


I would like to invite you to participate in the rated Codeforces Round 519 by Botan Investments. Date and time of the round: Oct/28/2018 18:35 (Moscow time).
This is a combined round having 7 problems and lasting 2 hours, and it will be rated.
Tasks for you were prepared by Anadi, Grzmot, isaf27 and Rzepa. Also thanks for:
KAN and cdkrot for help in preparing the problems; --Pavel--, Nerevar, map, GR1n, rutsh, AlexFetisov and winger for testing the round; MikeMirzayanov for Codeforces and Polygon platforms.
The round is supported by Botan Investments.
Prizes! Top 50 participants and 20 random participants with rank from 51 to 500 will receive personalized hoodie with CF handle.
Scoring distribution will be announced later. I wish you a high rating and looking forward to see you at the competition!
UPD: I'll be on the community Discord server shortly after the contest to discuss the problems.
UPD: Scoring: 500 1000 1500 2000 2250 2750 3500
UPD: Editorial
The round is over, congratulations to the winners!






Clashes with El Clasico:(
Why do all residents of Kazakhstan like La Liga?
El Clasico clashes with CF #519, not other way around :(
Leo messi is injured, so he has chance to get a hoodie :))
Messi it is your chance.
we can see Messi and ronaldo both getting hoodies ! :D Good luck for all !
Even in CP Messi is better than Ronaldo.
Hmm, I guess you meant only in CP!
Ronaldo plays in Juventus...
Leo had brought his laptop to the stadium! :))
El clasico has started
Wow, top 500 will have the opportunity to receive personalized hoodie with CF handle. Hope to receive it. Good luck.
Mr Anadi what will you do during contest? watching your favorite team match or answer participants questions ???!
FCB stands for something else. ;)
I am curious. For what my nick stands?
We have just talked about it yesterday, don't you remember? I won't announce it publicly cuz I'm a well-behaved person, but others can still guess :p
I always thought it is FC Barcelona :/.
It can be FC Bayern :D
You know I don't like to guess.
Just tell me which one is it?? :|
friends of canadian broadcasting
First one, as I wrote above. But kostka has some ugly thoughts about it.
Fuck club barcelona?
"Prizes! Top 50 participants and 20 random participants with rank from 51 to 500 will receive personalized hoodie with CF handle." -- That's awesome, I wish to get under 500.
Ah! But i still struggle with Div 2 C :(
0.044 is not bad percent :P good luck wish you the best
actualy 20 / 450 = 4.4%
Er, if this contest is Mathforces I wish you good luck.
Wish a hoodie be with you (and me) :D
why can't I register for the contest? it says I must have a rating between 9 and 9,999
UPD: it's fixed now !!
I'm glad to invite you to take part in Codeforces Round 519. Actually it will be two separate rounds "Codeforces Round #519 (Div. 1 Only)" and "Codeforces Round #519 (Div. 2 Only)". The division problemsets will share many problems, but not all of them will be the same. So, Div. 1 users should register on "Codeforces Round #519 (Div. 1 Only)" while Div. 2 users should register on "Codeforces Round #519 (Div. 2 Only)".
This is what is written in the invitation mail I received.
Email is wrong a bit, this is going to be a combined round.
Awesome idea for giving hoodie to random guys, chance for non-red guys get a hoodie.
Could we get a picture of what the hoodies look like (for extra motivation)?
I like these random gifts, as usually all of the prizes only go to the same top users.
unfortunately , The contest will be at the same time as the Clasico match .
If a red said this would it still be -22 contribution dont be rankist!
What do the hoodies look like?
Congrats Michael!
Anadi, are you Indian?
He´s polish
It's a great pity that I cannot join in the match because I have to get up early tmorrow.
Look at my registration date. Do you see it too?
Good Luck on contest!
Is there any way to buy these hoodies ?
I don't understand why make it today and in same time with big football game that many people want to watch ?
It is not a round with onsite contest in same time, it is a normal round that can be delayed or shifted one day, there are many people here includes me that want to watch the game and take part in the contest why we can't do both ?
I think it is not late to delay it to tomorrow or just today after the game
try a try, ac is ok. Fighting!
I have never been so confused. Can't decide whether to give contest or watch El Classico.
The random winners will be determined with these two scripts:
Where seed is the number of points of the winner of the next contest, length is 450 (500 - 50) and nwinners is 20.
What would happen if some concestants share the place and it would be choosen by generator?
they are tied by the time of the last accepted as i know
This does not make sense in cf :) Only in acm :)
i remember this was used previous times when there were random prizes
Then I have no chance :) One person submitted before, one after :D
If I understood it correctly, you do have chance. I think each person is untied by the time of the last submission, so every one gets a different ranking.
Why was seed not taken as max points by winner in this contest? Any reason?
Probably more for historical traditions. Maybe it won't be true for the new random's :)
but is it determined?
Is it normal, that randgen.cpp can give number less than 20? For example, with seed 1234, it give 17.
There is invalid syntax in get_ranklist.py in line 59. My python don't now
—There will be 3 parallel contests, which's score will be the seed?
The onsite round will be used
Please shift the round by 1.5 hrs. El classico comes only twice every year. Please I beg you! cdkrot Anadi
Expect problem statements to be short in size. Wishing everyone high ratings. :)
I'll hack you down!
I will be more than happy if you hack me down, at least I will have a chance to recorrect rather then failing on sys test. :)
But what if he performs the hack at 1:59 :)
Even if he did not, it would not pass sys test. No harm in him hacking my code :D
glad to meet ya at the dark side
First time participating in a contest. Hope to solve atleast one
Score distribution?
which one is more important elclasico or contest? ;)
football is for monkeys :D
Lol, dotorya_.
dotorya is the last person you should've done this with though.
To those football fans competing in this round, I am not saying that you are making a wrong decision, but unfortunately it seems like you have just missed an epic El Clasico match :'(
But well, I am probably missing my chance for hoodie as well, so yeah.
Barca 5 — 1 Real :))
>those names in A
Also in F. It is pure gold indeed.
How to solve F?
Maybe this strategy will help: https://cs.stackexchange.com/questions/10249/finding-the-size-of-the-smallest-subset-with-gcd-1
it can be observed if the answer exists, then it's no more than 7. For each possible answer, check if it's valid by Mobius inversion.
Why is the answer guaranteed to be no more than 7?
Actually, it should be no more than 6, since 2 * 3 * 5 * 7 * 11 * 13 * 17 > 300000, and if the gcd = 1 can be reached, one should at least be able to remove at least one prime divisor for each move(i.e, add another element).
That makes sense. Thank you!
I have one more question, you said, "For each possible answer, check if it's valid by Mobius inversion." There are N^6 possible answers so how do we check them?
Say if you want to check if it's possible to choose a subset of size k such that their gcd equals to 1. Let f(x) denote the number of possible choices such that the gcd of the subset equals to x, and g(x) denote the number of possible choices such that the gcd of the subset is a divisor of x, so that one can apply Mobius inversion on it. The time complexity is O(6 × 300000). All precomputations can be done in linear time.
Could you please provide the explicit formulas? What I've extracted from your code is that g(x) stands for the number of choices such that gcd is divisible by x (but is not a divisor of x).
Let f(x) denote the number of possible choices such that the gcd of the subset equals to x, and g(x) denote the number of possible choices such that the gcd of the subset is a divisor of x, then Mobius inversion states that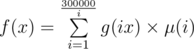 , and the answer lies in f(1). So you have to compute to g(x), which only requires one to for each ai, add all its divisors by one.
, and the answer lies in f(1). So you have to compute to g(x), which only requires one to for each ai, add all its divisors by one.
Ok, thank you.
Your algo is very fast , wow!!!
45032590
Actually it is 7. Take 2 * 3 * 5 * 7 * 11 * 13 * 17 and delete each number once. You will have 7 numbers and each must be choosen.
Oh. That's correct. My bad.
Actually, the answer can be 7, since 3 * 5 * 7 * 11 * 13 * 17 < 300 000.
Note that you have to also count the initial integer. 1 (initial) + 6 (removing divisors) = 7.
Can you give us a actual test case?
Thanks!
I built a graph where each vertex is a product of distinct primes and there's an edge from a product to a subset-product whenever there is an input number coprime to the subset-product. How many input numbers are there coprime to x? That can be computed using inclusion-exclusion (you need to compute how many are divisible by each number first).
first the do the basic checks and also remove duplicate primes in each number. For each value in 1 to 300000 count number of numbers which have gcd!=1 with that value(lets call gg[val])(using mobius function this is easy). Now we can construct graph with edges between two numbers(x and y) if x divides y/x and gg[x]!=n.
Answer is shortest distance to a vertex from 1 in this graph +1.
Use dpx — amount of numbers to get 1 if you took already some numbers with gcd = x.
To calculate dpx, we need to check for each divisor dj of x: is there a number ai such that gcd(x, ai) = dj. To do this, we calculate another DP dqx, a (a is divisor of x)— amount of ai in the array such that gcd(x, ai) = a. Calculation of this dp looks like this (suppose wx is amount of numbers in ai which have x as a divisor):
It's easy to see that recalculation of all the dq's take no more than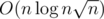 (faster in practice)
(faster in practice)
Of course, we will keep only one dimension of dpx, a for current x to fit into memory limit.
And, in the end, we solve the original dpx in the following way: dpx = min(dpy) + 1, where exists ai such that gcd(x, ai) = y.
how to solve c ?
Have a variable cur = array[0]. Loop from 1 to n-1. if(cur == a and array[k] = b and array[k+1] == a), then you should swap at k and set cur to b. If cur == b and array[k] == a and array[k+1] == b, then you should swap at k and set cur to a. If you finish and cur == b, then you should swap at n-1.
You can always rearrange the string to make every 'a' stands before all 'b's.
To do this, we will traverse through the string and find substrings (consisting of consecutive characters) that all characters of it are 'a'. Let's denote the substring S[L, R].
It's easy to say we will reverse prefix L - 1 (if it exists) and prefix R.
Total complexity is O(N) with two-pointers. Naive solution in O(N2) is still acceptable with the given constraints.
There is also DP solution: for every prefix of length i store lexicographically minimal and maximal string obtainable by doing first i rotations.
With regexes. To substitute all a+ or b+ (but not b+ (longest) at the ending of the string) by '0' * length_of_a_match + '1' — Perl code: 45056981. Or, Algo_Rhythm's variant with regexes: 45058519
Am I the only one who didn't read
The string s consists only of characters 'a' and 'b'.in problem C, and solved it for general strings?I've noticed it just now by reading this comment. I was blown away when I saw so many people solved C so fast. Damn!
I was just astonished by so many submissions, until I went into hacking room and saw a 3 lines code :(
I did the same :( Btw, how can it be solved for general strings?
Our operations are equivalent to appending each character in order to either the beginning or end of the string. In the lexicographically smallest string, we want to put all a's into the beginning of the string. This means that after the first 'a', we put everything but a's into the end. Before the first 'a', we want to put nothing but b's to the beginning of the string, and so on.
So Greedy still works, you just check if the current letter is smaller than or equal to all previous letters. If it is, add it to the beginning, otherwise add it to the end.
Could you describe more in terms of reverting or not reverting a prefix. For example for string
bazabhow would you iterate over this string and make greedy decisions?If we iterate from last to first char in the string, once we find
awe want to reverse the prefixbazaand it also means that we want to maximize prefixbaz. And to maximize prefixbazwe want to reverse it and minimize prefixba, so we want to reversebatoo.Would it work if we store
char[] maxOnPrefixandchar[] minOnPrefixto make decisions greedy?During contest I solved this problem for generic string with dp.
Our operations are equivalent to appending each character in order to either the beginning or end of the string.Consider "bazab", iterate over each character.
"b"
append a in begining "ab"
append z in end "abz"
append a in begining "aabz"
append b in end "aabzb"
Ok, but how to produce the answer out of this? How to know what prefixes we want to reverse?
Bruh me too xD
How to do E? I don't see how you can do it faster than O(n^2)
You may compare the difference of x[i] and y[i], say d[i] = y[i] - x[i] for every competitor For two competitors i and j, if d[i] < = d[j] then i should solve the second one.
Binary search on how many competitors have higher d[] then himself and the answer can be calculated using prefix sum.
don't forget to subtract scores of m pairs after that.
Does somebody know pretest 3 for C or pretest 7 for D?
Pretest 3 for C can be baaaa.
That's what sheep said.
Nice
Why everyone solved D....So,how to solve it?
Split the first permutation into largest substrings which appear in all other
m - 1permutations:1|2 3|4
2 3|4|1
4|1|2 3
1|2 3|4
If the length of the i'th substring is k[i], then the answer is:
Thank you!
Just finished my code 2 minutes after the contest. I used rolling hash and binary search. For each number i from 1 to n,find the longest subset obtainable starting with the value i. Complexity O(NMlogN). CMIIW.
That sounds too complicated :)
We just need to test 2 consecutive digits in a permutation
p[i]andp[i + 1]in order to test whether we can extend the current segment.won't this actually take O(N^2.M) tho ?
No. We are touching each element of array at most 2 times.
My personal ideas: The numbers from 1 to N can be seen as a directed graph, and I'll count the appearance of the pair (i, j), with i and j are the values of 2 consecutive elements on one permutation.
If any pair appears exactly m times, then there will be an edge starting from u to v.
With this given, it's certain that the graph will be a DAG, and there is no vertex having more than one edges pointing at it.
So we can do a simple DFS from all sources to find the answer. With each source, if the total number of traversable vertices from it is x, add x * (x + 1) / 2 to the answer.
UPD: I didn't take the TL seriously and my solution got TLE. Damn!
Total complexity is O(NM * log(NM) + N).
UPD2: Accepted solution (904ms): 45022094
UPD3: Improved solution (171ms) from suggestion of mouse_wireless — complexity reduced to O(NM): 45031805
Nice solution!Amazing!
You can build the DAG from the first permutation. On each of the next ones, if you come across an edge that doesn't exist in the initial DAG, just delete it. This can be done in O(1), since each node can have at most one incoming and one outgoing edge.
In the end, count the connected components in the resulting DAG and for each component add x * (x + 1) / 2 to the result (where x is the size of the component).
By doing this, you eliminate the log factor.
Right, I overkilled the solution. Good observation, man :D
Oh well, I guess my solution was kinda different...
Create the array ans[] where ans[x] is the amount of ways which start with number x in all permutations. Also, make the array pos[][] where pos[x][k] is the index where number k appears in permutation x. In particular, for num[m][n] (where num[x][y] is the yth number in permutation x), ans[num[m][n]] = 1. Now for any i with n-1 >= i >= 1 (a for loop where i decreases from n-1 to 1), take next = num[m][i+1]. Then, if for some j (1 <= j < m)
num[j][pos[j][num[m][i]]+1] != next, we will have ans[num[m][i]] = 1. Otherwise, ans[num[m][i]] = ans[next]+1. Indeed, we know the value of ans[next], since we loop through i in decreasing order.Therefore, the answer for the problem is the sum of ans[x] for all x with 1 <= x <= n.
How to solve E? My idea was to do some sort of complementary counting but not sure how to get the sum for every team for person i in a fast way. Maybe there was some other observation?
Also how did everyone solve D. I used hashing+binary search, and I thought it was weird so maybe someone has a better solution.
min(xi + yj, xj + yi) = xi + yj iff xi - yi ≤ xj - yj.
For E, sort by x-y values since if x+b < y+a, then x-y < a-b. Then use prefix sums to calulate the sum.
For D, I used hashing too, hope it doesn't give TLE in systests.
min(x[i] + y[j], x[j] + y[i]) = min(y[j] — x[j], y[i] — x[i]) + x[i] + x[j]
a[i] = y[i] — x[i] a[j] = y[j] — x[j]
min(x[i] + y[j], x[j] + y[i]) = min(a[i], a[j]) + x[i] + x[j]
Can someone point out why my code for D is getting TLE for testcase 9 ? I guess it's O(mn) which shouldn't give TLE. I maybe wrong though.
The main idea is simple: Consider a directed graph with n vertices, with an edge from i to j iff the numbers i, j are adjacent in all m permution. Note that for any vertex,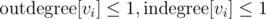 ,and which vertex (if any) v is connected to can be checked in O(m), so for all vertex doing this takes O(mn). Now the answer is
,and which vertex (if any) v is connected to can be checked in O(m), so for all vertex doing this takes O(mn). Now the answer is 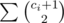 where ci ranges over the sum of connected components.
where ci ranges over the sum of connected components.
Could've implemented E easily had I not spend more than one hour implementing+debugging this :/ (got the idea for E within a few minutes)
I'm pretty sure it's just you're not using fast I/O. I TLE'd on 9 too and it passed once I fixed that
https://codeforces.net/contest/1043/submission/45019500 Any idea why this got a TLE? It's o(nmlogn) if I'm not mistaken.
same here. TLE on 7 using python3 then accepted using c++ scanf
Is E solved using the fact that min(a+b) = (a+b-abs(a-b))/2?
min(x[i] + y[j], x[j] + y[i]) = min(y[j] — x[j], y[i] — x[i]) + x[i] + x[j]
I rather used the fact that xi + yj < xj + yi is equivalent to xi - yi < xj - yj -- and then you can just use variables zi = xi - yi.
How to solve F??
The problems were nice and interesting. But maybe the set together was easy.
What is the hack for B?
My solution was a brute-force check if constructing a valid x is possible for a given k. Got hacked because I initialised x to -1 each time, but x[i] can take value -1 sometimes...
Isn't a[i]-a[i-1]>=0?
The second line of the output should contain l integers — possible lengths of the lost array in increasing order.That's the output.
a[i]is the input array — that need not be in any particular order. Look even at the third sample (1 5 3)oh my bad misread the question twiceIt says pending systests, but systests have already started?
Yep.
As wise man said, please stop creating problems.
This round was much easier than usual cf rounds, A, B, C, D were pure ad-hocs, and E too was easy. I didn't even read E because it was E :( .
What did you gain from it not reading??
I prefered hacking other's solutions because I didn't thought E will be so easy, only to realise it later that it was simple ad-hoc,(binary search).
I directly jumped to E after solving C. This was good chance for me to solve 4 question first time if I wasn't that over-confident.
This time I can agree actually
Or maybe just another notorious coincidence?
problem F is from polish contest, author is polish
https://szkopul.edu.pl/problemset/problem/4ftrK3Aqy2bpLk32N7wmjdZR/site/?key=statement
My vote is on notorious coincidence (read: the author knew this problem). It's not the same problem though, N is higher and maxA is lower. Modifying a problem so it has a different solution is fine.
Sorry, I didn't know this problem. I don't know all problems from POI.
+1
Thumbs up for the problem D.
This is the first time it was interesting for me to read the story in a problem. I have never experienced that feeling while reading problem statement. The only artificial smell is that we're asked to find the number of different ways to eliminate ambiguities. At first I thought that the problem would ask us about deciphering who is trying to fool us (from the neighbours) and trying to lead the investigation astray :)
Go to Timus for really cool stories. Or you also may be excited by a story in one of our contests: http://codeforces.net/gym/100812 (written by Shlakoblock)
Yeah but he must be a pretty bad detective to just ignore the evidence that doesn't work for him .-.
I hope strong cases for F.
Nice tasks :)
Was the last problem created by the authors, by coordinators (KAN, cdkrot) or by 300iq? :)
By my friend isaf27 :)
https://codeforces.net/contest/1043/submission/45019500 Any idea why this got a TLE? It's o(nmlogn) if I'm not mistaken. Could someone check it and let me know? Thanks!
I think long long for every variable is causing TLE. Try to avoid putting long long everywhere.
Use vector instead of map. I also got TLE for that.
How much cases do you have for model solution of G?
Judging from the solution, it seems there are about 7 ~ 9 cases. Great!
I found some recursion here :P
That 700 lines for G from tourist...
tourist Got TLE :( for D
His worst is even better than my best :D
and his worst rate is still better than everyone!
why wrong answer in test case 2 is considered as a penalty in problem B. Link to the solution in which wrong answer in pretest 2 is considered penalty :
Your text to link here...
Please take a look into it
Because only a fail on test case 1 isn't considered a penalty, and 2 ≠ 1.
Wrong answer (or TLE, or MLE, or RTE, or...) on anything greater than test 1 counts as a penalty — even if that case is a provided sample. Only test 1 is excluded.
Why this code for E gives runtime error? https://codeforces.net/contest/1043/submission/45014978
When easy problems are attached with unnecessarily long question sentences, it is only an English reading comprehension contest for those who are not English speakers.
Great contest , nice questions, nice tests, and I actually understood questions with reading only one time:)
Contest featuring most advanced algorithms to date:
(A) Binary Search (B) for loop (C) for loop (D) Binary Search (E) Binary Search
"Balanced contest"
I actually liked the adhoc nature of the contest though
It seems you use binary search where it is not necessary =) I have 0 BS's in solutions of this contest.
Thank you for your insight. I have updated the topics.
Updated list:
(A) loop (B) loop (C) loop (D) loop (E) loop
According to your classification, 95% of the problems will have "for loops" topic :)
Some REAL quotes:
"95% of the problems ARE 'for loops' topic, it's just people came up with this pesky term 'algorithm' to describe basic operations"
"I agree with Iightcode, he is genius"
It would be ok to see such comment from somebody, who solved all these problems in about a hour. From you it seems like one more comment of type <I want contribution!>.
<I want contribution!>.
What you think about anything I post is your own business. But why is it not ok to post what I want to say? I don't meet a rating threshold?
And by the way, if you really are going to set such requirements for others at least meet them yourselves.
You can post anything that you want to say. As I also can. As we both do. And no, I try not to judge people by their rating, rather by their words (as in your case too).
I set such requirements because you said (implicitly) that problems were easy and (explicitly) that contest was badly balanced. Maybe it was really easier than average CF round, but it should be said by somebody, who really feels that problems were easy (for 2 hours, of course). I didn't say it and you did. That's why you should meet such requirements and I shouldn't.
Sorry if I seemed like I was insulting the round. I actually like the round because it focused more on thinking than algorithm.
I never meant to say round was easy, just that problems could be solved without advanced algorithms and more thinking.
man why was I soooo sloooooow solving C
A notorious coincidence
Very mysterious...
Yes, they are the same person, have you ever spotted ksun48 and mnbvmar in the same location?
I think I might've. But there was snoweverywhere so I could not tell for sure.
My point wasn't that they are equal. The point is, that two nutellas got AC 2 ms under the TL.
And CF top 1 didn't pass it at all.
that's the difference between C++11 anh C++14 :))
Can someone help what is wrong in this? http://codeforces.net/contest/1043/submission/44997704
temp += max(0, i - a[i]);should betemp += max(0, i - a[j]);Tried running locally it was giving AC.
how to get a random hoodie?
In the next contest become top-1 and make sure that nobody's gonna score more than you.
Run the script locally with seeds
(your score),(your score - 50),(your score - 100)etc until you find a seed where you win a random hoodie.Make a corresponding number of unsuccessful hacking attempts.
problem B, round 412?
How about giving up first place if second place person's score can get you hoodie?
That person can betray you and make unsuccesful hack
I misread problem C and did not know that there are just two letters. Does my code really solve it for general ? my code
Uhh, same here, probably I will never realize it if I never see your post. Holy shit man, no wonder so many people already solved it the time I did. mine
i think this contest rating changes can change top rated user in CF. i think mnbvmar will be top rated user after rating changes !!!!!
Revolution begins
Last time it happened in the summer 2016 :D
It happened. Congrats to mnbvmar.
You are mistaken. Last time it happened in the spring of current year after CF #470 round.
Or this was simply div2 contest + unsovlable task. Which for best guys in div1 means typing speed contest + every little mistake means -200 rating.
ye boi
Does it work on test
10 15 42 44 46 (all the even starting from 42)? The answer is 2 (15 and almost any other number (but not 10 and 42) so pairs of neighbours don't work.Well, probability for that case is 1/n per random try (where n is less then 300000 becasue it's reduced and there's 50000 iterations so it's probably not hackable)
Just tried it and it prints 2. Thing is I also remove multiples of numbers that are among the given so this leaves me with only 13871 numbers.
So, 45023600 gives 4 while answer is 2 (gcd(15, 28) = 1)
Why is time limit for D so tight? Some NlogN solutions have passed and some didn't. I don't know if it wasn't the expected complexity.
Update: My two solutions for D: TLE and Accepted. Both are O(NMlogN), just a one line difference (cin.tie(0);).
there's O(mn) solution (mine passed in 200ms)
Yes, I know. Maybe I ignored it thinking O(NMlogN) was enough to pass. These kind of testcases should be added in pretests because they are not even hackable.
Who (outside of top 50) gets hoodies?
My solution for F (45014411) failed in contest with tle 35:(. But it later passed all 4 times I submitted it in practice just after adding "srand(chrono::steady_clock::now().time_since_epoch().count());". 45021752. It is basically removing duplicates and then removing multiples of numbers and then kind of bruteforce with pruning. Can this solution be hacked and testcases are weak or can it be proved that it will work with high probability?
It seems like you are not using Mersenne Twister in your first solution, relying only on default random function without setting seed (which makes it totally predictable).
So, for any fixed n your shuffle is just a fixed permutation, which could be inverted. Then hacker could just take a test where bruteforce is working too slow and apply inverted permutation to it. In that case after random_shuffle you will get that bad test.
Thats ok. But even with true randomness should such solution work?
Well, seems like not.
Suppose we have a number 299 999 and every number from 150 002 to 300 000 which is divisible by 2 — n = 75001. The answer is clearly 2 (gcd(299 999, 300 000) = 1), but you can get it only with 299 999. Note that no numbers would be deleted as duplicates or multiples.
Let k be the position of 299 999 in shuffled array. You will need to do at least k*(k-1)/2 operations to get there (because your map stores every number you processed so far if ans >= 3, and until position k ans = 12), and if k is big enough, this number is too big.
I runned your code on test above locally, and it took several minutes to finish (depending on position of 299 999 in shuffled array).
Thank you! It makes me feel better that my solution didn't pass during the contest:D
There is another trick which allows you to reduce the number of candidates even more: You don't need to keep two numbers which have the same set of prime divisors. So if you have 2*2*3 and 2*3*3 keeping just one number is enough. This will reduce the number of candidates to 14548 in the provided test case.
I used this during contest and my solution passed in 280ms. See 45018592 for details.
I think I would have TLE on my own problem D solution with test:
100000 10
1 2 ... 100000
1 2 ... 100000
...
1 2 ... 100000
100000 99999 ... 1
This is not to blame the judges, but kind of disappointed that this submission 45015775 of mine for problem E failed the time limits. I did not think the I/O would be so slow for the problem. This would probably pass within 2.1s or less I guess. Please consider setting a little more kind time limit for problems where solutions with worse complexity has no chance of passing the test.
just add 2 lines in your template and forget about slow IO
No one to blame but yourself. You used fast IO in D because you were afraid of 10^6. You didn't use fast IO in E while it was almost the same input size, 12 * 10^5 but with larger numbers so input/output is even larger.
I also think problem E had too much I/O for the time limit. I usually like to use python to solve problems, and with some trickery it is mostly possible to solve any problem on cf with python (using pypy). However this problem had so much I/O that I was not able to do the I/O in under 2 s. Had to resort to C++ to get my solution to pass.
I really think the constraints should be made such that not only C++ is able to pass. Currently this problem was mostly testing how quick I could get the I/O, which is not what makes these competitions fun.
A sample solution I made in PyPy 2, 45036971, which might interest you.
Messi got injured in this round.
I think problem setters need to re-consider limit for python. I have one implementation code of problem D, correct algorithm. However, I got different verdicts from different compilers: — http://codeforces.net/contest/1043/submission/45023038 — http://codeforces.net/contest/1043/submission/45021411
If you're using Python for anything past Div 2 B, you need to acknowledge the possibility that you can get TLE with the optimal solution. Python is too slow for most problems. Use C++ or Java.
Sadly,this contest changed the world rankings !
What's with test case 36 on D. I see tourist got TLE on it, and many of my friends also did. Why did this happen?
Because a lot of people solved it using directed graph. To construct it you need a map of pairs of integers, which is apparently slow. I managed to AC it, but with few pragmas (even then with 998ms) , my submission.
Consider using 100000 maps. I passed in 600ms.
just realised you dont need a graph at all...
I just want to point put that you don't need maps to construct the graph. I'm actually surprised so many people went this path and submitted a sub-optimal solution (by a factor of logN). I guess it was more convenient and nobody thought it would TL.
45024667 vs 45024739,the only different is the space after
* author: touristand the c++ versionWhitespace is ignored by compiler, so technically the only difference is c++ version, which is surprising that just because tourist used different C++ version he drops 100 places.
I want to specially thank the problemsetter that came up with problem F. One of the most beautiful problems I've seen lately.
tourist getting TL 45001078 on D during contest with C++11, but AC 45024674 post-contest with the same code submitted with C++14. feelsbadman
Still, inserting 1M elements into a map with TL=1s is never a good idea.
Polish writers need to "polish" their problem setting skills!!
Good contest, it’s a pity that I didn’t have time to write (it coincided with conducting XXVI team championship of pupils of St. Petersburg in programming)
when will random winners announce ??
Those who got hoodies, share the picture of it. I really want to see how it looks.
Are there any contests available this week?
are there any contests available this week?
NOIP is coming..
So who won the random hoodies?
tourist score is 8905 I guess. Anyone interested can generate the answers from the code given by kun above (assuming tourist survives systests)
The seed is the number of points from the onsite winner. It is 8905
55 62 122 123 128 132 135 155 203 254 257 290 321 348 372 395 416 427 436 441
And the winners are:
By the way, non-random winners are:
Has anyone received the hoodie yet?
Could you please update on this?
If you had received message to fill your delivery info some time ago, it should be all good. For more detailed status, please ask gKseni.
I understand you are not supposed to look a gift horse in the mouth. But does the hoodie really need a gigantic Che Guevara picture? What does it have to do with Botan Investments, Codeforces or programming in general?
I thought it is Grigory Perelman with π instead of a star on his cap
pic?
XDDDDDDDD
This is SO GOOD and SO BAD at the same time