


Hello Everyone!
Japanese Olympiad in Informatics Spring Camp 2018 will be held from Mar. 19 to Mar. 25.
There will be four online mirror contests during the camp.
- day1 : Mar. 20 (00:30 — 05:30 GMT)
- day2 : Mar. 21 (00:30 — 05:30 GMT)
- day3 : Mar. 22 (00:30 — 05:30 GMT)
- day4 : Mar. 23 (00:30 — 05:30 GMT)
The contest duration is 5 hours and there are 3 to 4 problems in each day. Problem statements will be provided both in Japanese and English.
There might be unusual tasks such as output-only tasks, optimization tasks, reactive tasks and communication tasks, just like International Olympiad in Informatics (IOI).
The contest site and registration form will be announced about 30 minutes before the contest.
Details are available in the contest information page.
We welcome all participants. Good luck and have fun!






This is too early for me, will contest be avaliable after it ends?
Yes. We will open the judge server as analysis mode during the contest intervals (06:30 — 23:30 GMT).
In addition to that, we will distribute contest materials, such as problem statements, solution codes, input data and output data, in the web page after the camp.
Is there a reason why Java submissions aren't allowed?
The contest will start in 15 minutes but why isn't the registration open?
So... Delayed 30 minutes. The contest duration will be 1:00 — 6:00 GMT.
When will the registration be open?
It is already running.
How to find rectangle-avoiding shortest distance between two segments?
Is the solution for task construction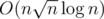 with HLD ? How to solve this task?
with HLD ? How to solve this task?
It's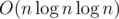 with Link-Cut Tree.
with Link-Cut Tree.
I have an O(nlognlogn) with binary lifting and segment tree
Can you please give more detailed explanation and maybe your implementation?
Can you share your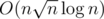 idea?
idea?
After seeing 300iq idea i realized that my approach is wrong :/
I didn't post my idea since I didn't have the opportunity to submit solution (I was at camp during the actual contest so I couldn't code and submit my solution back then). Now that it's on oj.uz and I just passed it there I'll describe my solution. It's a bit sketchy since I didn't write a formal proof.
We'll first read the entire tree and perform HLD on it so that each path is now a union of chains. Then, for each chain, we'll store the values in the chain naively, however we group consecutive equal terms together, so if there are C consecutive occurences of v, instead of storing C copies of v, we just store a pair (C, v).
chains. Then, for each chain, we'll store the values in the chain naively, however we group consecutive equal terms together, so if there are C consecutive occurences of v, instead of storing C copies of v, we just store a pair (C, v).
For each query, we can just naively go through each chain and store the compressed value-frequency pair in a vector and count the number of inversions in the vector using the standard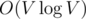 solution, where V is the size of the vector. For each update, we go through the related chains and update the corresponding parts of the chain (for all chains except the last, we'll just clear the entire chain and replace it with (sz, v), where sz is the size of the chain.)
solution, where V is the size of the vector. For each update, we go through the related chains and update the corresponding parts of the chain (for all chains except the last, we'll just clear the entire chain and replace it with (sz, v), where sz is the size of the chain.)
The idea is that the number of pairs you actually consider should be amortized linear or around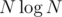 , so the solution works quite fast. I think it's provable by considering some cost function.
, so the solution works quite fast. I think it's provable by considering some cost function.
Here's my submission.
The proof can be done by HLD. Denote light edge as an edge which reduces the subtree size into half, and heavy otherwise. Call the edge “separator” if their each endpoint have different number.
Every query passes the light edge at most lgN times. This is reasonably small, so it’s okay even if they are all separators.
For heavy edges, they are the separator if the previous query was from the parent’s light edge. This means that O(sum of separator heavy edge) = O(sum of light edge). So this is also nlgn. Thus, we have only nlgn separators. I think the worst case can be achieved by playing in binary trees (although I didn’t really tried)
Note that this explains why Link-cut tree operates in O(nlg^2n) operation. (After solving, I found that this is the exact proof that Tarjan & Sleator gave.)
How to solve B?
How to solve C?
Order the points in decreasing order of x and let dp[N][M] be the answer for (N, M). Because of ordering we'll consider only the Nth row at transition. You have the following cases:
1. Put two points with the equal row, there are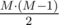 possibilities to choose the columns, you go to state (N - 1, M - 2).
possibilities to choose the columns, you go to state (N - 1, M - 2).
2. Put any direction on any column, there are 4·M possibilities to do this, you go to state (N - 1, M - 1).
3. You don't put anything on this row and go to state (N - 1, M).
4. You choose two points with equal column such that one of the rows is the Nth row, there are M·(N - 1) possibilities, you go to state (N - 2, M - 1).
Clearly it's O(N·M).
I was only able to solve B in Day1, so here it is
Pick any half-line from (0, 0) (better random, to avoid collinear case). Now you should find a cycle that crosses such line odd times. It can be solved by Dijkstra or Floyd-Warshall. Be careful for implementing line segment intersection.
Some cute test cases that helped me so much :
Answer is 62. (Try this for every 4 direction)
Answer is 72.
Can you tell how you discovered this solution and why we make odd intersection count?
My solution was inspired by well-known "point-in-polygon" test. The point lies in polygon iff it intersects the polygon segment odd times. In this problem we want to fix the location of (0, 0) inside the polygon. This means we want to intersect the polygon segment odd times.
How to solve D?
Where can we see and submit problems now?
EDIT: Found it, it did not load for me for whatever reason.
Will today's contest be delayed?
UPD: No. The contest will start in about 10 minutes.
How to solve
Worst Reporter 3?For the first guy, the table of movements is like (-1 , 0) , (D1 — 1 , Dn) , (2*D1 — 1 , 2*D1) ... (k*D1 — 1 , K*D1) ( where (x,y) denotes the position and time respectively) , note that from the second guy we can create the same table using the fact that " k*D1 — 1 + 2 >= D2 + 1 " -> k >= ceil(D1/D2) using the first table again and repeat this we can find that the second table is (-2 , 0) , (D1*ceil(D2/D1) — 2 , D1*ceil(D2/D1)) , ... ( k*D1 * ceil(D2 / D1) — 2 , k*ceil(D2 / D1)). We can do this recusivly and see that the i-th table looks like : (-i , 0) , (f(i) — i , f(i)) , ..., (k*f(i) — i , f(i)) , where f(i) = f(i-1) * ceil(D(i) /f(i-1)) and f(1) is D1 , now we can binary-search for every query the answer using the fact that the position increases with the i , and that we can know the position of the i-th guy in time t using only f(i) , Code
How to solve A from day2 ?
https://en.wikipedia.org/wiki/Eulerian_number
Can you explain the intuition behind this? (how can i solve for 100/100 without OEIS?)
So we just insert n and n - k in eulerian number formula and that's it?
How to get a good score on Road Service?
I got 48 by doing dfs order and then adding an edge from 1 to every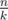 th vertex in the dfs order.
th vertex in the dfs order.
Notice that a star graph has extremely low cost. I dissected the tree into K+1 small trees where the radius of each small tree is small. Then I build a star graph with the centres of the small tree. I scored 89. I think dissecting the tree wisely (maybe dp) can get a higher score because I only used greedy.
By the way, are we allowed to use google? I tried to find the first problem and succeeded, of course. However, when I went to submit it, there were only 2 seconds left which wasn't enough so deep inside I hope we were not supposed to use google and this kinda justifies everything :D
I think not because in the CMS page it says that the rules is the same from the spring camp, but i don't speak japanese and can't read the spring camp rules, so i don't really know ¯_(ツ)_/¯
Then it's all good. sigh
Is there a general method to deal with solving 2D recurrence?
A(i, j) = A(i - 1, j) * something1 + A(i - 1, j - 1) * something2
In other word, is it possible to solve A without access to Google or OEIS?
Yes. This link may help you!
Edit: This doesn't answer the question. You can still use the same idea to find a generating function though. This link is an example.
That is for linear recurrence, not 2D recurrence.
Oh true. I completely misread the question. Oops
Day2A is really pointless (just like other two problems). After I found the recurrence I was sure that it will be in OEIS. So I stopped solving it, as it wasn't worth bothering more.
For solving it with use of the internet we don't even need to find recurrence. The Second sample tells us "I'm not a famous number oeis me" and it is really enough. https://oeis.org/search?q=1310354&language=english&go=Search
I don't know if Japanese students have access to Internet while doing the contest like us. If not, problem A is actually quite hard if you don't know about Eulerian number before.
The problem is not about difficulty but about posing a very well-known problem which have resources in OEIS and Wikipedia
For problems like this one can always look at the generating functions of the rows of A.
The students do not have access to the Internet at all. One student solved it during the contest by finding the property somehow (I was curious, but I didn't understand his explanation). Anyway I don't think it's a really good problem personally, though.
I wonder how many JOIs there are in the JOI logo...
Is is possible that you leave server open for another week so we can upsolve problems (after camp)?
How to solve task 2 "Bitaro" ?
Sqrt decomposition.
If number of friends which won't come are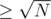 — run the naive O(N) dp.
— run the naive O(N) dp.
Else we notice that in the furthest cities from a city, there is at least one which is not blocked. Well then we can simply store the furthest
cities from a city, there is at least one which is not blocked. Well then we can simply store the furthest  cities for each city.
cities for each city.
The overall complexity will be either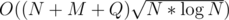 if you carefully choose the comparison constant (we have
if you carefully choose the comparison constant (we have  because we merge the furthest cities with sorting).
because we merge the furthest cities with sorting).
Using merge sort can avoid .
.
for this problem,I think
nth_element()function is a good choice...We precompute the longest distances for each vertex in
longest distances for each vertex in 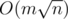 time.
time.
For each query, if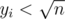 , we can solve it easily, otherwise we can use brute force in O(m) time.
, we can solve it easily, otherwise we can use brute force in O(m) time.
mlgn is a typo, right?
fixed.
Can someone tell the problem?
How to solve Airline Route Map?
My idea
We assume that N <= 511.
Make 12 additional nodes :
0 ~ 9 : connects with every node that have i-th bit on in it's number
10 : connects every non-additional node (degree N)
11 : connects every node beside 10th additional node (degree N + 10)
Also, make an edge that connects i-th additional node to (i+1)th additional node, for 0 ≤ i ≤ 8.
11st node have degree N + 10, which is the highest. (Other node can have at most 8 + N-1 + 2 adjacent node, because they have at most 8 bits on) Thus, Bob can find that node. After that, Bob can easily find 10th node too. After that, Bob can also find the set of 0~9th node, which is tied in the length-9 chain.
0th node's degree is always greater than 9th node for N ≥ 3, so you can tell every node's number in the chain. Now, it's easy to retrieve full information in graph.
Now, if N >= 511, there can be a node that have at most 9 bits on. However, we can always relabel such node to another number with at most 8 bits on. Because there are only 11 such numbers with 9 bits on, in range 0 ~ 1023.
I now got AC, and fixed the problem which caused RE
Thanks :)
A perhaps unexpected solution?
I solved with only 1 extra vertex ...
For all given edges make sure
A_i < B_iand swap if not. Send all edges to Bob. Add extra vertexN. If edge(v, v+1)does not exist send it and also send(v, N). Also send(N - 1, N)On Bob's side, run topological sort to recover the permutation that shuffled the vertices. The order is unique due to extra edges sent. If
(v, N)is an edge than(v, v+1)was an extra edge so we don't include these in output.How to solve day3 C?
Problem "airline_route_map" has some solutions with 12 more vertices, when you can only transfer an UNDIRECTED graph (And I did in this way).
But actually, the problem doesn't shuffle the direction of your edges, so it is easier to solve it by transferring a "DIRECTED graph". And it needs only 11 more vertices.
UPD: according to azneyes 's solution above, only 1 more vertex is needed by transferring a "DIRECTED graph"
I have a long and complicated O(n4) solution for "Security Gate". It got 73 after the contest. Maybe we can squize it into TL, about 9s for the maximum test case. Code here
How to solve this problem in O(n3)?
Lol if you don't know, how can we?
Is "Candy" just greedy maintaining a set of components (i , i + 2 , ... , i + 2*k) ?
How to solve A from day 4 ?
I think it is almost the same with APIO 2007 Backup.
How to solve Day4 C?
When will the official solutions be published?
Is the judging server down?
Will the tests be available after the contest?
Which four are selected for the Japanese ioi team ?
Japan 1 Team: WA_TLE [1st], 193s [2nd], Kmcode [3rd], Hoget157 [4th]
Japan 2 Team: E869120 [5th], square1001 [6th], Pulmn [7th], hirakich1048576 [8th]
Japan is the host country of IOI 2018, so Japan can elect 2 teams. One is official, and the other one is unofficial.
Congratz, can we find the full scoreboard somewhere?
When the problems will be uploaded at ojuz?
Right after https://www.ioi-jp.org/camp/2018/2018-sp-tasks/index.html becomes available?
You can submit “batch” problems here: https://oj.uz/problems/source/312
libraryandairline_route_mapright now.road_serviceor not (probably we would)libraryis ready too: https://oj.uz/problem/view/JOI18_libraryWe implemented our version of grader and interactor because it seemed the given grader was too easy to exploit (for example, it seemed possible to rewind the standard input) If you find any bugs while evaluating your submission, please report us.
airline_route_mapis partly ready now: https://oj.uz/problem/view/JOI18_airlineWe checked that the grader/interactor works correctly on the unexpected solution and two independent full score solutions. However, the model solution gives WA [12] or WA [14]. I tried to investigate what's going on, but we can't find any evidence that our grader is wrong. If you have your accepted/partly accepted solution, we would be really appreciated if you submit your code and check if the score is consistent. Thanks in advance :)
there are only 17 kinds of WA but my code is getting wa[120] instead.Can you check once?
https://oj.uz/submission/236329
Can someone please tell me how to solve day 4 interactive task Library? I find the problem very interesting but I can't solve it.
I solved it in the following way: you want to find all the pairs of adjacent values (there are N-1 of them). When querying a set {s1, s2, ..., sN} out of which you already know some relations of adjacency, you can say whether there is some extra relation of adjacency between them. So what you can do is to find the pairs of adjacent values in increasing order of the maximum of the pair, in the following way. First, find the smallest i so that {1, 2, .., i} has at least an adjacency relation among them. By the minimality of i, you know i is part of that adjacency relation. Then you can binary search the greatest j so that {j, j+1, .., i} has at least one adjacency relation and then, from the maximality of j, you get that j and i are adjacent. So you have 2 binary searches for determining each adjacency relationship, which leads to an overall of O(NlogN) operations, precisely, 2NlogN.
Thank you very much.
Here's my solution :
Suppose we query a set S and its complement S' (with respect to some contiguous segment [l, r]). Then, if one of the answers is bigger, we know that the first and last element of the segment [l, r] is in the set with the larger answer. Otherwise, the first and last element of the segment are in different sets.
For each i, let Si denote the set of valid values with i-th bit equal to 1. Then, query Si and Si' for each i. Thus, if we let x, y denote the value of the leftmost and rightmost element in the current interval respectively, we can find in
in 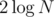 queries. Let
queries. Let 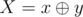 .
.
Let V be the set of valid values such that if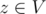 ,
, 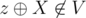 . With a binary search, we can use another
. With a binary search, we can use another 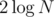 queries to find the value of one end of the interval from V. Finally, we get the values of x and y, but don't know which is which. Just query one of them with the element before the interval to determine this.
queries to find the value of one end of the interval from V. Finally, we get the values of x and y, but don't know which is which. Just query one of them with the element before the interval to determine this.
We used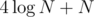 queries to determine the positions of 2 elements, so this works in the limits (in fact the bound is not tight since when the interval is smaller, the binary search takes less queries).
queries to determine the positions of 2 elements, so this works in the limits (in fact the bound is not tight since when the interval is smaller, the binary search takes less queries).
See my code for more information.
Thank you very much.
zscoder , radoslav11
after looking ur ideas and thought process , sometimes i think that you both being red coder developed so high and intutitive ideas to solve complex problems ..
it symbolizes that ur level is very high .. but main question is , if your level is that much then what would be the level and mind powers of tourist and legend Petr
hmm .. out of my reach even to think that
kya vijju bhai sahi kahe na vijju123
What is the intended solution of Day2A?
i know it's late now but can anyone tell me how to solve Day 4 problem 2 Mergers ? Here is the link
Observe that if the tree is separable, there exists atleast one edge such that there is no state which appears in both subtrees resulting from the deletion of that edge. Let's call all these edges "bad".
For all edges $$$(u, v)$$$ that are not bad, merge $$$u$$$ and $$$v$$$ into one node. You have a resulting tree now such that all edges are bad. You can perform operations of the form: take any two nodes $$$u$$$ and $$$v$$$, colour all edges on the path from $$$u$$$ to $$$v$$$. Using minimum number of these operations, we need to colour all the edges of this new tree.
It is easy to see that each leaf node of this new tree will be included in atleast one operation in order to colour its parent edge. Hence, the minimum number of operations needed is $$$\lceil\frac{leaf}{2}\rceil$$$, where $$$leaf$$$ is the number of leaves in the condensed tree.