relevant IMO problem (see https://artofproblemsolving.com/wiki/index.php?title=1981_IMO_Problems) to get there.
As an aside, this is the reason that I dislike Div2C: knowing an esoteric bit of mathematics killed the problem.
in Benq explanation how come 2*c(n-2,k-1) = c(n-1,k-1)?. i tried to sum both differently but they yield the same result. however i dont get how they can be proven the same.
can somebody explain?
hiddentesla, you can do the transtiotion from first form used by Benq to second by using Hockey-Stick Identity. Let's denote: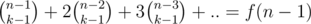
Let's take a look only at numerators:
Now we can apply Hockey-Stick Identity to the first part (the part without (f(n-2))) of last expression, which give us:
Recursively apply same reasoning to f(n-2) and so on. Finally, receive:
Hope this will help.
Multiple answers came due to repetition of elements in given array
Is there any mathematical proof for when A' increasing and B is decreasing then the sum of (A'+1) / B can be maximum?
0) Let's transform (A + 1) to A and (B + 1) to B. Currently A and B are natural numbers.
1) Let's consider the situation for 2 elements: A0/B0 and A1/B1. We will compare A0/B0 + A1/B1 and A1/B0 + A0/B1 assuming that B0 <= B1.
If B0 == B1, it doesn't matter how to order A-s.
Else if B0 < B1 ("A0 = A1" is not interesting in this case), let's consider the inequality: A0/B0 + A1/B1 > A1/B0 + A0/B1, B0 < B1.
We will transform it to the EQUAL one, so the result we will receive can be applied to the initial inequality. We are going to find out the relation between A0 and A1 to satisfy the inequality.
A0/B0 + A1/B1 > A1/B0 + A0/B1
(A0*B1 + A1*B0) / (B0*B1) > (A0*B0 + A1*B1) / (B0*B1)
[B0,B1 are natural, so B0*B1 > 0]
A0*B1 + A1*B0 > A0*B0 + A1*B1
A0 * (B1 — B0) > A1 * (B1 — B0), B0 < B1 === B1 — B0 > 0
A0 > A1
So if A0 >= A1 and B0 <= B1, we will get the maximal sum. We have to sort A-values by descending and B-values by ascending.
2) Let's suppose that this way to sort A- and B- arrays leads us to the maximal sum if these arrays contain k elements for some k: A{0} .. A{k-1}, B{0} .. B{k-1}, and B{i} <= B{i+1} for all the acceptable "i"-s and "i+1"-s -- and they are sorted.
3) If considering (2) to be true it works for k+1 elements, then if (2) is true, it will be true for any arrays of 2 elements and longer.
So we have 2 arrays: A and B of k elements as mentioned above. We are adding new elements A{k} and B{k} and we want to understand in what cases the sum will be maximal.
Let's put A{k}-B{k}-pair between the elements in order to keep our current B-array sorted. Now B is sorted but A is maybe not.
a) A{0} <= A{k} <= A{k-2}, if the array A{0 .. k .. k-2} is unsorted, we can increase the sum for the 1st k elements or keep it the same if we sort these elements only in A-array by descending order, according to our hypothesis in (2). After that, our new element probably can be placed right before the last element in the A-array. If the last element is more than the new one, we can swap them in order to increase or to keep the sum for all the k+1 elements.
b) A{1} <= A{k} <= A{k-1}. Like in (a) the same logic can be applied.
Anyway, we will get our k+1-arrays sorted. Let's prove that the current sum for the k+1 elements is maximal.
Let's imagine that it is not true, so there exists another unsorted order of elements that leads to maximizing sum value. But if these elements are unsorted we can again apply approaches in (a) or (b) to increase the sum, but it contradicts with our last assumption.
So we have proved with the mathematical induction method that the sum will be maximal in the case if A-array will be sorted by descending and B-array by ascending, or vice versa (as you wish :) ).
I do not understand, why does this solution 29564049 get WA in problem div2 A?
I have WA 39 too and same solution. It is because you forgot read '\n' from stdin.
thnx for ur reply, but then why in test case 39? shouldn't it get wa in sample test cases?
No. Because in sample tests (and moreover in system tests up to test #39) to get answer it is enough to read n-1 characters from the second line. So, for example, test like test #39.
check this solution 29558710. i do not understand, does the judge data contain symbol other than [a-z]???
No. In this submission before "%c" goes whitespace, therefore '\n' was ignored.
2 Hours for the Contest and 2 hours for the System test. Add 1 more hour. We will be a testimony of 5 hours regular CF Round.
Why tle in Div2.B my sol
Fast I/O !!
I have never seen such a lot of submissions
and the number of announcements too
This is what happening while testing.
But MS errors aren't unexpected!
Longest 'System Testing' ever!
I am agree with you. When I opened contest web page, testing was on 30%, after 2-3 hours, I opened again and there 70%.
when I wrote this comment, it was 70%, now it's 75%
Ideas for Div2D/1B?
I've thougt about corner cases:
1) If there is vertex with -1, then this vertex is an answer
2) If there are two vertex with 1 and between them all zeros, then this path is an answer
3) Else we have at most one vertex with 1 and rest of them have 0. I assume that answer is cycle of zeros. If there not any, then solution doesn't exists.
Only when there isn't -1 and number of 1 is odd we can't find subset.
Wrong
4 4
1 0 0 0
1 2
2 3
3 4
2 4
Answer is
3
2
3
4
what with 1?
Nothing, we must choose some edges, you can choose cycle of vertex with di = 0. This edge set satisfies condition.
Also you can have three vertex with di = 1 and still get solution — any path 1-0-0-....-0-1 will be solution.
Maybe I didn't understand the problem but in your solution vertex 1 don't have any edges.
In input graph vertex 1 with d1 = 1 connected with vertex 2 with d2 = 0.
Problem is choose subgraph (not neccesary choose all vertex). In test above you can choose cycle 2-3-4-2. Each of vertexes ( in subgraph ) has degree of 2. Since 2 mod 2 = 0 and d2 = d3 = d4 = 0 this cycle is answer.
I have AC.
Checked your solution. We have different understanding of problem. So mine is wrong. I've thought that you need to choose subgraph, not all vertexes and some of edges.
If that's the case, then the first sample should have a positive answer (by taking no edges, thus vertex 1 doesn't belong in the subgraph because it's isolated).
The statement is indeed unclear, but the subgraph is supposed to have all the vertices from the input.
Interesting! Do you have a proof?
I think so. When we have odd number of 1 then sum of degree is odd and this is wrong. When we have number of 1 even then we can match vertices with 1 but we are looking only on dfs tree. When you find partner for some 1 then you can change edges on path between those vertices 0->1 and 1->0.
I have to say that this was very useful for Div 1 C!
I've tried to check the recurrence (1.1) from the given paper on pretest 1, and for some reason it does not work out, even though in my understanding it is supposed to solve the same problem:
While the expected answer is 2. Would appreciate if someone could point out my mistake.
Am I the only one who can predict the outcome of the round only by author's usernames?
I think you forgot Chuck Norris :P
Is it rated?
what did you want ??
What the writers of this round need:
That moment, when you search in accepted submissions for one similar to yours, so you can sleep calmly without doubts.
hi Fedosik.About div2B, n ranged from 1 to 1e6. why a code of O(n) would be TLE by just using cin. because my rank change from 200 to 1k. I hope this will be unrated because of the data of div2B and the statement of div2D.
I used cin and got Accepted.
With 1996 ms you are very lucky
because you return 0 when you find odd number .. you should have TLE but problem test is weak .. if you have test n = 1e6 and all numbers even expect last one your code have TLE
Same for me i got TLE and my code runs in o(n) Some solutions got AC using cin , so what is the problem!!
because you use cin .. you should use fast cin and fast cout or scanf because n is up to 1e6
This could help in the future when you use cin/cout for big I/O.
I think the rating updates will be available on the next year
19 Aug , 2018
Finally my last submission got tested! I hope rating changes will be available by the time I go to sleep(probably not though).
Actually, I hope rating changes will be available by the time I wake up
Did somebody note when systests started? Would be good to have an exact entry as Guiness World Record of the slowest systests ever.
17:30 UTC, according to @contestWatcherBot.
Haha, my post was just for laughs, but thanks :D
when the code fails system testing
NetFlix & you know what... lol xD
It was a nice contest but system testing has taken so long XD
Waiting for too long... -_-, some more time for ratings update :(
It looks like Mike is personally calculating our codes' results. Don't use too much modulos guys, he have to calculate it twice then.
Mike's motto: "Wanna do something perfectly, do it by yourself."
I had no idea how long systesting takes. Since I slept ~4 hours for 3 recent nights I set up alarm for +3 hours and fell to a bed. Now I'm updating the rating and I see you have the 3 place and +20 to rating. Congrats!
Div 2 C. Both solutions are identical, both FPC, both must run in O(n+n log n). Strangely mine gets TLE at 47.
29576388 29572292
Sorry for Pascal.
m:=a[(aa+bb) div 2];— use randomI think this result looks weird... It passed pretest 6, but failed at system test 6.
(Image is guoyu1098's Div1 D submission log) Also, dotorya's Div1 D has similar result.
And We could know that ~16 is pretest(from dotorya's submission), but kmjp locked and system falied at test 10. Why this happened?
Actually, kmjp used rand() in his code, so it makes sense.
But I don't know why my execution time changed between pretest and systest. (My code didn't use random function, except for srand() for debugging)
Maybe the sumission was close to the time limit and aa the server was overloaded by sumissions, it took a little more to judge them
The pretests and actual tests are different.
It is over
After how much time ratings usually get updated?
About one hour ordinary
System test took 5 hours to run... is this some record
First Stage of hell Completed.
Loading Second Stage.. Please Wait :D
stay all night.....QAQ
Why CF-Predictor Rating extension not working ?
Upvoted the main comment so that someone would answer it. Had the same question.Thanks :)
Rating calculation is over I can go to sleep :)
Good contest. I enjoyed the problems. The second problem was quite elegant.
Why my div2 B O(n) solution got tle only because of cin/cout? Problem setters and testers must check this very carefully even for future contests.
I believe it is expected of contestants to know when to use fast input (10^6 numbers takes a lot of time to read using cin)
Yes but I believe it shouldn't get tle only because of input/output that too when it wasn't mentioned even.Also a lot of participants got AC by using cin/cout.
I think the AC solutions with cin did not have it synced with stdio, which makes it faster. Still, whenever the input is larger than 2 x 10^5, I don't think it is a good idea to use cin (even without syncing it with stdio).
I didnt sync it with stdio.Yes I understand that its not a good idea but if it costs TLE then it should have beeen explicitly mentioned in the problem statement to use fast ip/op.
Just checked your solution, you had it synced with stdio (it is synced by default). If you add the following line to the beginning of your code, it should give AC: cin.sync_with_stdio(false);
To avoid this situation just use scanf
Div 2,b problem gives TLE on 7th test case, please help
include<bits/stdc++.h>
using namespace std;
define ll long long
int main() { long n,cnt=0,x;
cin>>n; for(long i=0;i<n;i++){ cin>>x; if(x%2==0) cnt++; } if(cnt==n) cout<<"Second"<<endl; else cout<<"First"<<endl;}
Please do not use 'cin' for such a large input (1e6)
It turns out, valid Scala submissions (29558424) were failing in this round with Runtime Error
java.lang.NoClassDefFoundError: scala/App$class:(Looks like the Standard Scala Library was not included in the classpath for some of the invocations.
Memory limit exceeded on test 74 (out of 79). I guess universe doesn't really want me to be red.
It's challenging you, don't quit :)
Please public the editorial :(
Unless you speak Russian, I hardly doubt you really want to see the editorial.
Where is editorial?
If the system testing was so long suggest when we shall see editorial
Can somebody please help me? I don't know why my solution for Div2.C got TLE.
29576537
Vector's erase linear on the number of elements erased (destructions) plus the number of elements after the last element deleted (moving), so erasing vector's first element may take times if vector's size is large.
For Div2 C, it was like if you observe the input you solve the problem but for me I think the property of A[] that all its elements are bigger or equal to the elements of B[] should be turned to for all i : A[i] >= B[i], this will make the problem a real C-problem i think
Wondering if anyone did any math to solve Div2C/Div1A?
Yeah, me :)
I proved that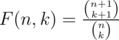 then found solution without looking sample cases :)
then found solution without looking sample cases :)
But, just observation on samples does work :(
It's impressive if you read the problem statement, proved correctness and got it accepted in 15 minutes.
It wasn't 15 minutes :)
Firstly, I read problem C and found value of F(n, k) then I saw many people solved A, so I passed problem A. That's why I solved A in 9 minutes.
Finding value of F(n, k) is really easy with some basic combinatorics + probability and I think proving correctness in 10 minutes is enough for someone who have some math olympiad knowledge.
Did you also use Hockey Stick identity in your proof? I saw an elegant proof here in the comments, using (k+1)-element subsets of the set [0,1,..,n] and throwing the minimum element. What was your proof?
That was my writing during contest, I know how my handwriting is beautiful. Everything I used is Pascal's identity. If something unclear (probably everything :D) please tell me so I can explain.
P.S. I did silly mistake in left bottom (crossed area) so I got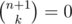 as result, my face was like that there (with dafuq emotion :D) :)
as result, my face was like that there (with dafuq emotion :D) :)
Good! You kinda followed the proof of Hockey-Stick Identity using Pascal's Identity. I came across in the comments on this post a very beautiful solution: take (k+1)-element subsets of the set [0,1,...,n] and remove the minimum element from each subset. You will be left with k-element subsets. The interesting thing is that,
iwill be the minimum of these subsetsitimes which is exactly what we want. So the result is n+1 choose k+1.Did someone solve proble Div2/C with proof?
You can check the proof in this blog: http://blog.csdn.net/oiljt12138/article/details/77413871 ORZ
but explanation is written in chinese, is there english explanation?
Since we know F(n,k)=(n+1)/(k+1), we can assume that A_i and B_i matched reversely. And then we try to swap a reverse pair, we can prove that we can't get a better answer.
I find the test data is not strong enough in Div2 D/ Div1 B[problem:840B]. Some Ac code have a wrong answer with the test: 3 1 1 1 0 1 3 Have a result 0 while the right answer is -1.
It's invalid because it's not connected
Oh I'm sorry for misunderstanding the problem. Then we can assume if there exists d_i=-1 or has even d_i=1, there must be a solution?
exactly.
Hi guys please help me... I wrote a code for Problem D/ِDIV2
this is my code: 29600735
I got WA on test 6 and checker comment is: "wrong output format Unexpected end of file — int32 expected" but the output format is ok!
Where is my mistake??
Now I got WA on test 30 :(
The code: 29602179 Please help me
I'm really confused :'(
MikeMirzayanov, netman: it looks like something fishy was going on with the timing of my submission for D. I have resubmitted my solution from yesterday's contest that got TLE (2.5s) after adding a comment to it (so the resulting program is exactly the same), and it passed all tests in 1.7s.
TLE during contest: http://codeforces.net/contest/840/submission/29570473 OK in practice with 1.5x margin, same code: http://codeforces.net/contest/840/submission/29601182
Could it be that the system was overloaded yesterday and thus was giving a bit more TLEs? Maybe it's too late now, but please consider rejudging yesterday's TLEs and/or investigating the timing instability.
Thanks!
(I realize that my solution initializes random generator from current time, but given that we query the random generator millions of times, the effect of that should average out very well)
I've submitted it 3 more times today, and the timing is consistently under 2s.
Everything written below is specific to Java:
This happened with me too in practice a couple of days ago. I submitted a solution to one of the problems that passed in 1714 ms / 2000 ms.
On reading my code again a couple of days later, I realized that a part of the code was unnecessary, and I deleted it and re-submitted. But, to my shock, this time it got TLE.
I resubmitted instatntly again it and got AC in 1994 MS. I thought of writing a blog, but didn't do it on fear of down-votes.
Is it possible for runtimes to differ by as much a 250+ ms ?
1st submission : Link AC
2nd submission : Link TLE
Interestint. But you can use the ChairmanTree. The "K" is very small.
From what google says, "ChairmanTree" seems to be the same thing as a persistent segment tree. I'm not too sure though, can you elaborate on this data structure?
Please, investigate why with C++11 compiler we had the TLE for the Div2-B. It hasn't happened for C++14. If it is a compiler issue, please remove this compiler from the system. Thanks.
It is not a compiler issue. You just have to use fast I/O: reaf and printf Also, you can add these two lines at the start of your main method: ios::sync_with_stdio(0); cin.tie(0);
Did anyone except me have solved problem E Div 2 using inclusion-exclusion principle ?
I thought that during contest, but its complexity would be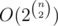 :P
:P
I thought I solved problem C Div 2/A div 1 in O(nlogn) time but I'm still getting TLE Can anyone help me speed it up? (http://codeforces.net/contest/840/submission/29610925)
It looks like your nested for loop is making it O(n2). Also you don't need to check if B[j]>A[i] you are told in the question A[i]>=B[j] for all i,j.
How to do div2E ? any hint ?
If a and b can't be adjacent, and b and c can't be adjacent, then a and c can't be adjacent.
After removing squares from the number, it becomes, for a and b, a must be equal to b to make their product be a perfect square.
sorry,but tutorial pls?
Please provide the editorial!!
Would you please made a contest unrated for me? I am into problem solving more than choosing appropriate method to read from input.
Upvote for you man
Since the editorial is taking a long time to upload can someone explain me DIV2 / problem D concept ? I am unable to devise a solution for this problem? Thanks in advance.
if the number of vertices with d==1 is odd and no vertex with d==-1 exists then it is impossible to find a solution otherwise there is always a solution! try to prove this! then change d of any vertex with d==-1 to 0 or 1 in a way that remained graph have a solution!
now consider one of spanning trees of the graph, it can be obtained by a dfs or similar! there is several ways one way is construct the needed subgraph from leaves of tree! in each step it's obvious an edge between a leaf and its father should be in final subgraph or not (if its d is 1 add upper edge to final subgraph, change the d of its father to 1-d and remove it from tree. otherwise only remove the leaf from tree) continue removing leaves to become the tree empty! 29595499 {sorry for my poor English!}
I guess in first line of your answer... after" no of vertex with d==-1" you missed something? And it is really hard for me to prove the hypothesis.
I edited that to make my mean more obvious! tnx :)
the constructive alg I said can be used as a proof to! :) prove it by induction when u remove a leaf the remained tree has smaller size,is connected and parity of the number of vertices with d==1 is the same as previous tree!
For the following test case ::
Number of vertices with d==1 is 3, and there is no vertex with d==-1. But the answer for this test case is not -1( That is solution exists) And the solution is 0. Correct me if I am wrong? And I really appreciate that you are replying to my silly doubts? I am not that of a coder :P
In any graph summation of verices degree is even... The proof for impossibility in case like these!
What should be the output for the problem DIV2 / problem D for the following test case
Please also explain How you got to that output? Thank you in advance.
Any pair of edges that don't share a vertex will work. For example, 2 1 6
That is, the edges 1-2 and 3-4. Every vertex will have 1 "good" edge incident to it, which is odd.
i have one doubt ... If we remove edge number 1 and 6....So in the remaining graph all the vertex from 1 to 4will now have even degree.. and therefore (degrre%2) == d[¡] condition will be violeted ?? Correct me if i am wrong
I'm not saying to remove 1 and 6; I am saying keep them in and remove every other edge.
Has there been anyone who passed Div 1 D with the Probabilistic Approach?
If I set the limit too high, I get TLE and WA for too low limit. Do you have any suggestions?
Use Mo's algorithm so that when you process a query [l, r], you can get the number of occurences of a number v in [l, r] in O(1) time. My solution in upsolving tried randomly 70 times and passed. The complexity is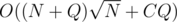 , where C = 70 is the number of times you try for each query.
, where C = 70 is the number of times you try for each query.
Well, this is so unfair :'( , in my current random solution where C_max = 50 (I even change C in relation to k) and the complexity is O(N + 3 * C * Q * log(C)) and I still getting TLE :'( (only WA if I reduce C), how can an O(N * sqrt(N)) algorithm works when N = 3 * 10^5?
It should work comfortably since Nsqrt(N) is like 1.5*10^8 for N≈3*10^5 and the constant factor seems low. The key is that you want the effects of increasing the number of trials to have minimal impact on your complexity.
Does anyone get access to the editorial?