


Hello Everyone!
Japanese Olympiad in Informatics Spring Camp 2020 will be held from Mar. 19 to Mar. 23.
There will be four online mirror contests during the camp.
- day1 : Mar. 20 (01:00 — 06:00 GMT) or Mar. 20 (07:30 — 12:30 GMT)
- day2 : Mar. 21 (01:00 — 06:00 GMT) or Mar. 21 (07:30 — 12:30 GMT)
- day3 : Mar. 22 (01:00 — 06:00 GMT) or Mar. 22 (07:30 — 12:30 GMT)
- day4 : Mar. 23 (01:00 — 06:00 GMT) or Mar. 23 (07:30 — 12:30 GMT)
The contest duration is 5 hours and there are 3 or 4 problems in each day. Problem statements will be provided both in Japanese and English.
There might be unusual tasks such as output-only tasks, optimization tasks, reactive tasks and communication tasks, just like International Olympiad in Informatics (IOI).
The contest site and registration form will be announced about 30 minutes before the contest.
Details are available in the contest information page.
We welcome all participants. Good luck and have fun!
UPD: The timezone of the latter mirror contest is modified.
UPD2: The timezone of the latter mirror contest is again modified.
UPD3: Now, you can play mirror contests during any contiguous 5 hours until 12:30 GMT.






Just curious but will the judge be opened for analysis mode after the contest?
When I click the contest information page link, I see that Round 2 is 16:00 JST but that does not seems to match ur 08:00 GMT timing. Maybe there was a mistake with the timing?
Update: I have noticed that the contest information page has changed the timing to 07:00 GMT, which now matches the 16:00 JST, but the timing at this cf blog still indicates 08:00 GMT? ._.
I'm sorry that the timing in this blog was wrong. Round 2 will start in 07:00 GMT.
can u tell me the editorials please.
Will there be an English editorial after the contest?
I have heard a lot about the high quality and difficult of JOISC. Hoping for a nice contest and solving non-zero problems
Can you explain why there are two time ranges each day? Does that mean two contests per day?
From the contest information page:
"The duration of the contest is 5 hours. The same contests are held twice (Round 1 and Round 2). Contestants can participate in one of Round 1 or Round 2 according to their time zone."
Auto comment: topic has been updated by yutaka1999 (previous revision, new revision, compare).
Why was the starting time of the second contests shifted to an hour earlier? Now it starts at the exact time when kickstart round A ends.
At least you can ak kickstart in 30m unlike me :sob:
Aeren :orz:
It was't actually shifted, just a mistake from OP.
Why does it say mirror contest starts at 7 GMT, but analysis mode ends in 20 minutes?
Will the second contest start 20 minutes later?
Oh i see , 30 minutes later.
Auto comment: topic has been updated by yutaka1999 (previous revision, new revision, compare).
when can we get the solution?
Let's maintain some "groups" of dusts. Each group will contain some number of dusts, such that $$$x_i \leq x_{i+1}$$$ and $$$y_i \leq y_{i+1}$$$ for dusts in this group.
To recalculate these groups on queries, we should take some groups, cut the prefixes where $$$x_i \leq a$$$ and $$$y_i \leq n-a$$$ for some $$$a$$$, and merge all these prefixes to one new group (after changing $$$x_i$$$ if it is the query of type $$$H$$$ or $$$y_i$$$ if it is the query of type $$$V$$$).
I claim that if we will proceed all these queries in $$$\mathcal{O}($$$ the number of groups where the deleted prefix is not empty $$$)$$$, then it will work in $$$\mathcal{O}{(m+q)}$$$.
Why? It is easier to analyze this complexity backward, we should take the last added group, split it and merge the parts of this group to some previous groups. Note that we will spend $$$\leq$$$ $$$($$$ size of the group + 1 $$$)$$$ operations now, and also in the future, we will spend $$$\leq$$$ $$$($$$ size of the group $$$)$$$ new operations because of the merged parts from the current group. Summing this up by all current groups, the number of moves is $$$\leq 2m+q$$$.
To maintain all these groups, we can maintain a treap for each group. (It is easy to split the treap and to merge two arbitrary treaps we can use a well-known method similar to splitting and merging segment trees).
To find the groups with the non-empty required prefix, we may note that the fixed group will affect all queries with $$$x_1 \leq a \leq n - y_1$$$, so we can maintain the treap of all groups, sorted by $$$x_1$$$ and maintain the largest $$$n-y_1$$$ in the subtree.
So we get the $$$\mathcal{O}{((q+m) \log^2 (q+m))}$$$ (or $$$\mathcal{O}{((q+m) \log (q+m))}$$$ if treap merging works in $$$\log$$$ time) solution with $$$\mathcal{O}{(q+m)}$$$ memory.
Also, we can use the fact that in all groups all $$$x$$$ coordinates are the same or all $$$y$$$ coordinates are the same, and maintain splitting-merging segment trees for the other coordinate, like that we can get the $$$\mathcal{O}{((q+m) \log (q+m))}$$$ solution with $$$\mathcal{O}{((q+m) \log (q+m))}$$$ memory.
Would you please show us why we need $$$y_i \le y_{i+1}$$$ hold for each group, instead of $$$y_i \ge y_{i+1}$$$ as Subtask 3?
With this constraint, the set of changed elements is the prefix.
When I add a new element, I create a new group with only one element.
Actually, the sign does not matter, because in each group one of the coordinates is always the same.
Oh I see. Thanks a lot.
Thank you very much and can you please show the code?
Maybe I didn't understand anything, but is it true that your statement about groups didn't use structure at all? For example, if we have sizes of groups 1,2,.., n, you can spent O(n) time in every iteration.
Note that we will spend ≤ ( size of the group + 1 ) operations now, and also in the future, we will spend ≤ ( size of the group ) new operations because of the merged parts from the current group.Why is the number of future operations <= (size of the group)?
I have implemented your idea but it got TLE. Do u have your own implementation?
Hamburger was such a pain to code xddd. I have completely no idea how, but I managed to code it without any bug xddd
What was your solution?
In fact there is a correlation between being pain to code and being pain to describe xD.
Assume max(L) > min(R) and max(D) > min(U) for simplicity. I will put skewers only on 4 lines determined by these values. First thing to even get started, I consider (in my mind only) k! cases relative positions of skewers. If k<=3 then one of them is "in the corner" and I can branch (wow, only 15 pts for this? this seems really rough even in comparison to what is left). If k=4 and some skewer happens to be in corner as well, branching works as well, so I am left with the hard case when every skewer is in the interior of its side.
I iterate over positions of skewer on line x = min(R) and consider two cases. Whether the top point is on the left of the bottom point, or whether it is the other way around. In each of these cases I greedily maximize x values of bottom and top point. If top point is on the left, I first decide its coordinate and then decide the coordinate of the bottom one taking into account it can't be on the right of the leftmost right side of rectangles which intersect with exactly top and bottom side. In the second case — the other way around. And I just check whether I can put point on the right side in some place. All checks and decisions are made in constant time based on a ton of arrays with prefix/suffix minimums/maximums.
Here is my code: https://ideone.com/RNJXof Is your solution similar to mine?
I have a question about the conclusion:
"Assume max(L) > min(R) and max(D) > min(U) for simplicity. I will put skewers only on 4 lines determined by these values."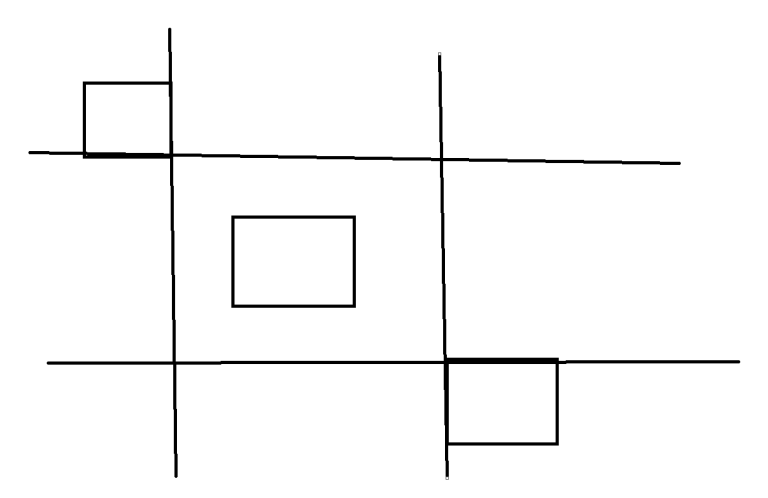
As shown in the picture above, the rectangle in the middle isn't crossed by any straight lines, but it's necessary to put skewers on this rectangle.
I may have got it wrong.
The conclusion is a bit premature. In fact, either one of the skewers needs to be put in one of the corners of the rectangle determined by these 4 lines (and the remaining rectangles/skewers are considered recursively after purging the rectangles we already covered), or all skewers will lie on the sides of this rectangle.
In your case, you'd put one skewer in the upper left corner of such a rectangle. When you recurse, you only need to cover two lower rectangles (and the straight lines you drew will change).
Ok, I get it now, thanks!
Does anyone want to try to hack my Hamburg? https://github.com/tmwilliamlin168/CompetitiveProgramming/blob/master/JOI/20S-Hamburg.cpp
What would be the expected time complexity of this?
It actually passes all tests except one if you never shuffle, and if you shuffle only once in the beginning it gets 100 with the same run-time.
Done, and every submission for this problem is rejudged.
According to the stats page, the number of accepted solutions became 8 (from 28!)
How to solve A, somebody please.
How to solve Prob A building?
First, I think the 11-point subtask 1 ($$$N \leq 2000$$$) is not very difficult. We let $$$dp[pos][cnt][plan]$$$ the boolean value which records if "when deciding how to decorate for building $$$1, 2, 3, ..., pos$$$, we can decorate exactly $$$cnt$$$ building in plan B, and the decoration of building $$$pos$$$ is $$$plan$$$ (A or B)." The dynamic programming works in $$$O(N^2)$$$.
But, if we notice one good property, we can drastically improve the computing time to $$$O(N)$$$.
Let's think about the sequence of $$$dp[pos][0][plan], dp[pos][1][plan],..., dp[pos][i][plan],...$$$ and consider which $$$i$$$ makes the DP value true. Actually, the condition $$$i$$$ which is true is always an interval — in other words, the form of $$$L \leq i \leq R$$$ (for any $$$L$$$ and $$$R$$$), or "impossible". Proving this fact is not difficult, just to use induction.
That's how we can improve the DP into $$$O(N)$$$.
I have a different solution to A that was not motivated by the $$$O(N^2)$$$ DP solution, but I feel is much more natural and motivatable. Call a sequence of $$$2N$$$ positive integers $$$X_1,X_2,\cdots,X_{2N}$$$ valid if each $$$X_i$$$ is equal to either $$$A_i$$$ or $$$B_i$$$ and the sequence $$$X$$$ is non-decreasing (note the lack of the "exactly" $$$N$$$ As and $$$N$$$ Bs).
First, we check which characters are "fixed", i.e. across all valid sequences, this character must be an A (and similarly for those that must be B). To do this, we construct a valid sequence from $$$1$$$ to $$$2N$$$ by picking the smallest number that we can at each point. At each index, we see if we must use the larger number or if the smaller on suffices. If we are forced to use the larger number, this fixes that character. We construct a similar valid sequence from $$$2N$$$ to 1 by picking numbers that are as large as possible.
The fixed characters create disjoint intervals of characters that are not fixed. Each of these intervals are completely independent, so we consider each one separately. Initially, we greedily put the smallest number we can in each position, and we track the number of As that we use. For the sake of simplicity, WLOG the number of As is used is less than $$$N$$$ (we can flip the A and B arrays).
This almost certainly does not give the correct string that we want, but that is OK since we can change some of the characters in the string. When we "flip" the $$$i^{th}$$$ character (A to B or B to A), we are by definition changing it from the smaller of $$$A_i$$$ and $$$B_i$$$ to the larger of the 2. Hence, such a flip will only affect numbers later in the sequence. In particular, flipping the $$$i^{th}$$$ character may require us to flip the $$$(i+1)^{th}$$$ character as well.
This tells us that that the intervals between fixed characters can be further broken into "chains", where flipping a character in the chain will cause a chain-reaction (haha) that flips all characters upto the right most endpoint of the chain. Furthermore, these chains are by definition disjoint, so we can also consider them separately.
Thus, for each index, we can compute the net change in As that will occur if we flip the character at this index. Since the net change at each index is always $$$\pm 1$$$ of the index in front of it if it is in the same chain, the possible net changes across all of the indices in a chain is always a contiguous segment of integers, e.g. all integers in $$$[-4,3]$$$, and always includes a 0 (since we can simply do nothing).
To compute the answer, we greedily take the net change of largest magnitude that moves the number of As closer to $$$N$$$. If it is possible to achieve a value $$$\geq N$$$, we can construct the string by greedily picking the best positions to flip, then finding the correct position to flip the give us exactly $$$N$$$ As. If it is not possible, we output -1. Overall complexity is $$$O(N)$$$, but a bit messy.
What are the highest official results in Japan? Who passed to IOI?
Can we solve Day1C in $$$\Theta((M+Q)\log (M+Q))$$$?
Here is my $$$\Theta((M+Q)\log^2 (M+Q))$$$ solution and it could be optimized to $$$\Theta((M+Q)\log(M+Q) \log\log (M+Q))$$$:
We try to use divide and conquer to maintain dusts. Consider all dusts with $$$0\le x, y\le \frac n2$$$, then the effect of procedures will be divided into two types:
1. All dusts in the rectangle got $$$x = \max(L, x)$$$ or $$$y = \max(L, y)$$$ when $$$a\le \frac n 2$$$, we can maintain $$$x$$$ and $$$y$$$ respectively. This could be maintained through one heap for $$$x$$$ and one heap for $$$y$$$. We should record the pointer on heap of each dust. The change of pointer during merging could be maintained small to large merging or a DSU.
2. When $$$L > \frac n 2$$$, some of dusts are pushed into a sub right triangle. We could just pop heap on one dimension and the elements in another dimension should be deleted lazily. So each dust will be "pushed" $$$O(\log n)$$$ or $$$O(\log (M+Q))$$$ times.
It could be easily implemented through a
map<int, vector>in $$$\Theta((M+Q)\log^2(M+Q))$$$ time complexity. Noticed that the key of this heap is small, so we could replace the binary heap with something like vEB tree to reach the time complexity of $$$\Theta((M+Q)\log (M+Q) \log\log (M+Q))$$$.I have a solution with log, check my comment :)
My implementation of this idea
Let dp[i][0][0] denote the minimum possible number of A segments till ith index such that the non decreasing condition is satisfied and in the ith building plan A is chosen
let dp[i][0][1] denote the maximum possible number of A segments till ith index such that the non decreasing condition is satisfied and in the ith building plan A is chosen
Let dp[i][1][0] denote the minimum possible number of A segments till ith index such that the non decreasing condition is satisfied and in the ith building plan B is chosen
Let dp[i][1][1] denote the maximum possible number of A segments till ith index such that the non decreasing condition is satisfied and in the ith building plan B is chosen
base case
dp[0][0]=1
dp[0][1]=1
dp[1][0]=0
dp[1][1]=0;
now its easy to calculate dp[i] from dp[i-1] (details are present in the code)
for constructing the answer we first check:-
if((dp[n-1][0][0]<=n and dp[n-1][0][1]>=n) or (dp[n-1][1][0]<=n and dp[n-1][1][1]>=n)):answer exists
else: answer doesn't exist
for constructing answer we work backwords from n-1 to 0 which is left as an exercise to the reader
code- https://ideone.com/1xsqh1
Thank you!
How to solve B(Hamburg Steak)?
Here's an extremely brief explanation.
Let $$$maxR$$$ be the rightmost end of any rectangle. Lemma: there will be a point with exactly $$$x = minR$$$. Similarly, compute $$$maxL$$$, $$$maxD$$$, $$$minU$$$ (corrected, thanks to Elegia).
You got a special rectangle-area and you need to put a point on each of its sides. If $$$k = 3$$$, there will be at least one point in corner. Iterate over corner, put a point there, branch with $$$k = 2$$$.
If $$$k = 4$$$, there is also a case where there is no point in any corner of our rectangle-area. Instead, there is exactly one point on each of 4 sides. Analyze what is required by each of $$$n$$$ input rectangles. Then you can iterate over position of point on left side of the rectangle-area and greedily choose positions on remaining sides (starting with top side). It might help to assume that point from top side is on the left from point on bottom side.
EDIT: I'm refering to solution by Swistakk and he described it some more here https://codeforces.net/blog/entry/74871?#comment-590866
I think it should be minR, maxL etc.
Insight Errichto had to problem Building4 actually allows to count number of required sequences in $$$O(n \ polylog(n))$$$ which is not doable with typical solution.
Insight: for two consecutive houses $$$(i, i+1)$$$ we can almost always deduce that something is taken. For example, if $$$i: (5, 8), i+1: (3, 10)$$$ then $$$10$$$ must be taken. Also, if $$$i: (5, 8), i+1: (9, 10)$$$ then $$$i$$$ and $$$i+1$$$ are independent and we can split the input into two parts.
This way we can split the input into parts such that each part consists of slowly increasing pairs like $$$(1, 5), (2, 6), (5, 8), (7, 10)$$$. In the input of such sequence of pairs, the smaller value must be taken, and then the bigger value in each pair in the remaining suffix. This gives linear number of possibilities for the number of A in this part. Considering prefix shorter by 1 changes the number of A by 1, so the possible numbers of A are an interval. The sum of possible intervals like $$$[5, 10]$$$ and $$$[2, 4]$$$ are also an interval, here it would be $$$[7, 14]$$$. You can determine how many A you need from each interval then in some greedy way.
This logic both gives a non-dp solution and provides a proof why the possible total numbers of A's are an interval. And you can use FFT and count ways too.
Day 1 tasks here: https://oj.uz/problems/source/494
How we can see results of the second online mirror which is going now?
How to solve day2 B and C?
I tried to solve B by storing all cliques using DSU, but failed to implement it:(
B:
Assume we have a vertex $$$v$$$ and a clique $$$c$$$. If there is an edge between $$$v$$$ and any vertex in $$$c$$$, then the social exchange will create all possible edges originated in $$$v$$$ and ending in every vertex from $$$c$$$.
Suppose we have two cliques $$$A$$$ and $$$B$$$. If we have an edge that goes from some vertex in $$$A$$$ to some vertex in $$$B$$$ and an edge that goes from some vertex in $$$B$$$ to some vertex in $$$A$$$, then after the social exchange these two cliques merge into one clique.
With these observations we can maintain a set of cliques and edges between them. When we have to merge two cliques, we can use small to large technique to do it effectively.
For Ruins 3 (problem 3), it's just a 2-dimensional dynamic programming and we can solve in $$$O(N^3)$$$. However, despite I said "just a 2-dimensional dynamic programming", it's very difficult.
Let the DP table $$$dp[x][y]$$$. Of course, we will let $$$x$$$ the current position. So, what the $$$y$$$ stand for? It's quite non-obvious.
Let's assume the heights of pillar $$$x+1, x+2, ..., 2N$$$ are already determined. Then, the pillar $$$x$$$ will be either of following: "it will survive if the $$$h_i \geq bound$$$" or it will not survive". We define the "level" of situation like, if it can survive, $$$level = bound$$$, otherwise, $$$level = N+1$$$.
The value of $$$y$$$ is very the level of this situation! For calculating the level $$$y$$$, we use the heights of pillar $$$x+1, x+2, ..., 2N$$$, so you may think that we run DP in order $$$x = 2N, 2N-1, 2N-2,..., 1$$$. But in this way, it does not work well.
Actually, we run DP in order $$$x = 1, 2, 3, ..., 2N$$$. Quite surprised? Actually it's true. Even in this way we can count the number of ways accurately. It's like doing "pre-established harmony".
When we decrease the level $$$y$$$ from $$$y_r$$$ to $$$y_l$$$ (assume $$$y_r > y_l$$$), we decide the relative position of pillar with heights $$$y_r - 1, y_r - 2, y_r - 3, ..., y_l$$$.
In this way, we can easily improve the seemingly-difficult problem to $$$O(N^3)$$$ time. In my implementation, the number of multiplication and addition is both $$$\frac{1}{6} N^3 + O(N^2)$$$, and was executed in less than 0.1 seconds. However, this case might be that FFT improves the time complexity to $$$O(N^2 \log N)$$$.
My implementation. Similar to the above, except I run DP in the order $$$2N\ldots 1$$$. $$$dp[j]$$$ corresponds to $$$level=j+1$$$ as described above, meaning that we currently have pillars with final height $$$1\ldots j$$$ but none with $$$j+1$$$.
What's your thought process to calculate $$$ways[i]$$$ in your code? I have a different way of calculating it though both ways end up as $$$\binom{2n}{n} \cdot (n-1)!$$$, so I think there should be a simple combinatorial proof that I missed.
It's similar to calculating the number of correct bracket sequences. There's probably some rotation argument that shows that only one out of every $$$n$$$ of the $$$2n\cdot (2n-1)\cdots (n+1)$$$ candidates is okay.
Hi Benq, I have been trying to understand your implementation for hours and have failed to understand the solution. I am wondering if you could explain what specifically is the ways array calculating the number of ways of (number of ways to number pillars that stay up that have not been numbered?), and how you were motivated to calculate it as such.
(roughly the following)
For each of $$$k$$$ pillars assign them one of the heights $$$1,1,2,2,3,3,\ldots,k,k$$$ such that no two are assigned the same version of the same height. After placing a pillar, while two pillars have the same height decrease one of their heights. How many ways are there to do this such that the first time when there is a pillar of height $$$1$$$ is when the $$$k$$$-th pillar is placed? $$$precalc[k-1][k-1]\cdot fac[k-1]$$$ calculates the number of ways to place the first $$$k-1$$$ pillars. Do you see why this is then multiplied by $$$k+1$$$?
I finally figured it out! (that took way to long oops). I see that you multiply by 2 for single elements as you're calculating the ways array so that when you divide by 2 ^ n later it correctly divides out pairs of two so they are not counted twice, and k + 1 can really be thought of as (k — 1) + 2 to account for adding the single 1. Thank you for your help! Just curious is this what inspired USACO Open p1, or is it just a coincidence they use this same technique?
Just a coincidence. (Personally, I didn't notice the similarity at all.)
I've finally managed to understand the solution. Very beautiful problem!
How to solve A and B day2 please.
Day 2 tasks here: https://oj.uz/problems/source/495
How to solve day 2 A? I could only get 64...
(Why the downvotes?)
Let's refer to chameleons as vertices. Draw an edge between two vertices $$$a$$$ and $$$b$$$ if querying the group $$$(a,b)$$$ would give one distinct color. In other words, $$$a$$$ and $$$b$$$ have the same original color or one of $$$a$$$ or $$$b$$$ loves the other (but they can't both love each other).
The first step is to generate all the edges. We'll do this by adding $$$1,2,\ldots 2N$$$ to the graph in this order. When adding vertex $$$i$$$, first split vertices $$$1\ldots i-1$$$ into two parts such that each part is an independent set (this must be possible since the graph is bipartite). Then for each part, we can use binary search to determine which vertices are adjacent to $$$i$$$.
Each vertex $$$v$$$ has degree one or three. If $$$v$$$ has degree $$$1$$$, then clearly the vertex adjacent to it is the one with the same color. Otherwise, suppose that $$$v$$$ has degree $$$3$$$. Then we can determine which vertex $$$v$$$ loves by querying each of the groups consisting of $$$v$$$ and two of its three adjacent vertices. After doing this for all vertices, we can determine the vertex with the same color as $$$v$$$ for all $$$v$$$ with degree $$$3$$$, because only one vertex adjacent to $$$v$$$ will not love $$$v$$$ or be loved by $$$v$$$.
Code
Can someone further explain how the edges were generated with < 20 000 operations, as that was the hardest step for me.
There are at most $$$3N$$$ edges and each should take about $$$\log_2 N$$$ queries.
I agree that two parts are possible but how to obtain such a split? When we have a new vertex $$$i$$$ and it's independent with each of two existing parts, how do you know where to put it?
(I split into four parts instead because degrees don't exceed 3)
You only need to consider the edges that are present in the graph up to that point when splitting it into two parts (see the code).
If you participated Day1 Round2 but not Round1, then your account disappeared! That's bad!!
My account and 300iq's are gone (and 300iq has 300points in Day1 and Day2!!)
it says 206 in day 2.
How to solve A and C day3? please
For A, maintain a dp for each "connected component" from bottom to top. The dp for each cell denotes the maximum sum of stars you can remain if you forcefully pick the cell. Note that even if a cell is empty, we also consider it possible to pick the cell. To deal with stars in the same column, note that a higher star with lower value is useless, and after removing them, each column's star values are monotonic. Replace each star value with the difference between its value and the value of the star below it. Now, it is straightforward to update the dp when you go to the next row and merge components. You can optimize the dp with a lazy segment tree.
Sorry for the terrible explanation, maybe my code explains it better.
Thank you so much!
Can you explain your dp and its transitions in more detail?
Day3C:
for $$$A \ge 3$$$, let
y[i] = min(dis[u[i]], dis[v[i]]) % 3, then you can easily get to a nearer vertex through the color of the edge.otherwise ($$$A = 2$$$, $$$B\ge 6$$$ and $$$M = N - 1$$$), you should paint a chain with a period of
100110, then you can spend at most 3 steps to determine the direction you are walking so you will waste at most 6 steps. For a general tree, you should let the color of the child edge different from the father when there are branches. Then you can determine the direction at a vertex with $$$deg \ge 3$$$ and straightly go through the path to the root.Thank you very much!
Noticed that the information also contained the adjacency, so you actually got the color of 5 edges, not 3.
it makes sense now thanks :)
Day 3 tasks here: https://oj.uz/problems/source/496
Note that the interactor of
strayis incomplete (it chooses roads randomly), and all submissions will be rejudged after the grader is fixed.UPD: Now the interactor of
strayis the same as in JOI.Currently, there is a problem in submitting the code on oj.uz I think.
i submitted the code in oj.uz for problem C and i got 100 points but when i submit the same code in JOI submit i got 20 points + 2 wrong test cases in the last 2 subtasks , strange
Currently, the interactor chooses the roads randomly as in the sample grader. JOI's grader should have some complicated strategy.
ok thanks
How can I submit the code after the contest?
https://oj.uz/problems/source/496 See the comment above
Ok,thanks:)
How to solve day 3 B (Harvest)?
Instead of each person moving clockwise collecting apples, we can imagine it as apple trees moving counter-clockwise handing out apples.
Note that after an apple tree hands out an apple to person $$$i$$$, the next person to be handed an apple is unique — travel $$$C$$$ meters counter-clockwise and hand an apple to the next person $$$j$$$ that we meet. We can imagine the people as vertices in a graph, each with a single outgoing edge to some other vertices — the (directed) edge $$$(i, j)$$$
To answer a query for a vertex $$$V$$$, there exists 2 cases:
Now we still need to handle the periodic handing out of apples, produced by cycle $$$S$$$. Let's say the initial handing out times are in a set, then $$$S$$$ will hand out an apple which travels from $$$S$$$ to the predecessor of $$$S$$$ (and stopped there), on times $$$T_i + k \cdot len$$$, where $$$T_i \in set$$$ and $$$len$$$ is the length of the cycle, for $$$k = 0, 1, 2, ...$$$
For each vertex in the cycle, the query $$$T$$$ on vertex $$$V$$$ is equivalent to the query $$$T - dist(S, V)$$$ on vertex $$$S$$$. Transform all queries on this cycle to a query on the vertex $$$S$$$. Now, we need to find out how to compute a query on vertex $$$S$$$ on time $$$T$$$. Note that a query is the same as computing
This is equivalent to
We first sort queries by $$$T$$$ and sort all $$$T_i$$$. We can maintain an ordered set of $$$T_i$$$ under modulo $$$len$$$, adding an element to the ordered set as long as the current query's $$$T$$$ is greater than or equal to it. The ordered set of $$$(T_i \mod len)$$$ takes care of the $$$(T_i \mod len \leq T \mod len)$$$ part to a simple lower bound/order of key operation. $$$\left\lfloor{\dfrac{T}{len}}\right\rfloor$$$ and $$$\left\lfloor{\dfrac{T_i}{len}}\right\rfloor$$$ can be computed and maintained easily.
This yields an $$$O(N \log^2 N)$$$ solution.
My code.
Dango is the easiest local search ever, it was trivial to get 100 pts here, yet very few managed to do this. Why :|?
What I've done is:
while (something improved in last C steps) {
take random dango
if there are >=2 dangos blocking it then continue
if there is 1 dango blocking it then remove it
put this dango
}
Lol, I removed everything in $$$5\times5$$$ square and put the best combination of dangos. Only got 60 :D
Why should we replace a dango if it is blocked only by 1 dango?
To get another solution with the same number of dangos.
As Tutis said, it doesn't make our solution worse. However it makes your search space much bigger, so it will be possible to find improvements by some sequences of consecutive changes. Without that line, it gets 0 pts :P.
ohh ok thanks.
Local searches are not very known, especially within the high school students community. Please note that the output only tasks are very rare too. I think I have never seen them in other places except for JOI and IOI.
"I think I have never seen them in other places except for JOI and IOI." — said by guy who I teamed up with in Reply Code Challenge a Week ago and coming from a country that is home to Deadline24 and Marathon24 xD
I was still describing contests aimed for the high-school students. When I was in high-school I participated in Deadline24 and Marathon24 and never used any hill climbing nor annealing.
I spent 3 hours and got 39 pts :(
It’s an output only, you don’t want to do it unless they offer a plane ticket to Dublin
Fair point. But maybe you can put there some data structures to help you out?
No, OO is a much worser joke :(
Even those DS with +20 queries are at least science, isn’t it?
I believe that all the local searches and the whole discrete optimization field are still more scientific than the data structures with dozens of types of queries.
I didn’t mentioned discrete optimization at all. Local searches can be science with provable guarantees, but OO doesn’t work like that. And they give dozens of huge TC to analyze instead of dozens of queries that can at least be described in natural word.
Can you please provide your code for this solution. I am interested in your implementation as this is the first time i hear about local search algorithms. Thank you.
Here you go: https://ideone.com/K3nyE4
Key part is within lines 142-172. All the other things are kinda boring boilerplate like reading the input, generating valid positions of dangos, putting/removing dangos and printing result. I'm quite sure lines 127-141 are completely useless and can be removed.
Thank you very much.
Beautiful solution, very simple and smart, i like it.
How to solve A please.
We can use centroid decomposition.
Root the tree at the centroid, and keep track of previous centroids (these vertices will be "blocked" in the tree).
We will consider a city, such that the current centroid is included in this city, and all "blocked" vertices and vertices below them must not be included.
To construct this city, we take all vertices that have the same color as the centroid, check their parents in the tree, and if the parent has a different color, we will repeat the same proccess with that color. This can be done efficiently with a queue.
After this proccess terminates (there are no more colors that we must add), we will check if none of the added colors have vertices under "blocked" vertices, and if this is true we will minimize the answer with $$$amountOfColorsAdded - 1$$$.
After that, mark the current centroid as "blocked" and recursively solve for the subtrees.
Can you provide us with an implementation of the centroid decomp idea?
My code: https://ideone.com/nmqnMZ
An alternative solution using LCA and DSU.
Root the tree arbitrarily and color the cities. Two colors are connected in the DSU if any capital city including one of them also includes the other. We mark a vertex as visited if it's been completely processed.
The LCA of a capital city is necessarily the LCA of some color, so we push all of them in a queue. For each candidate LCA starting from the bottom most and going up, we try to construct a capital city rooted at that LCA. We will use a queue to store necessary vertices for the capital city, initially it contains unvisited vertices with the same color as the candidate LCA.
For each vertex in the queue, we connect its color with the color of the candidate LCA in the DSU, then if the LCA of its color is below the candidate LCA, we mark it as visited and push unvisited vertices of its same color to the queue, then redo the same thing for its nearest unvisited ancestor that is below the candidate LCA (it can be done efficiently with another DSU).
Once this process is finished, we check if all vertices of the colors connected to the color of the candidate LCA are visited and try to minimize the answer with sizeofcomponent-1 if it's the case.
UPD: I realized this should've given a 0 instead of 100, it fails on a small test like this (tree rooted at 1)
6 3
1 2
1 3
3 4
4 5
5 6
1 2 3 1 2 3
Do you have an implementation please?
I'll send it tomorrow because it's quite messy rn and it's getting late here
Here it is : https://ideone.com/YtxI22
Thank you very much!
did anyone use the following idea to solve the problem(capital city)
find lca of all nodes of each colour.
for example if nodes a1,a2........am are coloured with colour x
their lca is y and we add paths from y to each ai (i>=1 and i<=m)
now we repeat this algorithm:
1.choose path such that depth of the lower vertex is minimum.
2.take all paths such that they intersect with it and keep extending till possible(using dfs and path compression)
(this solution is an extension of the solution of subtask 3)
remove these paths and repeat the algorithm till the set of paths is not empty.
Not sure, do you have an implementation?
I have another possible soln. Haven't coded it yet.
The idea is to create a directed graph where an edge X->Y means that there is an edge between a town of city X to a town of city Y and that to connect all towns of city X, we will be required to merge city Y to it. The answer will be the smallest size strongly connected component in such a graph.
To create the graph, I do the following.
Let k be a constant. For all cities with no. of towns >= k, run a linear O(n) scan to create the edges.
Else, check all (no. of towns)^2 pairs in O(logn) time for edges.
Dango is a very cool problem! And the awesome visualizer is the coolest for sure!
I used Simulated Annealing to solve this problem. For now, my solutions are better than the given $$$Z$$$ (the grading values) $$$2, 6, 5, 8, 7, 8$$$, respectively.
What are your scores? And how to achieve them?
UPD: My Simulated Annealing program on Ubuntu Pastebin.
UPD2: My submission on oj.uz.
Indeed it looks great, works very fast and is really readable. However it is kinda useless. I don't imagine how you can get anything useful from it except for cases when your code clearly doesn't work as intended and you can see it on very small testcases.
Yeah, it just looks great, and indeed didn't help me. (but it looks great, that's neat to me)
Seams very complicated. Especially when i've never heard about annealing xd
But actually it's very simple, relatively.
Because in general, Output Only Problems are very complicated and need participants to find each input file's special properties and solve them separately.
For this problem I just used a single program and easily got full points, that's why it's relatively simple.
Will analysis be avalibe for Day 4?
Are there any available analysis at all?
Analysis as in analysis mode, not an editorial. It was open after every day for about 7~8 hours.
Sooo, analysis for you means ... upsolving xd? Analysis==editorial for me xd
It is stated as "Analysis Mode" in the CMS server previously so I guess that's why the word analysis is used here.
How to solve day 4 C (Treatment project)?
I've solved this problem during the contest. It was really a good problem! I was so impressed when I got the solution. Note that in this editorial $$$L_i$$$ is decreased by $$$1$$$, so that treatment project will process half-open interval.
First, to recover all citizens, we need to treat all people at least once. It is not an exception for person $$$1$$$ and $$$N$$$. So, we need to at least process treatment project $$$i, j$$$ which is $$$L_i = 0$$$ and $$$R_j = N$$$. It's okay if $$$i = j$$$ if possible.
Also, if all $$$N$$$ people finally recovered from coronavirus, there is a "border line" between infected area and non-infected area, if you plot in 2D when $$$x$$$-axis stands for "the number of days from start" and $$$y$$$-axis stands for "the ID of citizen". If no borderline exists, it means there is a hole that expands infection finally to all citizens.
Combining this two facts, the borderline starts at $$$L_i = 0$$$ and ends at $$$R_j = N$$$. and it should be connected. So now, let's use Dijkstra's Algorithm by letting each treatment project to vertices!
We can link from treatment project $$$i$$$ to treatment project $$$j$$$ (directed edge) if:
- When $$$T_i \leq T_j$$$, the $$$L_j$$$ should be at most $$$R_i - (T_j - T_i)$$$
- When $$$T_i \geq T_j$$$, the $$$R_i$$$ should be at least $$$L_j - (T_i - T_j)$$$
And the cost of vertex $$$i$$$ is exactly $$$C_i$$$. The answer is the minimum sum of vertex cost from any vertex of $$$L_i = 0$$$ to any vertex of $$$R_j = 0$$$. Using Dijkstra's Algorithm, we can calculate in $$$O(M^2)$$$. That's worth 35 points so far.However, we can improve it finally to time complexity $$$O(M \log M)$$$.
Next, how to improve this time complexity? Actually, we only have to improve Dijkstra's Algorithm. When we define the cost of edge $$$i \Rightarrow j$$$ be $$$C_j$$$, all vertices going to one vertex has the same cost. So, when there are $$$k$$$ edges going from $$$v_1, v_2, ..., v_k$$$ to vertex $$$i$$$, the the edge which has earliest $$$dist(v_j)$$$ only contributes to $$$dist(i)$$$.
So, for each iteration in Dijkstra's Algorithm, when the vertex $$$i$$$ has popped out from priority queue, we only have to enumerate all "remaining" vertex (which means currently $$$dist(k) = \infty$$$) going from vertex $$$i$$$, and determine $$$dist(k)$$$ for all $$$k$$$.
We can change the preceding condition of which exists edge from $$$i$$$ to $$$j$$$.
- Condition Type #1: $$$T_j \geq T_i$$$ and $$$(L_j + T_j) \leq (R_i + T_i)$$$
- Condition Type #2: $$$T_j \leq T_i$$$ and $$$(L_j - T_j) \leq (R_i - T_i)$$$
Now, $$$i$$$ and $$$j$$$ became independent. Now, we can reduce problem of 2D points and process the queries like "enumerate all points in rectangular range and erase them all". This can be done by std::set on segment tree, and the entire process is $$$O(M \log^2 M)$$$. We can also improve it to $$$O(M \log M)$$$.Great solution!
Will editorial be published (even in Japanese)?
Hello Everyone!
I made a mirror contest on AtCoder. I got contact with the committee and was allowed to use real graders, which means that you can know real score of Stray Cat (Day3-3).
I hope many people use it!
https://atcoder.jp/contests/joisc2020?lang=en
When will be the test data of day 4 open?
Important Information
IOI 2020 Japan Team is now selected.
Source: Link1, Link2
Hope IOI 2020 will not be cancelled.
(Note: All four participants shares his results on twitter.)
Congratulations!
Hi ojuz, I think your testcases arent strong enough for Capital City.
https://oj.uz/submission/943508 This passed despite giving the wrong output on this input:
The correct answer should be
2but instead it outputs1.