


Topcoder SRM 736 is scheduled to start at 15:00 UTC, August 15, 2018. Note that as per the new Topcoder Open Algorithm rules (see associated discussion on CF) this round counts towards 2019 Topcoder Open Online Stage 1.
The tasks were prepared by me. I'd like to thank misof and paulinia for comments and testing.
You will be able to register for the SRM in the Arena or Applet 4 hours prior to the start of the match. Registration closes 5 minutes before the match begins, so make sure that you are all ready to go.
Refer to this guide to set up your environment for competing.
Good luck, have fun, positive rating!
UPD: Congratulation to the winners:
UPD2: Editorial







I have a question. Is the restriction of participation changes? There are some country that cannot participate in Topcoder Open although they can participate in regular SRMs, and obviously there are age restriction. Will something change about them?
Nothing has changed in this regard. Everyone can still take part in SRMs. Formally, they are separate rounds and the TCO is just another contest that is looking at their results.
500 is like quick maffs, expected something interesting from topcoder.
This is the way TopCoder used to work and much better than implementation-oriented problems.
I mean if this problem would be on my math lessons it will be like the easiest problem, so I thought if it math then it should harder than this.
The number of people who solved it corresponds quite well to what we want to see at the medium difficulty level. Maybe you are just too good at this type of problems :)
Or too bad at judging problem difficulty :)
If the problem had a catch that made it irreducible to "evaluate these formulas", sure. Like this, it's too easy. I found the iteration-based solution (while graph is valid and has > K vertices: remove 1 vertex, K-1 edges, if you got an invalid graph then the answer is ALL) almost immediately, told myself it can't be that easy and spent some time proving it, then converted it into an equivalent ternary search-based solution.
I feel like I missed the main point, wasted a lot of time being cautious and still solved it. Non-achievement complete, so to speak.
Hard is straightforward to use FFT. But I made a mistake in parsing polygon :(
Well, at first I tried to do something in sympy because it's obvious that there is a closed formula
Oh, would you mind sharing the qwe.py file ?
I don't know what is sympy, how it works and how you used it to this problem (I suppose you got AC hardcoding this formula after adding modulos?). Can you briefly explain it?
I haven't got ac
You can read how to use sympy here. Very shortly, it works with variables like with variables, simplifies things, factorizes things, expands brackets et cetera.
I tried to do the following:
divide all 4n vertices into 4 groups as if we drew vertical and horizontal symmetry axis, enumerate vertices in each group from 1 to n, say, ccw.
our answer is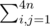
(number of possible polygons) * (area of the whole polygon)minus(area of a subpolygon with vertices p[i], p[i + 1], ..., p[j]) * (count of polygons with edge i-j).first, consider the case when these vertices are in the same group, the first of these multipliers is a sum of some polynomials which is foldable, the second is simply a power of 2 minus one, all this thing is foldable, as the screenshot approves.
two other cases weren't considered by me since I realized that I didn't have enough time
It's just straightforward as it is, without any fancy stuff like FFT :P.
Isn't the trick used in the hard problem a well-known trick in the rolling hash?
Yeah, that's how I did it, no need to use FFT
Well, that is the trick that many contestants used. I must admit that I was not aware of such solution.
Some link to the trick you are mentioning?
1234 = 123 * 10 + 4 is basically everything you need to know here. or maybe 72345 = (23456 - 6) / 10 + 7·104. You want to evaluate such cyclical sums but in binarish system with digits x[1], ..., x[n]
I don't know if it's much of a trick, but I used the expression for area of a polygon as the sum of signed areas of triangles
as the sum of signed areas of triangles 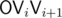 for i = 1..K (with cyclic indices) and an arbitrary origin point
for i = 1..K (with cyclic indices) and an arbitrary origin point  — point (0, 0) in my case. For the sum of areas of all subpolygons, we know that
— point (0, 0) in my case. For the sum of areas of all subpolygons, we know that 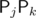 is an edge of 2j - 1 + 4N - k subpolygons if k > j or of 2j - k - 1 subpolygons if j < k, because we have to omit all points from
is an edge of 2j - 1 + 4N - k subpolygons if k > j or of 2j - k - 1 subpolygons if j < k, because we have to omit all points from 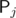 to
to 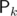 and can include all other points in any such subpolygon.
and can include all other points in any such subpolygon.
We can write an area of a triangle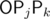 in the form xjyk - xkyj, each of these 2 terms can be summed up separately for j < k and for j > k — there are 4 cases in total, I won't list out the exact formulae, but it can be simplified like
in the form xjyk - xkyj, each of these 2 terms can be summed up separately for j < k and for j > k — there are 4 cases in total, I won't list out the exact formulae, but it can be simplified like 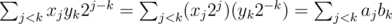 , and this can be computed easily by adding up the sum
, and this can be computed easily by adding up the sum 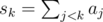 and adding bksk to the final answer. This works in linear time for an arbitrary polygon.
and adding bksk to the final answer. This works in linear time for an arbitrary polygon.
You can consider it in a much simpler way.
There is a string y1, y2, ..., yn, y1, y2, ..., yn, You want to compute something like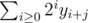 . You can view it as the hash value of substring yj, yj + 1, ... in the base 2.
. You can view it as the hash value of substring yj, yj + 1, ... in the base 2.
Then you can solve it if you know how to use the string hash technique.
That's not simpler, you just omitted several "why?" and "how?" steps. There's no way reduction of geometry to hashing is simpler than writing down the basic formula and doing some arithmetic on it.
consider=/=reduce geometry to hashingsimpler[for understanding because of dealing with familiar concepts instead of writing stuff down]If you want to focus on the word "consider", I'll just point out that one can consider basically anything. You can consider red-black tree balancing a trivial algorithm. You can also consider me the best competitive programmer in the world. So what?
One thing I notice quite a lot is that when I explain concepts I
considerfamiliar in such asimplerway, people who haven't solved the problem (or solved it in a completely different way) don't follow... it turns out I often see these things as simple because I've put a lot more thought into them than what I describe afterwards. You can notice how a lot of scientific articles start with an "introduction" section that explains concepts which people for whom the rest of the article would be useful really should know — the same principle applies.I read "so basically we need to count something in this form", here I think for a second and realize that yes, something in this form, "which is actually a binary hash", and here I understand the point of view of the guy these words are written by. I know how your "don't-follow" model works, but in my opinion this isn't the case. I read your comment with some calculations and jqdai0815's comment and his one was simpler to understand for me, because I didn't need to dive into calculations and try to understand the logic behind them (even if you've described it). I've just read "hash" after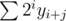 and that's enough.
and that's enough.
Do you mean abstract? It's not about concepts, it's more like a brief overview. Concepts are more about the "keywords" section.
No, I don't mean an abstract, I mean "section 1, introduction".
I think I'll be able to demonstrate my point if you explain in detail what's the sequence y..., how to get from sum of areas of subpolygons to it and what's the index j in the sum. I'll ask further questions in that if necessary.
That's the point, no need to explain what the sequence y is and other details. We're not talking about a complete description of some technique, and even if we were, how we apply it here doesn't have anything common with the technique itself. The question was what the technique is, not "please write an editorial using your solution here"
My first comment there wasn't "this is the trick", it was "idk about tricks, I solved it like this".
Someone asks you to explain something because it's not clear and you reply "no need"? What?
Don't see this.
I didn't say a lot about your comment
Well, I feel that I wrote here the same things about 3 times, so I don't want to take part in this discussion anymore. I don't mind if you miss my point and remain like "that way with using common concepts instead of writing down calculations with a detailed explanation of how we came to them is not simpler to understand", I still don't share your opinion. And please don't ask me to describe someone else's comment in details just because. It has nothing with why that simpler-to-understand comment is here.
I really can't see how someone can arrive at hashing a string as anything but a side note in my solution. Yes, when I look at my solution, I can see that there's a similarity, but jumping to the hashing idea without the same arithmetic I did? How?
You don't see that a solution that's clear to you might not be clear to someone else? Or you don't see not understanding something as the natural reason for asking you to explain it? No, your knowledge or opinions are not self-evident and you can't dismiss everything by acting as if they are. (Yes, you are acting like that.)
That sounds like a jab at my first comment.
No, it has everything to do with that. If it's easier for you to keep arguing (and go on a massive derail) why you shouldn't explain a solution in detail than to just do that, it's not simple. But ok, I can see that you're putting a lot of effort into talking about everything except the possible solution(s), so I won't waste my time.
Note: Graphs with introduced property of locally k-denseness is exactly complement of graphs widely known as (k-1)-degenerated
I see the following code in the editorial.
how to use Field, I google it, but cannot find anything
I wrote it myself. It was quite simple and I find it very convenient: link
Thanks for writing majk! I enjoyed the problems, and I liked the difficulty distribution. The solve percentages in Div 1 this time were roughly 80% / 30% / 10%, which is much more reasonable than previous rounds.
I will say that N <= 500 on the 250 seemed unnecessarily high for the desired complexity of N3. Either N <= 300 or N <= 400 would have been better IMO. I saw a few N3 solutions that timed out, as well as others who went out of their way to implement the N2 because they expected N3 to be too slow. My guess is it was set this high in order to stop N4 solutions from passing even with good constant factor (e.g., N choose 4). But 400 choose 4 is still 1.05 billion, which should be plenty; plus I don't think it's a huge issue if someone manages to spend a lot of time getting a heavily-optimized N4 to pass, as they won't get a great score anyway.
Thanks!
Yes, I was also surprised to see so many people seeking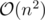 time solutions. There are
time solutions. There are 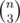 rotations, which is just over 20 million. That sounds doable, even if there are bunch of modular divisions. On the other hand, not even too optimised
rotations, which is just over 20 million. That sounds doable, even if there are bunch of modular divisions. On the other hand, not even too optimised 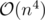 passes the TL with n = 350.
passes the TL with n = 350.
Could you share the code for the O(n4) solution you had in mind? I'm surprised to hear that it can run so fast.
This runs 1.66 seconds for n = 350. Even without that optimisation by precomputing S[i] - '0' it takes just 2.02 seconds. Also note that the modulus in the main loop is not needed as quick maffs show this can not overflow.
On the other hand, I've finished all three problems in under 45 minutes, and I wasn't the first one to do it. So for strong competitors coding phase ends somewhere in the middle of the contest, and then I should return to challenge phase after half an hour. It is not very convenient. Maybe with new arena (some day) TopCoder will have more than 3 problems in one round...
I agree that doesn't sound ideal.
However, the other end of the spectrum is that (almost) no participants solve the hard task. Not only this makes the preparation time invested seem like a waste, but also the contest is now being decided on two (2) tasks.
I think that the current backend can already support a number of problems that is other than 3.
For the time being we'll stick with the old format, but we are looking into ways to update the contest format, and adding a fourth problem to some matches is one possibility.
I am unable login Applet.It is giving me error : "A Connection to the server Could not be established".
Can someone help me please